Recurrent Neural Network(RNN)#
RNN 是一类专为序列数据设计的神经网络,引入了循环连接,让网络在处理当前输入时,能够携带之前步骤的信息
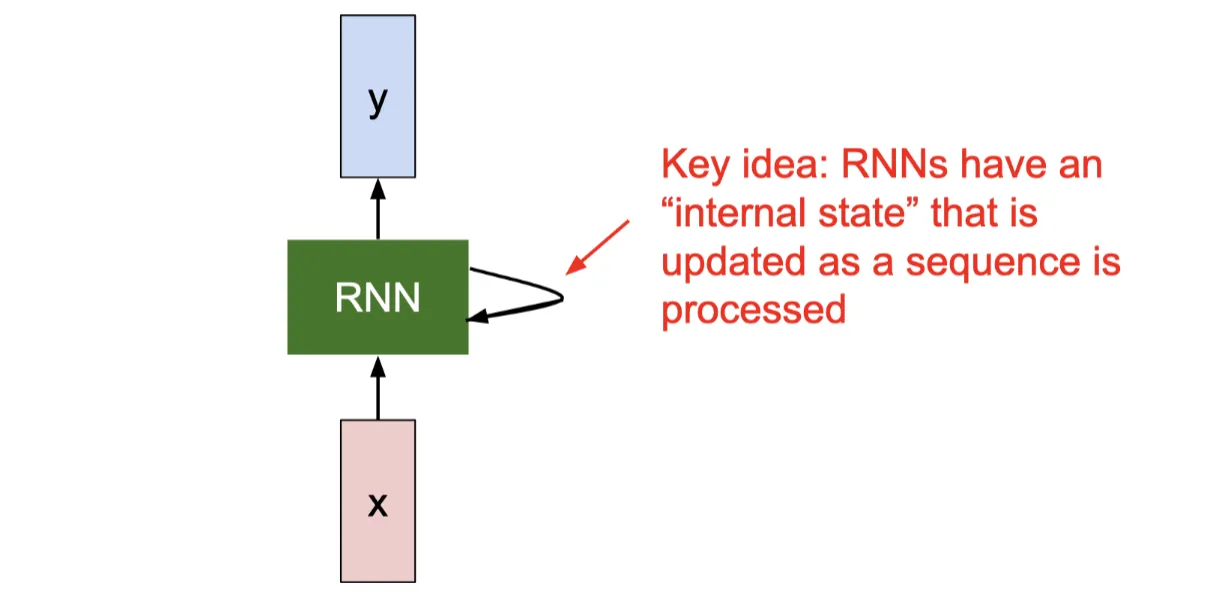
其内部函数可以描述为:
ht=fW(ht−1,xt)yt=gW(ht)
其中 ht 是当前时间步的隐藏状态,ht−1 是前一个时间步的隐藏状态,xt 是当前输入,fW 和 gWy 是参数为 W 和 Wy 的非线性函数,yt 是当前时间步的输出
RNN 展开后的结构如下图所示:
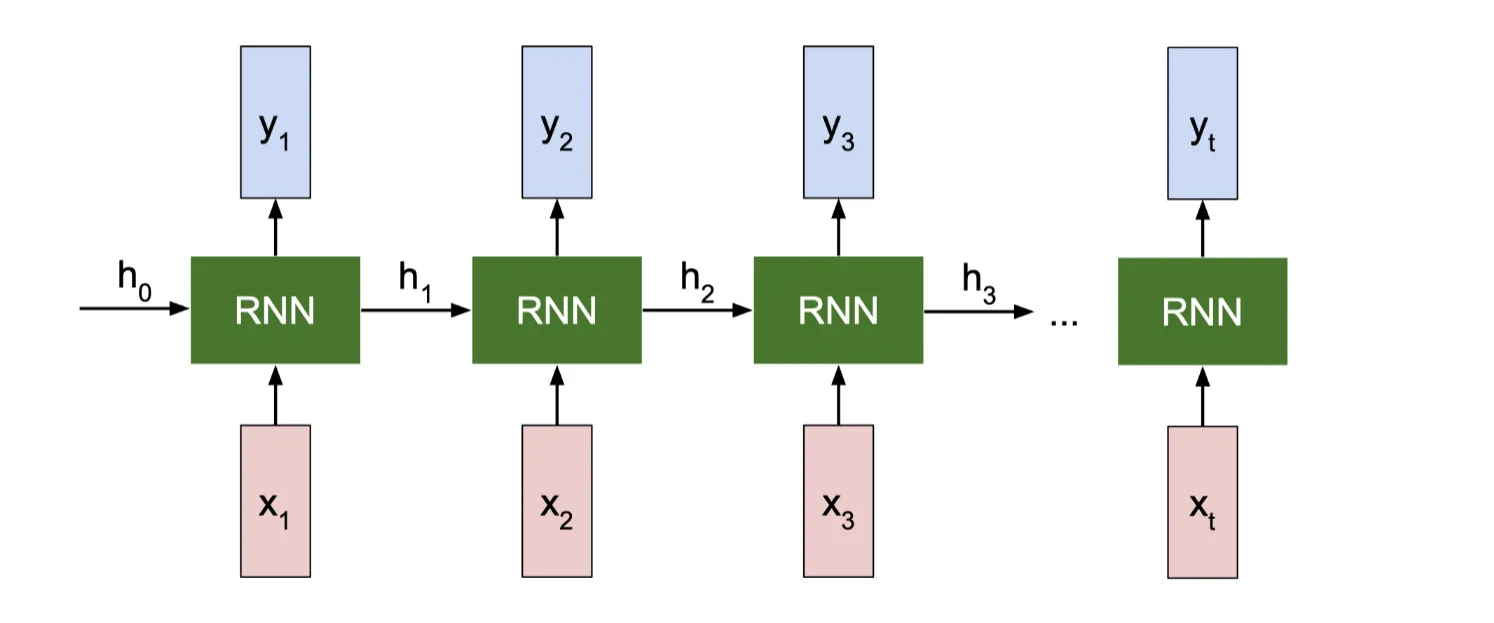
初始状态 h0 可以是一个全零向量
Vanilla RNN#
最初始的 RNN
ht=tanh(Whhht−1+Wxhxt+bh)yt=Whyht+by
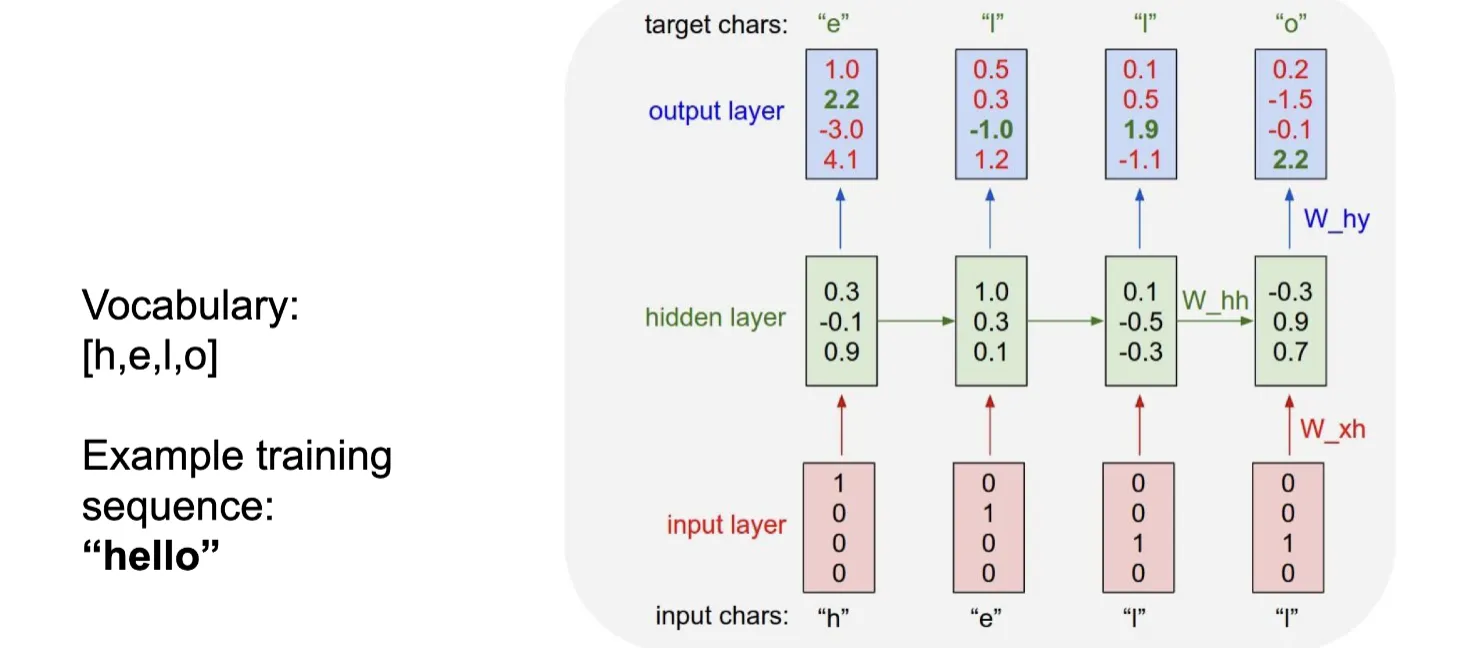
最简单的一个字母级预测模型,每次预测一个字母
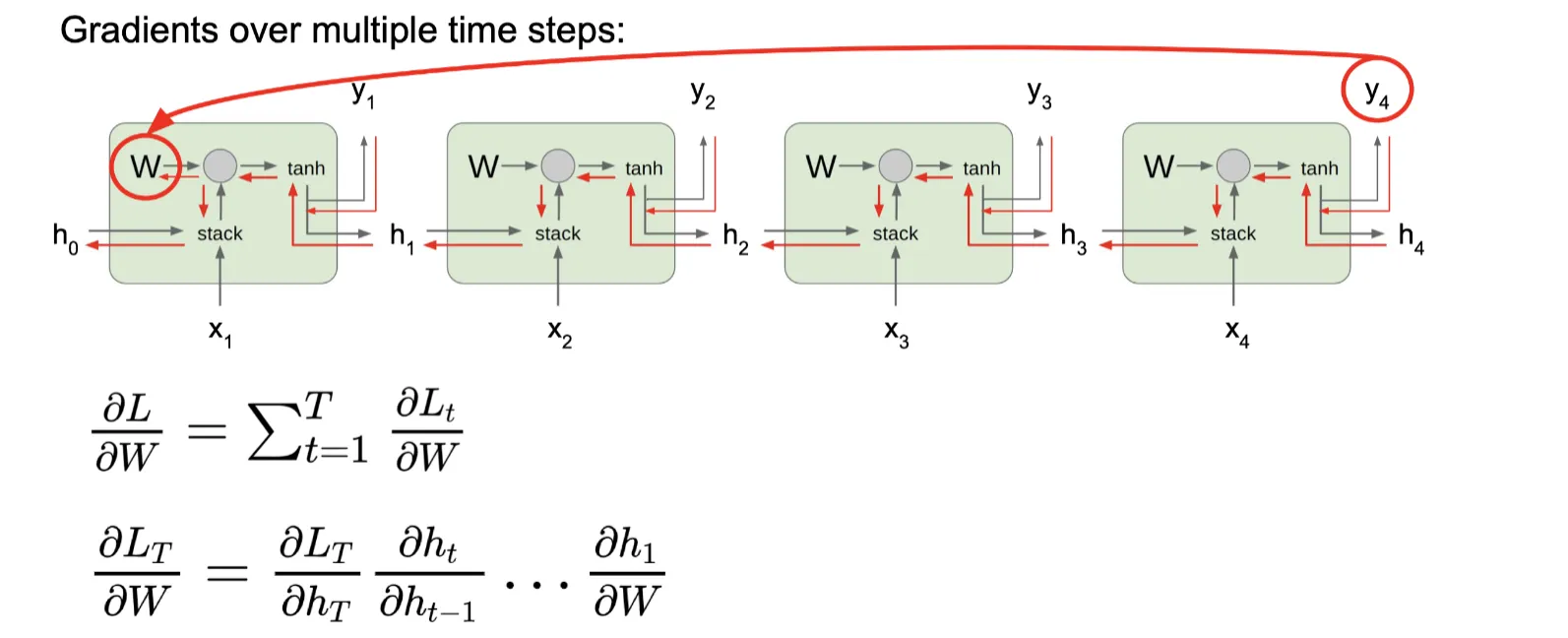
图中红色箭头为反向传播的路径,图中如果h4是最后一步则不会有来自后面的梯度
对于输出层,每个输出可以计算一个loss,应用于当前步的反向传播和Why的权重更新。每一步都会计算出一个对于权重矩阵W(或者说Whh和Wxh)的梯度,这些梯度会累加,在最后对W进行更新
可以看到在反向传播过程中,靠前的时间步需要计算更多次的梯度乘积
解决方法:Truncated BP,太长的序列只反向传播有限的时间步
我们使用RNN进行文本生成时,对于每一步输出的向量,我们可以通过softmax函数将其转换为概率分布,然后根据这个概率分布来选择输出的token
Sample Strategy:输出时如何选取合适的token
- Greedy sampling:每次选择概率最高的token作为输出
- Weighted sampling:根据概率分布随机选择token作为输出
- Beam search ↗:每次选择概率最高的k个token作为输出,以此为基础继续扩展
- Exhaustive Search:枚举所有可能的输出序列,从中选择概率最高的完整序列(复杂度太高)
P(y∣x)=t=1∏TP(yt∣y<t,x)
梯度消失问题:由于距离较远的梯度信号比距离较近的梯度信号小得多,因此发生了丢失,模型的权重只针对近效应进行更新,而不是长期效应。
因此理论上 RNN 的 context 是无限长的,但实际上根本学不出来
RNN 优点:
- 可以处理任何长度的输入
- 步骤 t 的计算(理论上)可以使用许多步之前的信息
- 模型大小不会因输入更长而增加
- 在每个时间步上应用相同的权重,因此输入处理方式是等变的
RNN 缺点:
Long-Short Term Memory(LSTM)#
改变 RNN 的结构来一定程度上解决梯度消失问题
回顾 Vanilla RNN 的计算公式:
ht=tanh(Whhht−1+Wxhxt+bh)
tanh求导后小于1,因此在反向传播过程中,梯度会不断乘以一个小于1的数,导致梯度逐渐变小,最终消失。我们认为这里保存的是短期记忆,所以很容易忘掉;需要一种能保存长期记忆的机制
LSTM 引入了一个新的状态 ct,称为细胞状态(cell state),它可以看作是一个长期记忆的载体,引入门控机制来控制信息的流动:
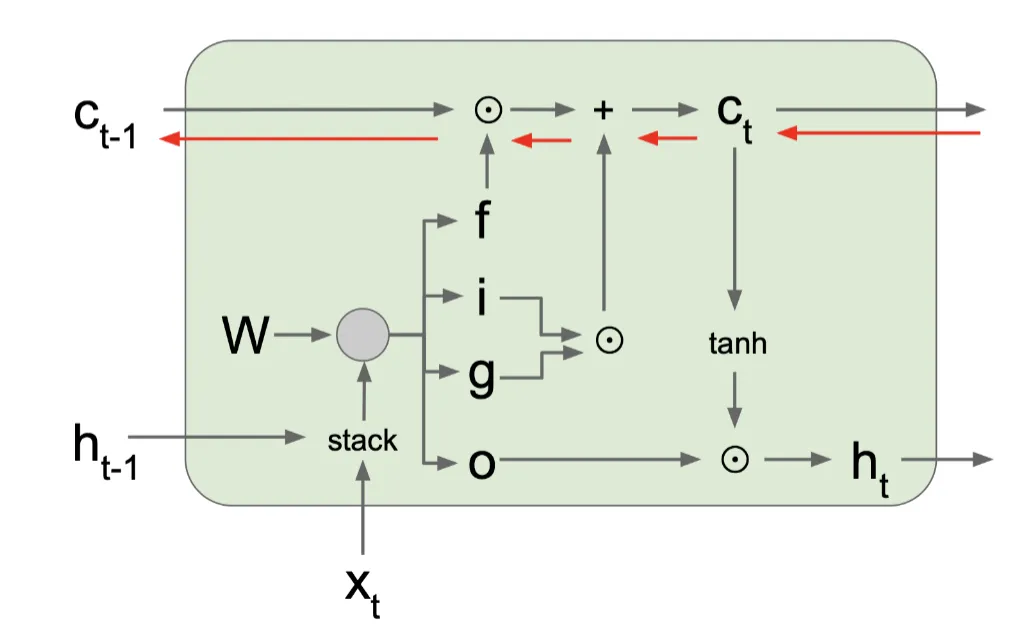
LSTM 的计算公式如下:
itftotgtctht=σ(Whiht−1+Wxixt+bi)=σ(Whfht−1+Wxfxt+bf)=σ(Whoht−1+Wxoxt+bo)=tanh(Whght−1+Wxgxt+bg)=ft⊙ct−1+it⊙gt=ot⊙tanh(ct)
- i: Input gate, Whether to write to cell
- f: Forget gate. Whether to erase cell
- o: Output gate, How much to reveal cell
- g: Gate gate (?), How much to write to cell
LSTM 也不能完全解决梯度消失问题,但其类似于 skip link 的结构很好的缓解了这个问题
Image Caption using RNN#
用RNN来解释图像的内容,生成描述性的文本。一个简单的做法就是CNN后面接一个RNN,CNN负责提取图像特征,RNN负责生成文本描述
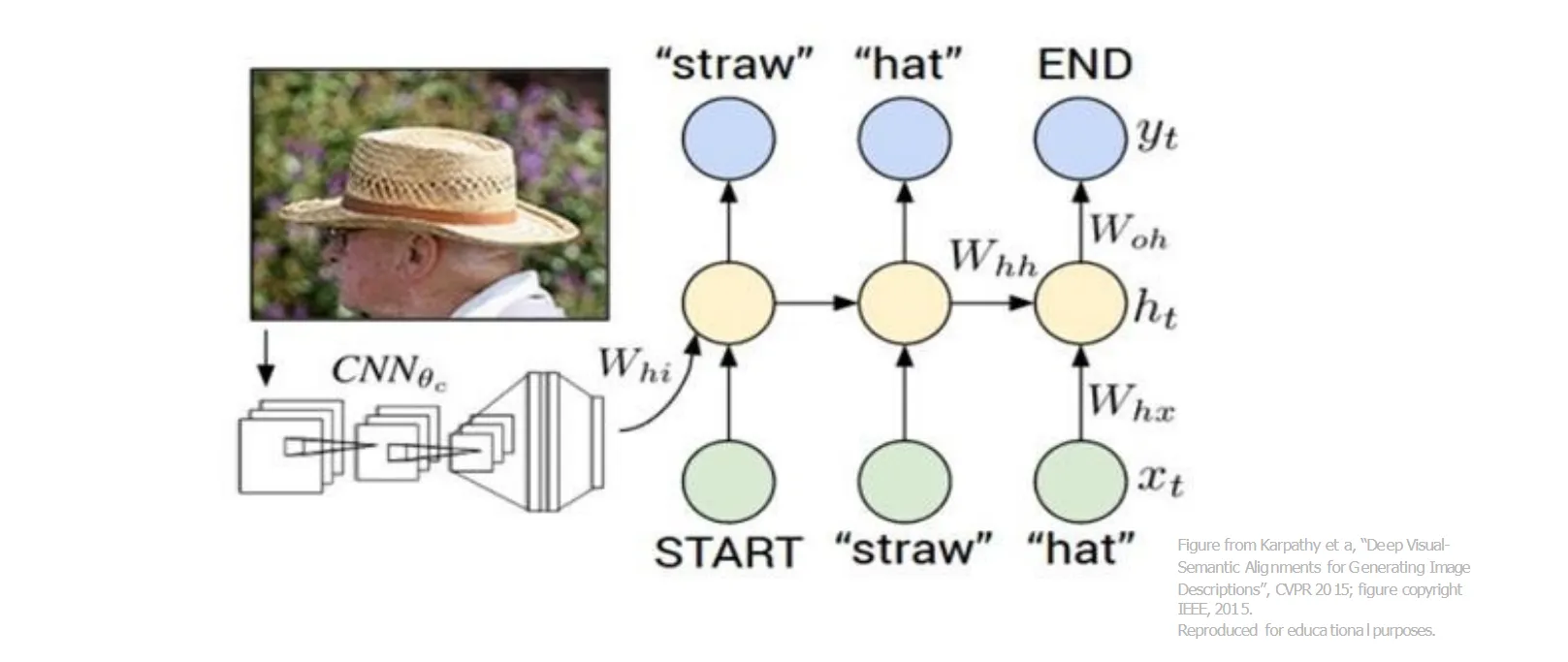
对于CNN,我们不需要它在最后生成每种分类的概率,而应该在前面截断。(比如一个1000分类的CNN,最后的FC层是4096 -> 1000,我们不需要这个1000分类的输出,而是需要4096维的特征向量)
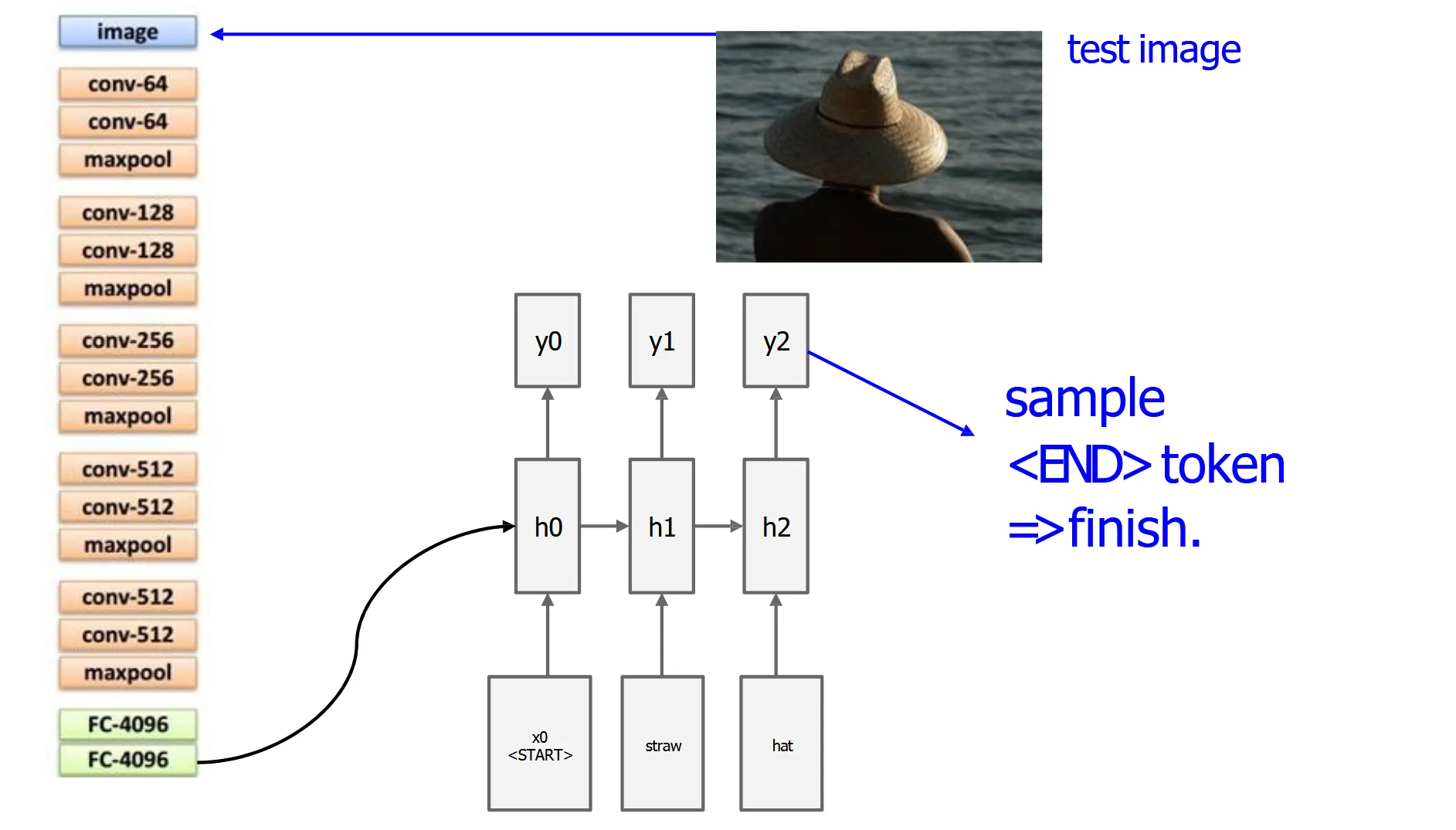
接下来把这个特征向量过一个矩阵,转化为 RNN 的输入维度,然后 RNN 就可以开始生成文本了
bvht=Whi(CNNθ(I))=f(Whxxt+Whhht−1+bh+1(t=1)⊙bv)