Attention#
在处理可变长序列信息时,Sequence to Sequence 模型(Seq2Seq)是一种通用的架构,它通过编码器——解码器结构,解决了传统神经网络只能处理固定长度输入的问题。编码器将输入序列转换为一个固定长度的上下文向量,解码器则根据这个上下文向量生成输出序列
Seq2Seq with RNNs#
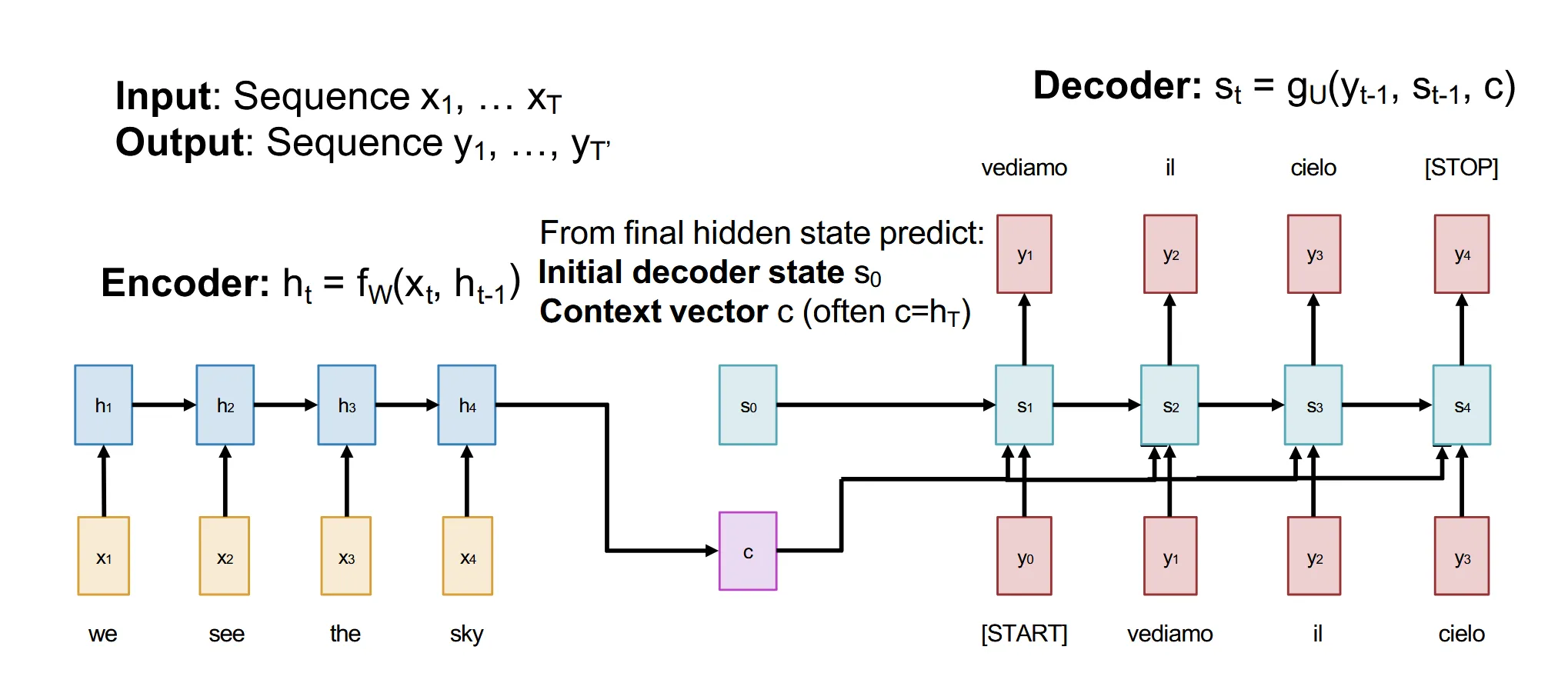
使用RNN分别作为Encoder和Decoder,把最后一个时刻的隐藏状态作为上下文向量,传递给Decoder来生成输出序列。右边RNN采用的是teacher forcing的方式,训练时输入正确的标签,测试时输入前一个时刻的预测结果
问题:当输入序列很长时,最后一个时刻的隐藏状态可能无法捕捉到输入序列的全部信息,导致生成的输出质量下降
Seq2Seq with RNN and Attention#
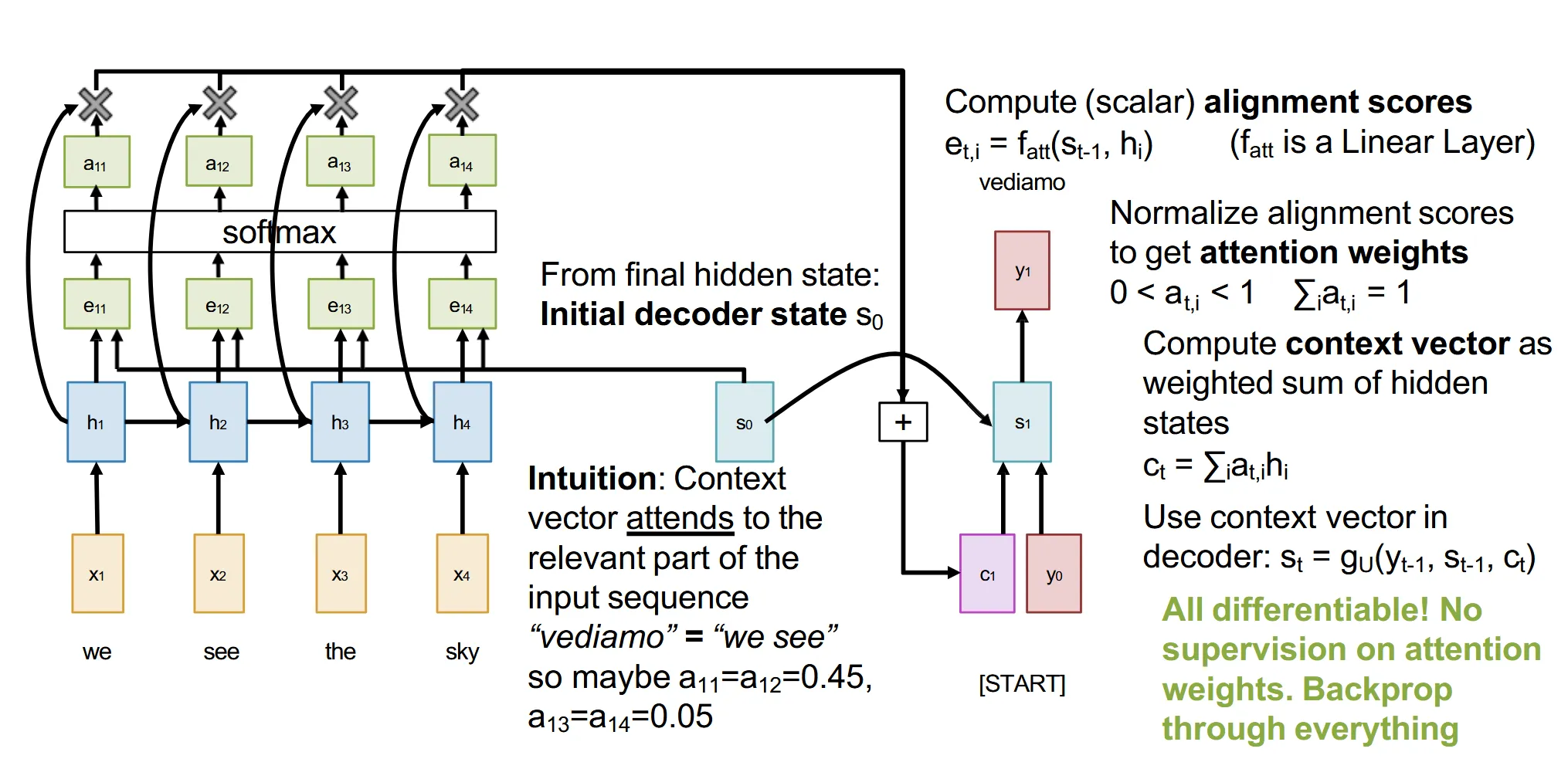
Attention本质上是想要在Decoder的每个时刻,都能看到Encoder的所有状态,并根据当前状态学到一个权重分布,来加权求和得到一个上下文向量,这样就能更好地捕捉输入序列的信息
具体步骤:(以Decoder的初始状态s0为例)
- 对于encoder的每个隐藏状态hi,对s0和hi经过一个线性层,得到一个分数ei
ei=fatt(s0,hi)
- 对这些分数进行softmax,得到权重分布αi
- 使用权重分布对encoder的隐藏状态进行加权求和,得到上下文向量c
c=i∑αihi
- 利用c、当前输入y0和当前的Decoder状态s0来生成输出
之后就用下一个时刻的Decoder状态s1来重复这个过程,直到生成完整的输出序列
对于s,可以称它为query vector;对于h,我们称它为data vector;对于c,我们称它为output vector
我们记:
Query vectorData vectorsSimilaritiesAttention weightsOutput vector:q [DQ]:X [NX×DX]:e [NX],ei=fatt(q,Xi):a=softmax(e) [NX]:y=∑aiXi [DX]
因为要计算每个data vector和query vector的相似度,可以简化为用dot product来计算。此时我们需要调整query vector和data vector的维度,使它们相同(比如都调整为DX维)
注意到后面还需要计算softmax,所以我们可以在dot product的基础上除以DX,来防止数值过大导致softmax梯度消失
ei=DXqTXi
在计算Similarities和Output时,分别在X上乘WK和WV,来得到Key和Value矩阵
eiy=DXqTK=∑aiVi
最终的Attention机制可以表示为:
Attention(q,K,V)=softmax(DXqTK)V
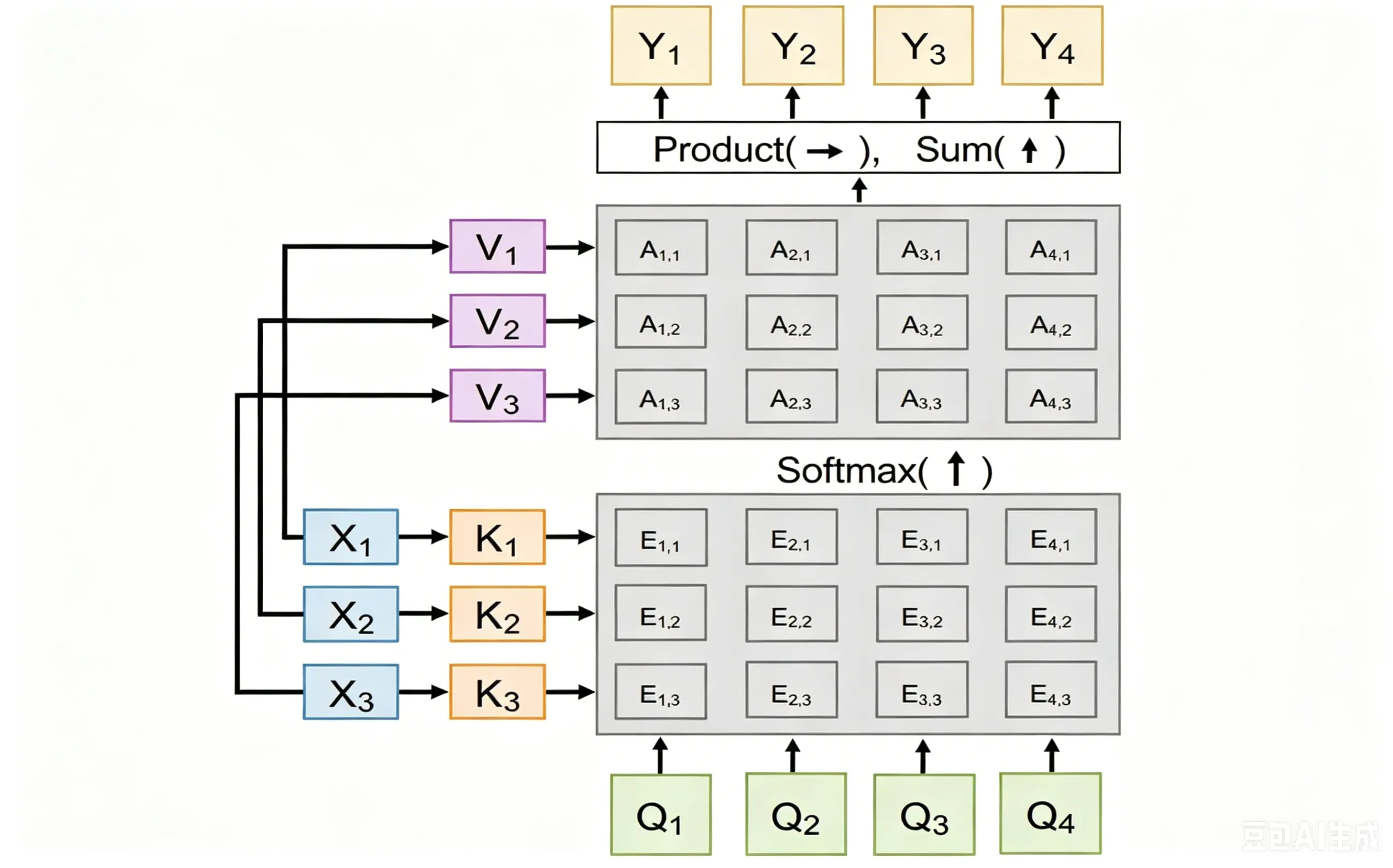
Self-Attention#
前面的Attention机制是跨序列的(cross-attention),query来自Decoder,data vector来自Encoder;而Self-Attention是指query、key、value都来自同一个序列(比如Decoder内部),这样每个位置都可以看到序列中所有其他位置的信息
在Self-attention中,Query、Key、Value都是从同一个输入序列通过不同的线性变换得到的
QKV=XWQ=XWK=XWV
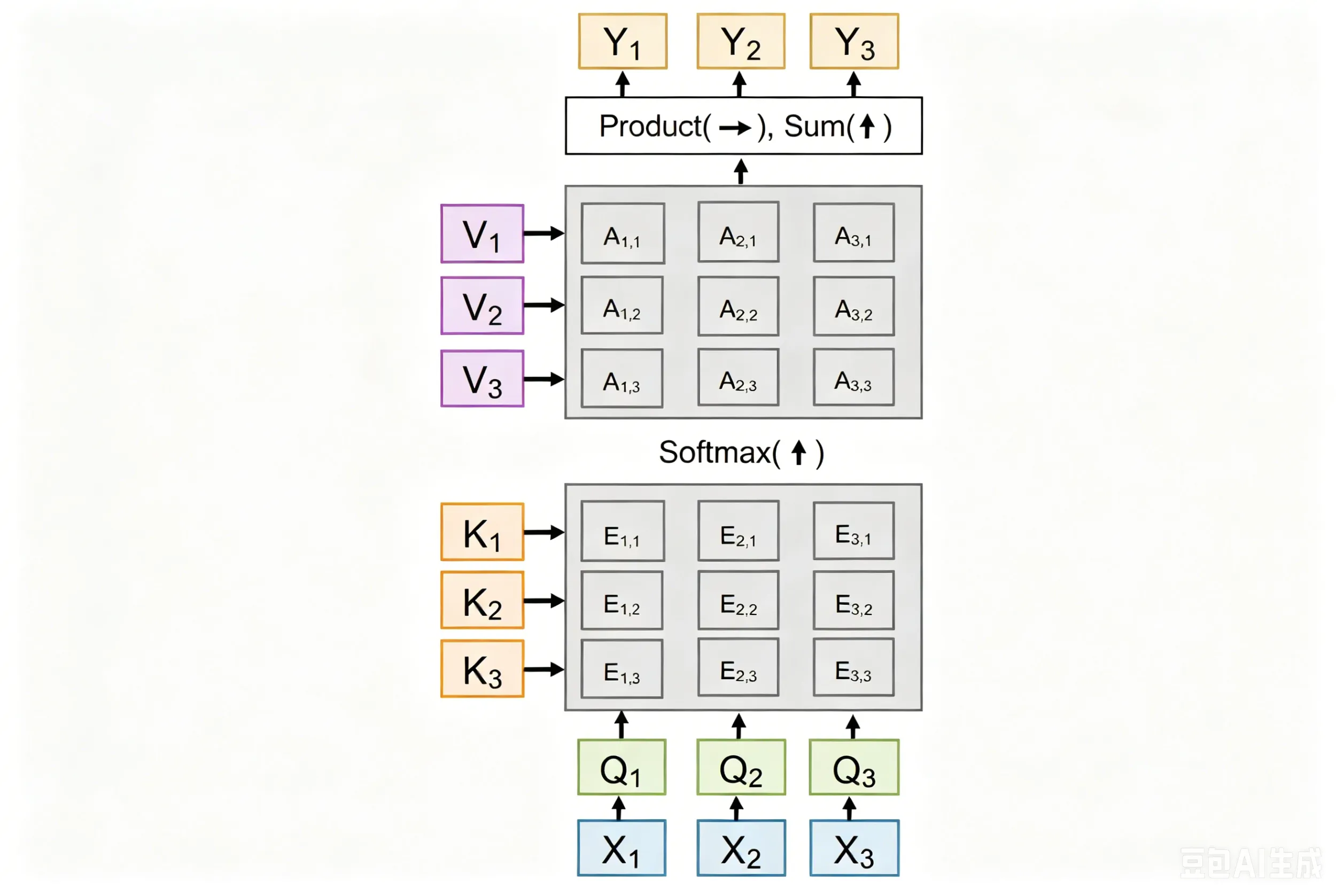
self-attention是permutation equivariant的,也就是说输入序列的顺序不会影响输出结果,只会改变输出的顺序。F(σ(X))=σ(F(X))
纯self-attention无法捕捉序列的位置信息,因此需要引入位置编码(positional encoding)来补充位置信息
Musk#
上图的self-attention是全局的,也就是说每个位置都可以看到序列中其他位置的信息(比如Q1可以看到K2),在生成任务中,当前时刻的输出不应该看到未来时刻的信息,因此需要引入mask来屏蔽掉未来时刻的信息
只需要把Ei,j中未来时刻的部分(j>i)设置为负无穷,这样在softmax之后就会变成0。线性组合时就不会组合到未来时刻的信息了
Multi-Head Attention#
将 Q,K,V 分别投影到 h 个不同的低维空间,各自计算注意力,再拼接:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中每个头:
headi=Attention(QWiQ,KWiK,VWiV)
多个头可以让模型在不同的子空间中学习不同的注意力模式,增强模型的表达能力;同时可以并行计算,GPU友好
Attention计算的四个步骤:
- QKV Projection
[N×D][D×3HDH]→[N×3HDH]
Split and reshape to get Q,K,V each of shape [H×N×DH]
- QK Similarity
[H×N×DH][H×N×DH]→[H×N×N]
- V-Weighting
[H×N×N][H×N×DH]→[H×N×DH]
Reshape to [N×HDH]
- Output Projection
[N×HDH][HDH×D]→[N×D]
其中N是序列长度,D是输入输出的维度,H是头数,DH是每个头的维度(通常DH=D/H)
序列长度N对计算复杂度的影响最大,注意力机制的计算复杂度是O(N2),主要是第2、3步
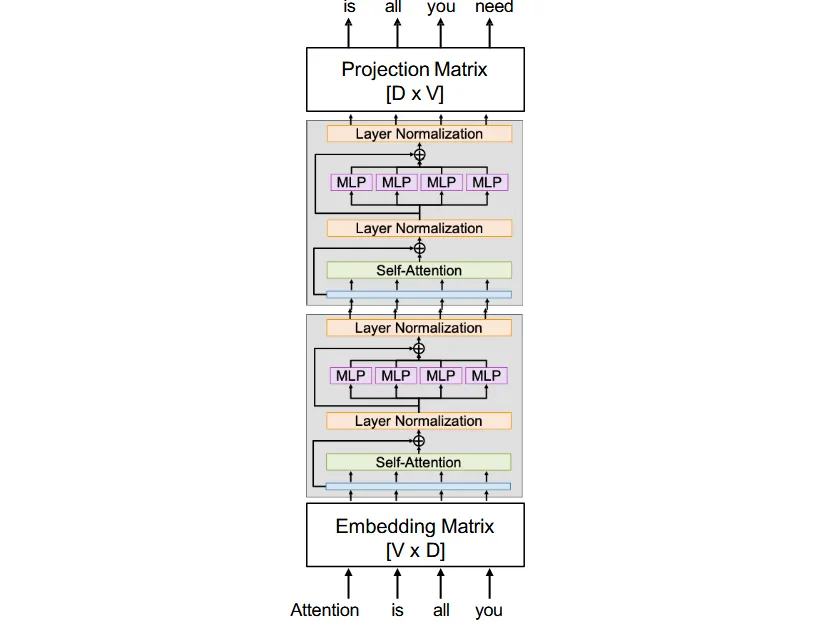 Attention is all you need中的transformer架构
Attention is all you need中的transformer架构
Attention机制本身没有很大的非线性,所以Transformer中每个子层都包含一个前馈网络(图中的MLP),来增强模型的表达能力
后续的Transformer架构有很多变体,这里不提
Transformer处理的是序列化信息,如何把图像变成序列化信息就是核心问题,我们只看最早期的ViT
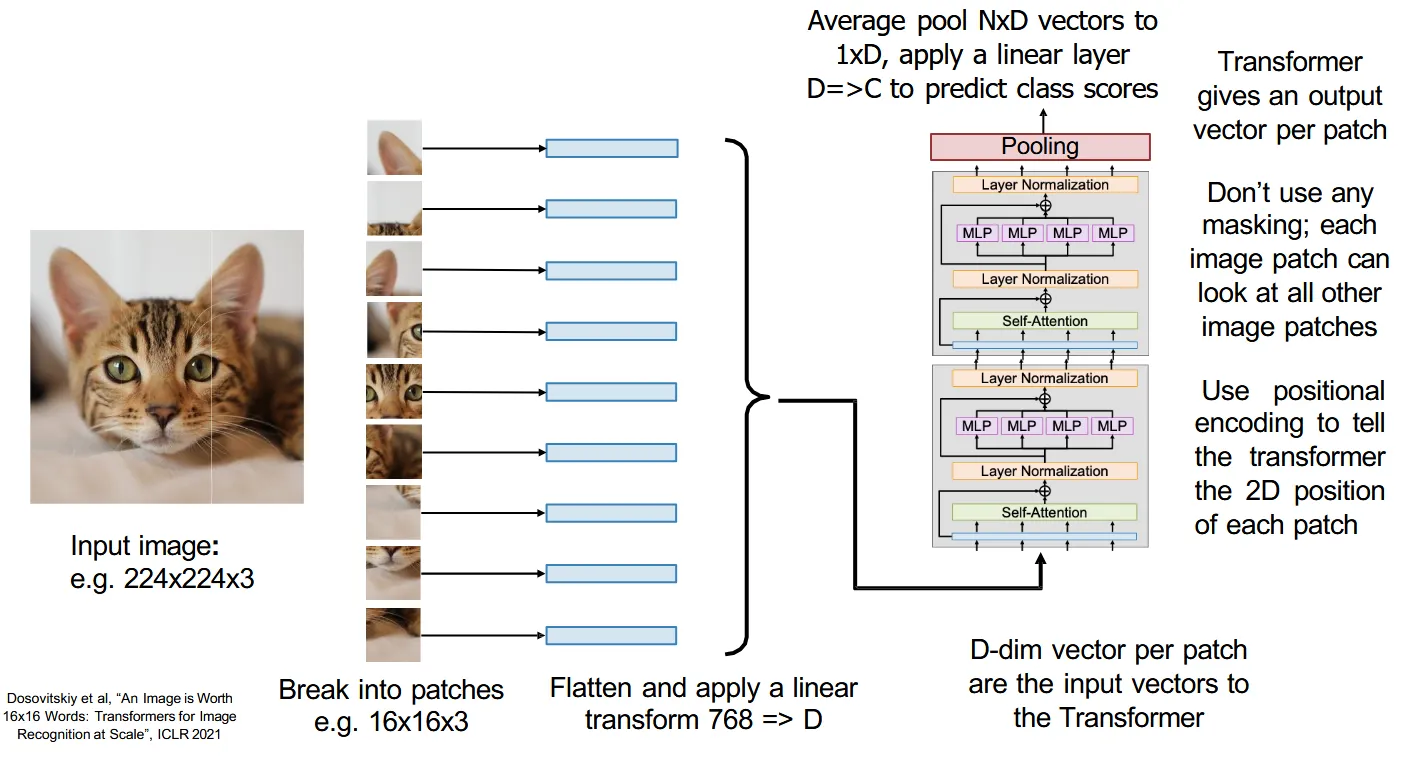
- 把图片分割成16×16的patch,每个patch被展平为一个向量,作为Transformer的输入
- Transformer的结果最后经过一个Average Pooling和一个FC层,来进行分类
问题:
- ViT在图像有微小移动时不稳定(因为Flatten操作)
ViT vs CNN
CNN 的Inductive Bias强于ViT,比如卷积的局部性、平移等变性,而ViT没有这些先验假设,空间信息需要从数据中学习
在数据少时,CNN表现更好;在数据多时,ViT表现更好