区别于2维图像,三维物体可以有很多表现形式,比如多视角的图像、点云、深度图、体素、网格等,这取决于我们如何获取这些数据和我们研究问题的需求
Depth Images#
深度图中每个点的值表示其与相机的距离。它是一种2.5D表示,因为它不能提供3D中任意两点的距离信息(需要内参矩阵K)
Backprojection#
给定图片中一个pixel的坐标,我们可以通过内参矩阵K将其反投影到3D空间中:
已知:
我们可以反解出:
这样我们就可以将深度图转换成一个点云表示
Depth Sensors#
我们可以通过不同的传感器来获取深度图,一种常见的深度传感器是stereo sensor,它通过两个相机捕捉同一场景的图像,并通过比较两张图像中对应点的位移(视差)来计算深度信息
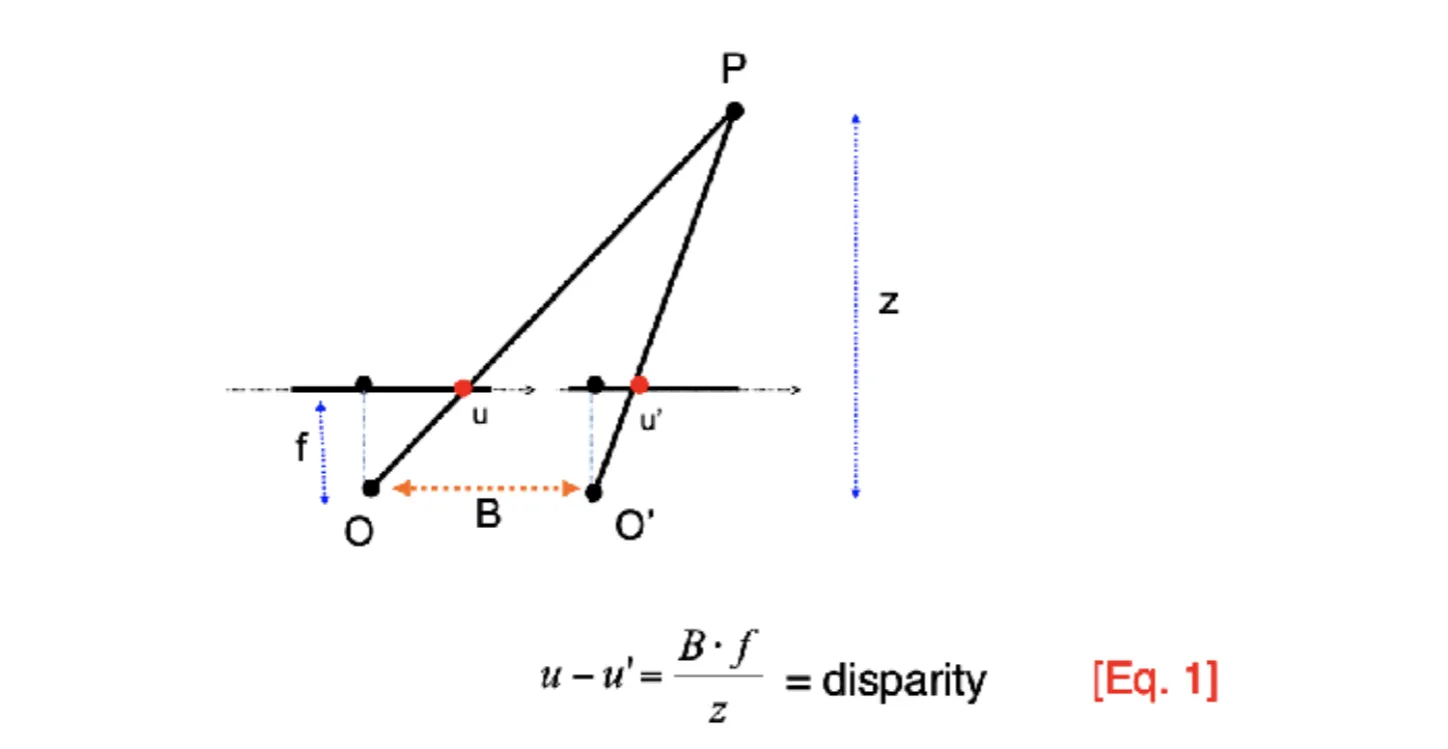
和分别是两个相机的光心,是焦距,是两个相机之间的基线距离,是视差,即同名点的水平像素差。根据三角形相似,可以得到上面的公式
由于两个相机水平差距,我们只能计算重合部分的深度信息,因此在一些场景中可能会有盲区
stero sensor比较依赖场景纹理,对于一些场景难以得到准确的信息
一种改进叫做Active Stereo,它不是被动的接受光线,而是主动发出结构化光,另外的相机利用观测到的这些光的一些先验信息来计算深度
Mesh#
Mesh(网格)是一种由顶点、边和面组成的分段线性表面近似,将物体表面平滑的曲面用离散的平面来表示。最常见的网格是三角网格
关于Mesh的存储,可以使用下面两个列表
- 顶点列表:存储每个顶点的坐标
- 面列表:存储每个面由哪些顶点组成
Point Cloud#
点云是一群从物体上采样出的三维空间中的点,是一种简单的3D表示方法。每个点通常包含位置坐标(x, y, z)和可能的其他属性(如颜色等)
点云不能体现表面的位置,因为不知道哪些点可以连接起来
Sampling Strategy#
如何从表面信息(比如Mesh)中采样出点云呢?有两种常见的策略:
Uniform Sampling:
采样的点云依赖于每个表面的面积大小,面积越大的表面应该采样更多
步骤:
- 计算每个surface的面积和总面积
- 根据每个surface的面积占总面积的比例作为权重,根据权重来分配采样点的数量
- 在每个surface上均匀采样点
一种在三角形中均匀采样的方法:(假设三角形的三个顶点为)
- 生成两个均匀分布在间的随机数和
- ,通过这样可以在平行四边形内均匀采样点
- 如果,则将和替换为和,这样可以将点映射到三角形内
这样取样之后, 在取样量不算非常大的时候, 经常会出现不太均匀的情形
Farthest Point Sampling(FPS):
我们想要选取个点使其两两距离求和最大,但这个问题是NP-hard的,因此我们使用一个近似的贪心算法来实现:
步骤:
- 从点云中随机选择一个点作为初始点
- 计算所有未选择点到所有已选择点的最小距离,选择距离最远的点加入已选择点集合
- 重复上述步骤直到达到所需的采样数量
这样实际上更均匀
Metric#
我们可以定义一些距离度量来衡量两个点云之间的相似性:
- Chamfer Distance(CD):对于点云和,计算每个点云中每个点到另一个点云的最近距离的和,再把两个结果相加
- Earth Mover’s Distance (EMD):计算将一个点云变换成另一个点云所需的最小工作量,工作量定义为点之间的距离乘以点的权重
其中是一个双射函数,将中的每个点映射到中的一个点
CD 对于采样不敏感,而EMD对于采样非常敏感
Implicit Field#
与前面的显式表示(如Mesh和点云)不同,隐式场不会显式去表示空间结构,而是用函数来定义一个空间
SDF#
Signed Distance Function (SDF) 是一种隐式场表示方法,它定义了一个函数,它具有下面这些特性:
- 内部点:
- 表面点:
- 外部点:
- 的绝对值表示点到表面的距离
SDF to Mesh#
我们可以使用Marching Cubes算法将SDF转换成Mesh。该算法的基本思想是将空间划分成一个个小立方体,然后根据每个立方体的个顶点的SDF值来确定该立方体与表面的交点位置,从而生成三角形网格
这里我们先看一个2D的例子:
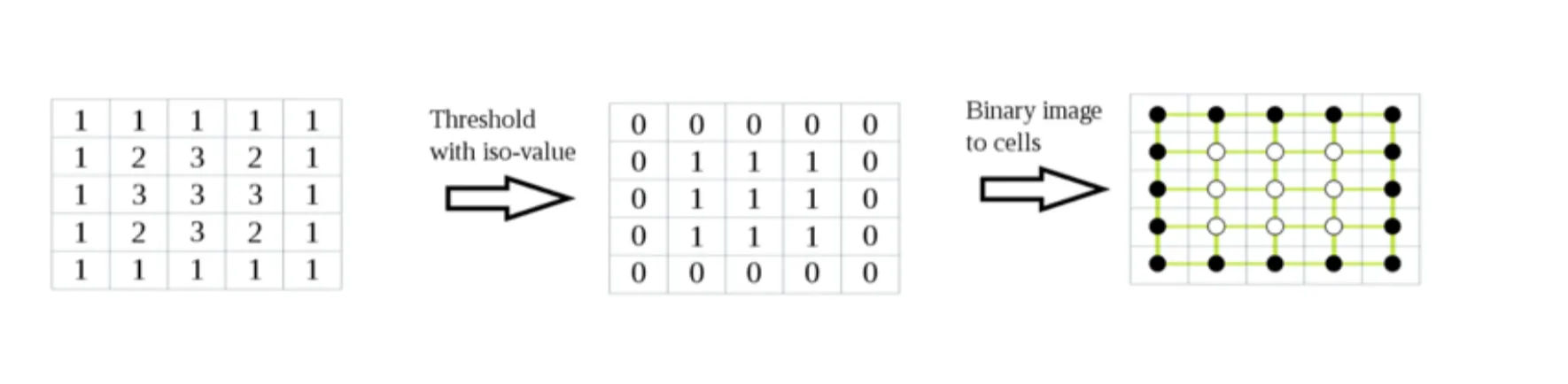
我们先将SDF离散化,在每个像素点上计算处其SDF值。然后根据表面的定义进行二值化(这里认为是表面),大于这个值的置为,小于这个值的置为,这样我们就得到了一个二值图像
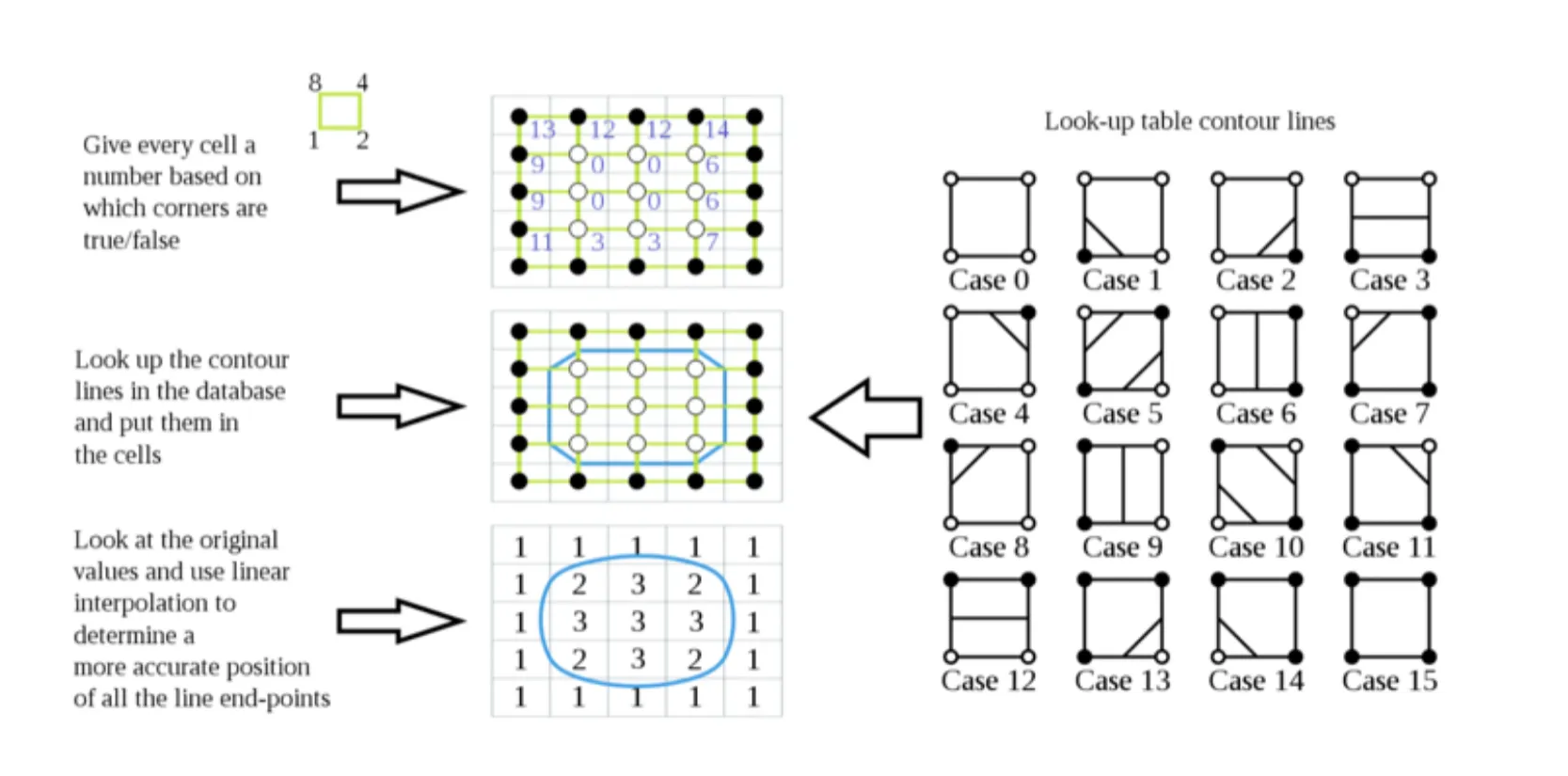
对于一个正方形网格,根据其四个顶点的二值化结果,我们可以将其分成种情况(每个顶点有两种状态,),每种情况对应一个特定的边界划分
那么我们只需要根据每个网格的情况来查找对应的边界划分表格,就可以生成一个近似的表面
查找表的边界只是简单的二分,对于一些交界处(比如和),边界()可能并不落在中央,因此需要进行线性插值进行微调,来更准确地确定边界位置
在划分查找表时,会有一些ambiguity的情况
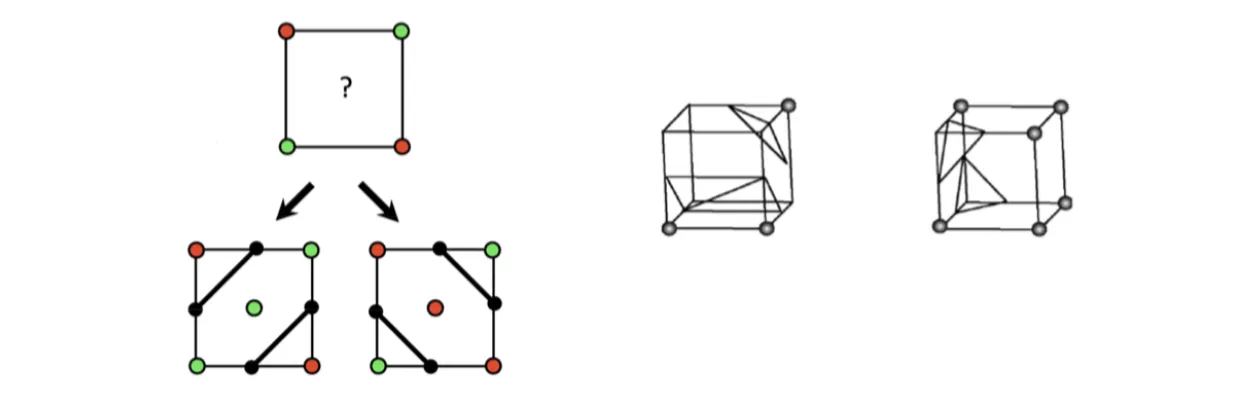
对于上图的情况,由于不知道中间点的情况,所以可能有两种划分方式;对于三维的情况,可能会有更多的ambiguity情况
目前的一种解决方案是拓展查找表,通过看周围的网格的情况来确定如何选取
Deep SDF#
这些隐式函数应该如何表示,对于简单的几何体,我们或许可以用一些解析函数来表示,但对于复杂的物体,我们需要更强大的函数表示能力,这时我们可以使用神经网络来学习隐式函数
3D Deep Learning#
三维信息处理有两种基本的方向:
- 把处理二维信息的方法进行改进,使其可用于三维数据
- 把三维数据投影到二维空间中,利用二维方法进行处理
PointNet#
对于点云数据,我们要设计处理它的神经网络,需要满足shuffle invariance(点云的顺序不应该影响结果)
因此,使用FC或者简单拉成1D向量做卷积都不合适
一个满足shuffle invariance的想法是使用对称函数,即输出不随输入顺序改变而改变的函数,比如max或者average。下面的工作就变成了如何用神经网络来构造对称函数
PointNet依赖于一个结论:是对称函数,当是一个对称函数
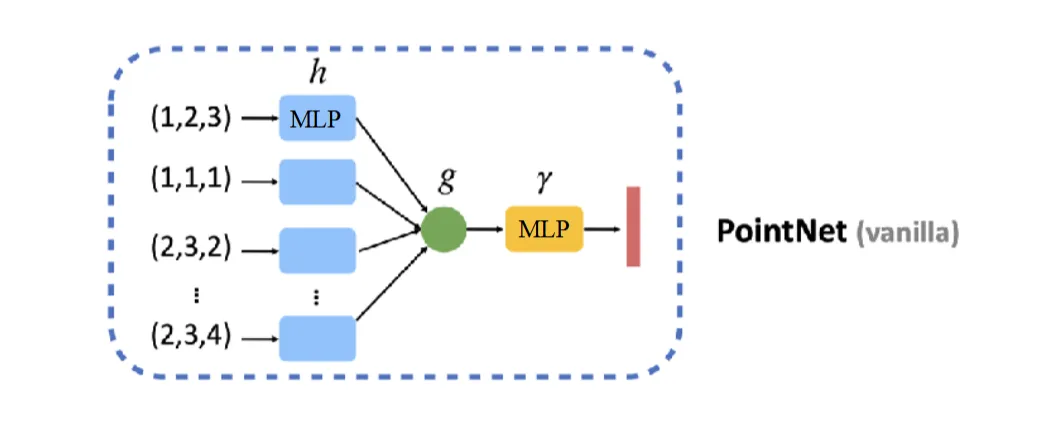
把和都用MLP来实现,这就是PointNet的基本结构
PointNet++#
回顾 PointNet ,其相当于对每个点做一个 1x1 的卷积,再通过Max Pooling 来聚合全局特征。它的感知面积一下从1 pixel 扩大到整个点云,导致它无法捕捉局部结构信息
一个自然的想法是提取每个局部的特征,最后从局部特征获取全局特征
PointNet++ 的做法是,先把点云划分成几个局部区域,然后在每个局部区域使用 PointNet 来提取特征,最后再把这些局部特征聚合成全局特征
划分区域的方法有两种:
- KNN:对于每个点,找到它的 K 个最近邻点,组成一个局部区域(区域大小不定)
- Ball Query:对于每个点,找到距离它在某个半径范围内的点,组成一个局部区域(区域内点数目不定,可以设定一个所需点数k,如果大于就随机选k个,如果小于就复制一些点)
注意的是,这些局部区域共享权重,也就是说在每个局部区域使用同一个 PointNet 来提取特征
由于坐标是在统一的世界坐标下,不同区域的坐标会有很大的偏移。为了抹除不同局部区域之间的坐标差异,PointNet++ 在每个局部区域内对点的坐标进行中心化处理,即减去该局部区域中心点的坐标
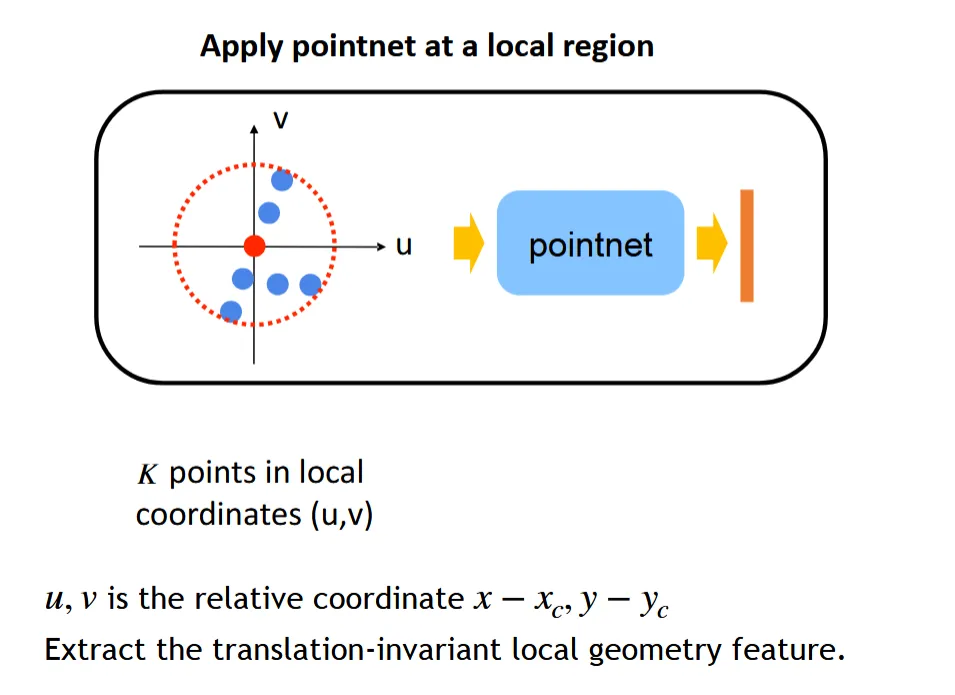
经过 PointNet 提取后的特征,还会连接上局部区域中心点的坐标信息(即图中F),以便后续的特征聚合能够利用位置信息
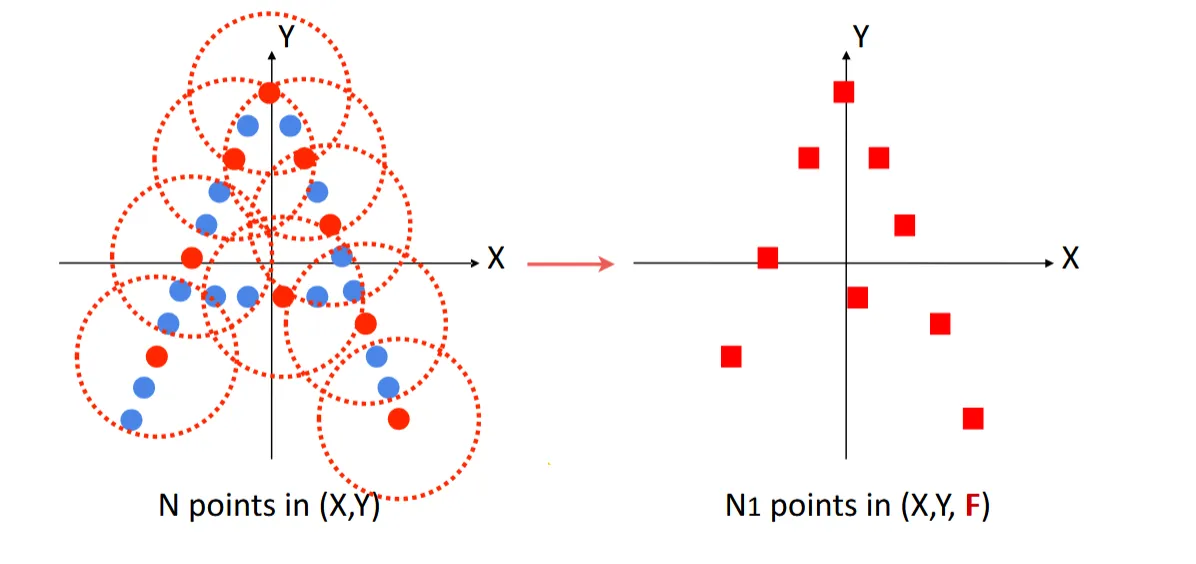
这种步骤可以反复做,不断减少点的数量,直到最后得到一个全局特征向量,然后可以据此来连接 FC 层进行分类任务
如果要做分割任务,还需要考虑如何进行上采样(Upsampling),即如何把全局特征向量还原回每个点的特征
PointNet++ 直接使用类似skip link的方式,获取同一层下采样的点的位置作为上采样点的位置;对于特征,每个新的点选取距离最近的三个点,按照距离反比为权重做插值来获取特征
Voxel Networks#
前面的 PointNet 直接对点云进行处理,Voxel Network 的处理对象是体素,其想法也非常简单,直接在体素上使用 3D 卷积来提取特征(4D的卷积核)
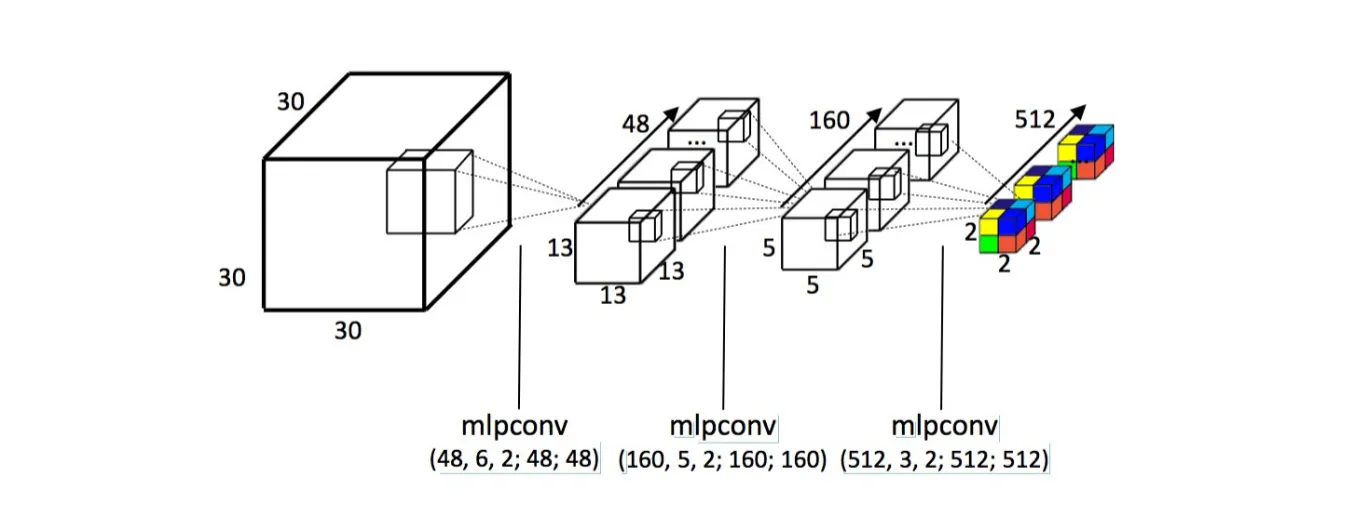
但这种方法很昂贵,因为体素化会导致数据量的爆炸,尤其是当点云比较稀疏时,大部分体素都是空的,这就造成了计算资源的浪费
利用体素的稀疏性,可以使用稀疏卷积来减少计算量
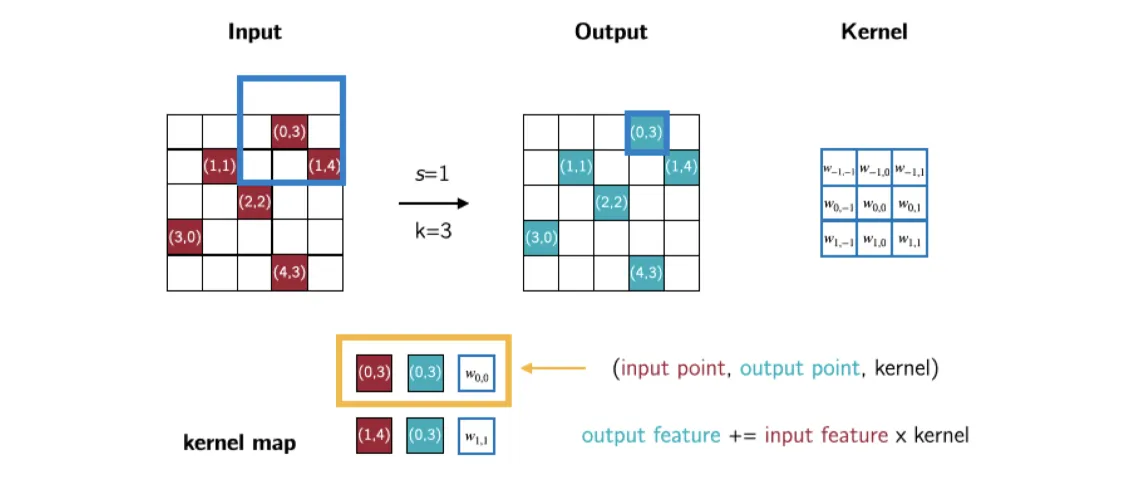 图中的红色方块表示非零值的位置,卷积核的大小为,只有当卷积核的中心对准输入特征图的非零值时, 才会计算输出值
图中的红色方块表示非零值的位置,卷积核的大小为,只有当卷积核的中心对准输入特征图的非零值时, 才会计算输出值
比如当卷积核的中心对准输入特征图的 位置时,计算输出图的 位置的值: