CNN#
之前我们介绍了MLP训练以及测试等的流程,但是使用MLP来处理图像数据会有一些问题:我们将图像展平成一个长向量,这样就丢失了图像的空间结构信息。CNN利用卷积的特性来处理图像,避免了展平图像
CNN Overview#
CNN使用卷积层来处理图像,卷积层通过滑动窗口的方式在图像上进行卷积操作。
图像一般会有多个Channel,比如RGB。卷积层filter也会有对应的channel数,将图像上大小的区域卷积成一个数值,形成一个activation map。
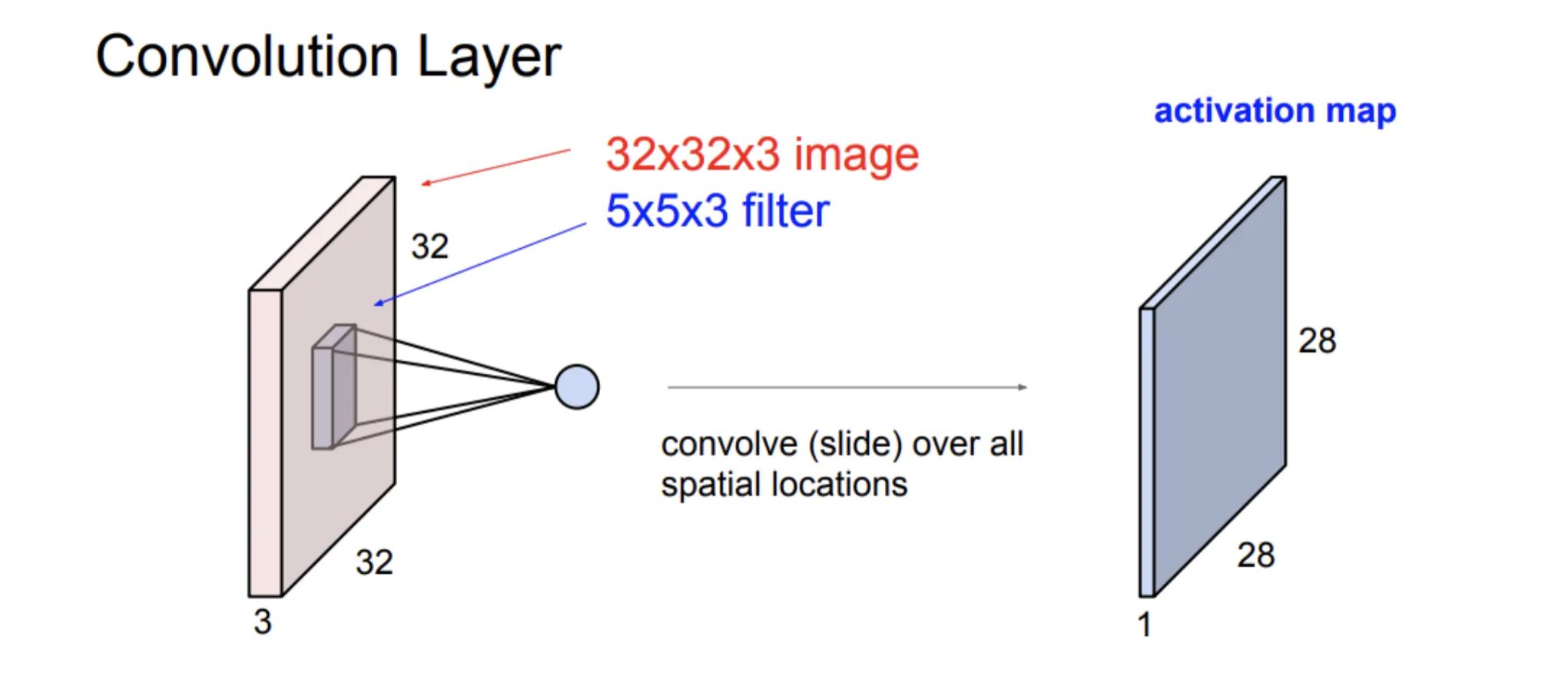
通过重复这种操作,我们可以得到任意channel数的activation map,形成输出图像
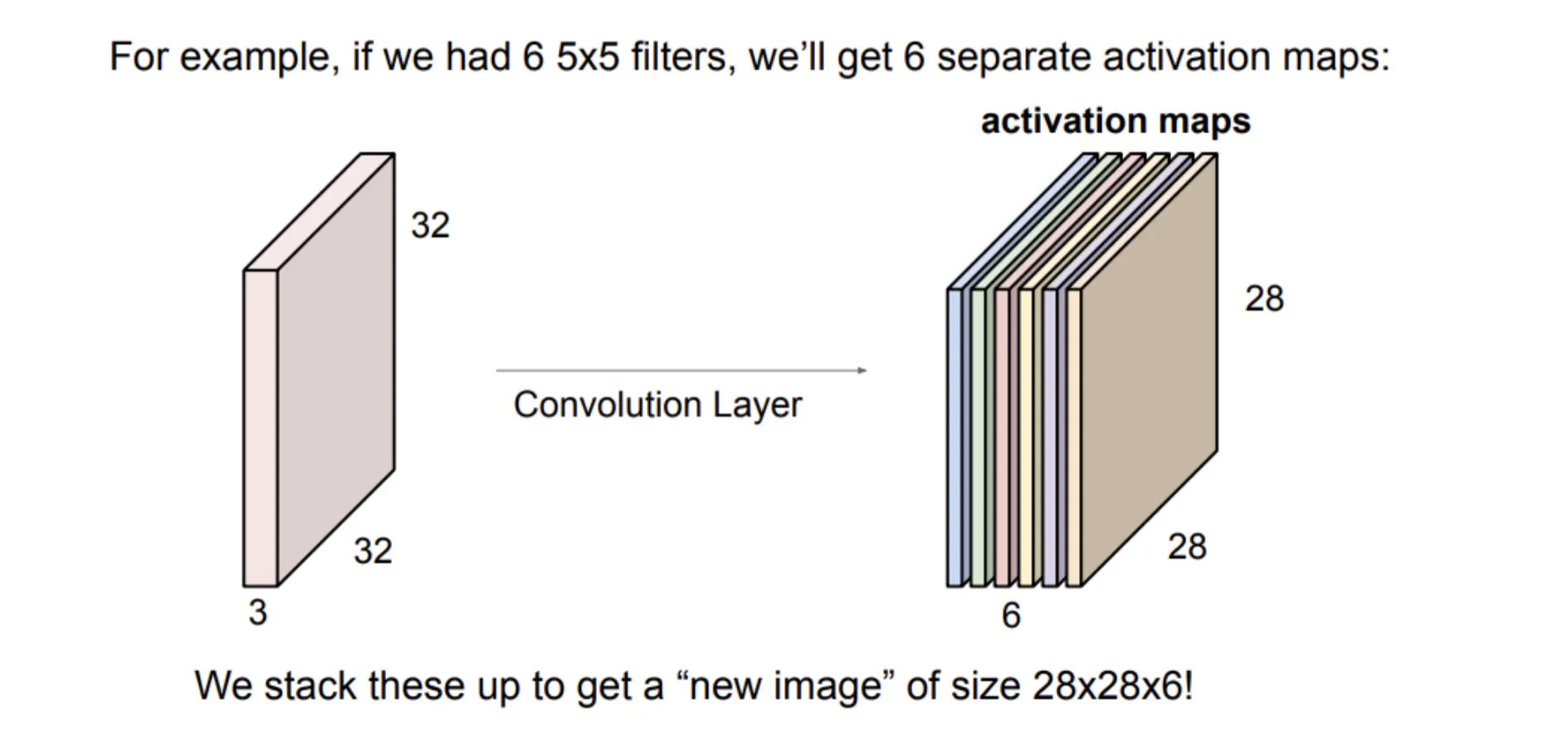
Stride and Padding#
对于输入图像,不进行padding,卷积核大小为,以步长为进行卷积操作,输出图像的大小为;步长为,则输出图像的大小为
加入步长可以显著加快CNN收集特征的速度
考虑padding后,输出图像的大小为
Pooling#
池化(Pooling)是一种常用的下采样方法,可以快速地减少特征图的尺寸,同时保留一些特征信息。常见的池化方法有:
- 最大池化(Max Pooling)
- 平均池化(Average Pooling)
池化的基本思想是将输入特征图划分为若干个不重叠的区域,然后在每个区域内进行操作,得到一个输出图。下图为最大池化的示例:
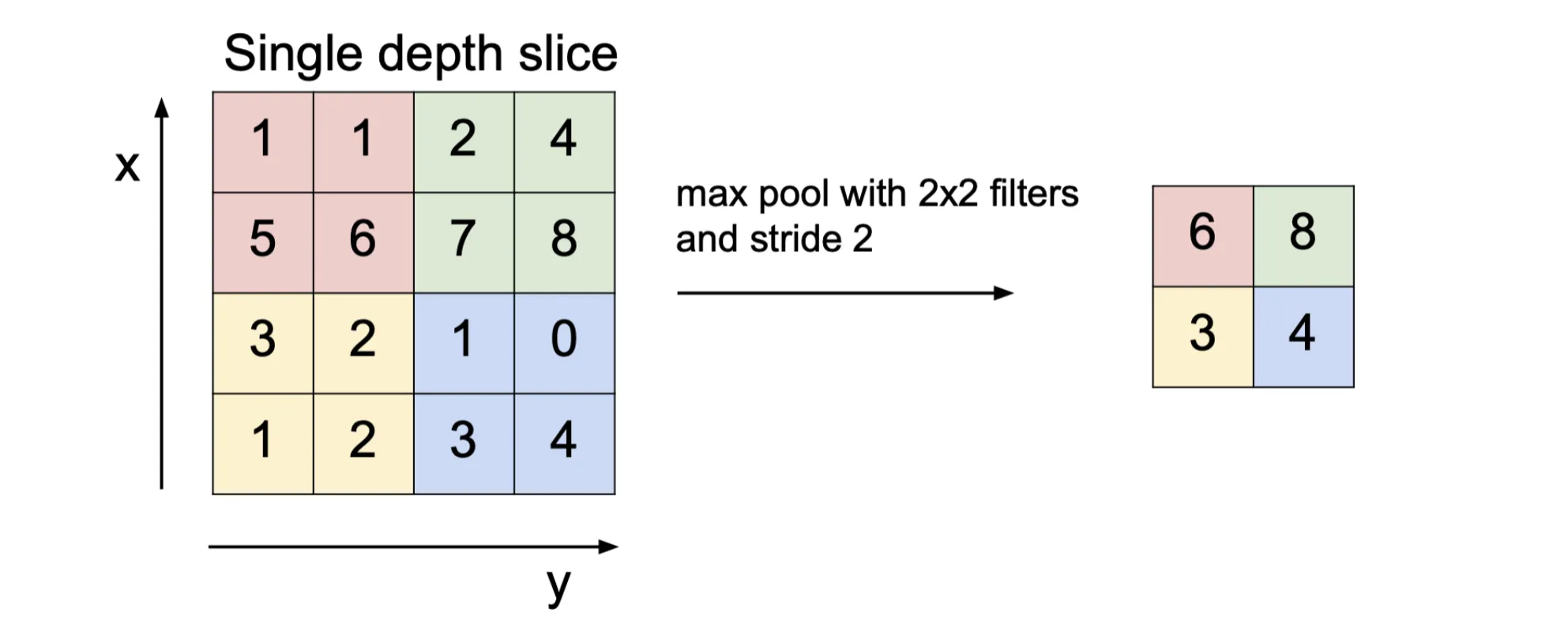
的池化直接将输入图像的长宽变为原来的一半,且参数数量为0,不需要学习
MLP vs CNN#
对于输入大小为,输出大小为,不考虑bias:
MLP使用全连接层,参数量为。 CNN使用卷积层,对于大小为的filter,参数量为
可以看到CNN的参数量远远小于MLP
Sparse Connectivity#
CNN 为什么这么省参数
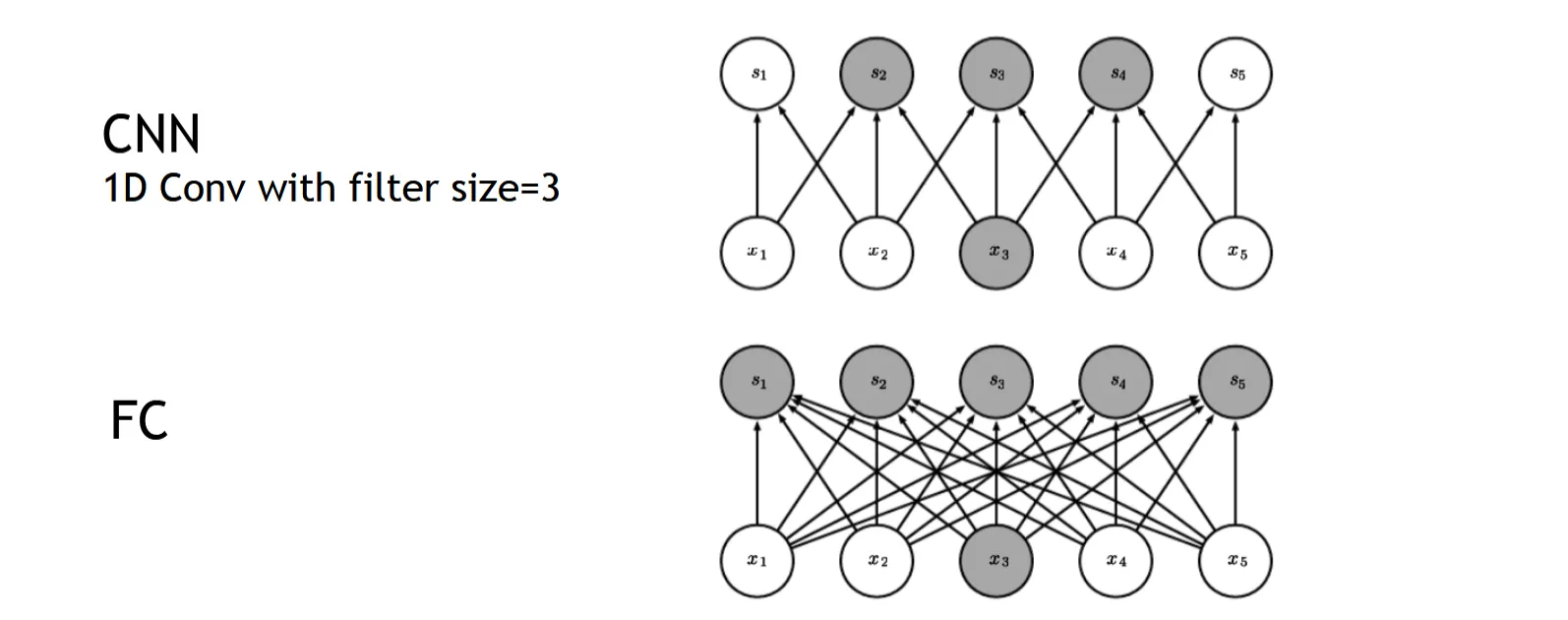
在卷积层中,每个输出单元只与输入图像的一个局部区域相连接(个像素),这种连接方式被称为稀疏连接(Sparse Connectivity)。全连接层(FC)中每个输出单元与输入图像的所有像素相连接
此外,卷积层中的权重是共享的,即同一个卷积核在整个输入图像上进行卷积操作,使用相同的权重,进一步减少了参数数量
图像干扰#
对于图像的一些小扰动,比如平移几个像素,图像展开的向量会发生很大的变化,权重对应的位置也随之变化,会引发输出的巨大变化。想要学习出微小移动后不变的MLP非常困难
我们之前提到过卷积的等变性,图像在平移后,卷积层的输出也会相应地平移,几乎不会影响后续处理。
CNN Training#
具体方法:Mini Batch SGD
Data Preprocessing#
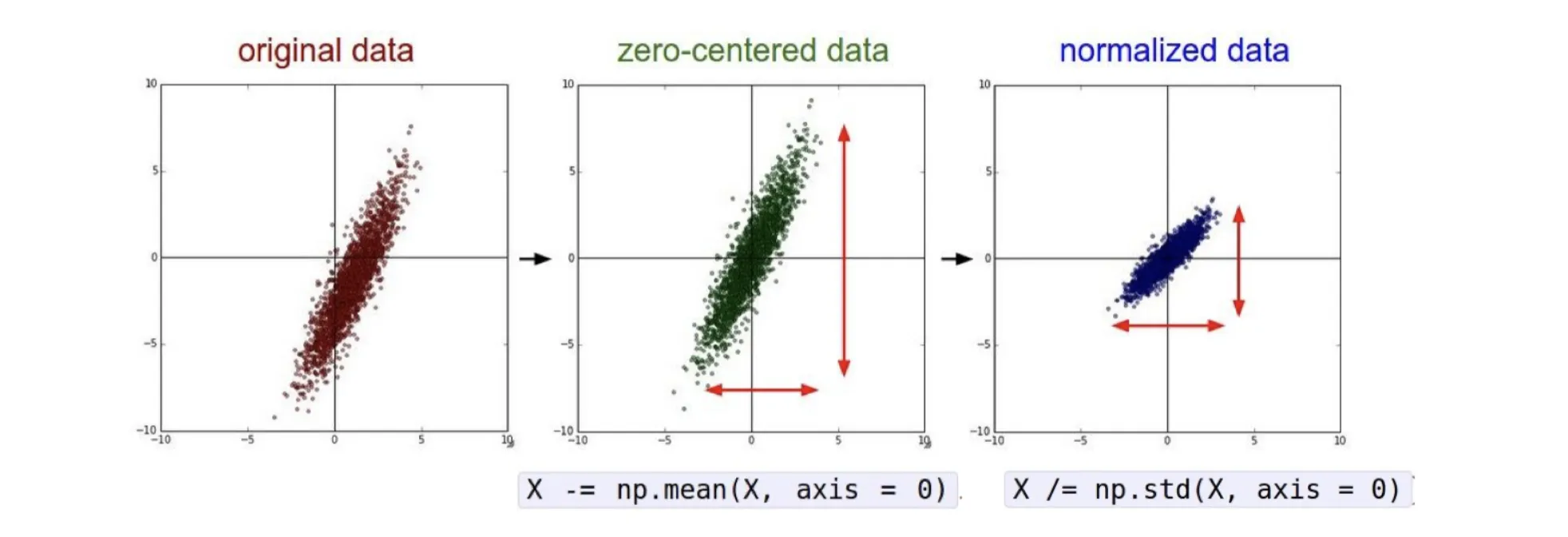
为了得到更普遍的特征,通常会对输入图像进行一些预处理操作,如normalize。这样使得模型不容易过拟合到训练数据的特定分布
Weight Initialization#
- 随机初始化权重较小的随机值,通常使用正态分布
w = 0.01 * np.random.randn(D_in, D_out)
问题:随着层数增加,减小,梯度也会减小,导致梯度消失问题
Xavier Inititalization:
权重初始化为w = np.random.randn(D_in, D_out) / np.sqrt(D_in)
可以保持每层的输入和输出的方差相同,缓解梯度消失问题
He Initialization:
对于ReLU激活函数,Xavier初始化没有考虑ReLU会将负值置零的操作,导致输出的方差减半。He初始化通过增加权重的方差来补偿这个问题
权重初始化为w = np.random.randn(D_in, D_out) * np.sqrt(2. / D_in)
Start optimization#
SGD不足:
- 对于loss中某个方向梯度较大,另一个方向梯度较小的情况,会导致优化过程震荡,难以收敛
- 局部极小值和鞍点
- mini-batch的噪声可能会导致优化过程不稳定
SGD + Momentum:

引入动量项,利用之前的梯度信息来进行收敛,减少震荡,一般取
Learning Rate#
- learning rate 小,收敛速度慢
- learning rate 大,可能会错过最优解,甚至发散
Learning Rate Schedule:
主要想法:在开始时使用较大的学习率来快速收敛,后续逐渐减小学习率以获得更好的性能
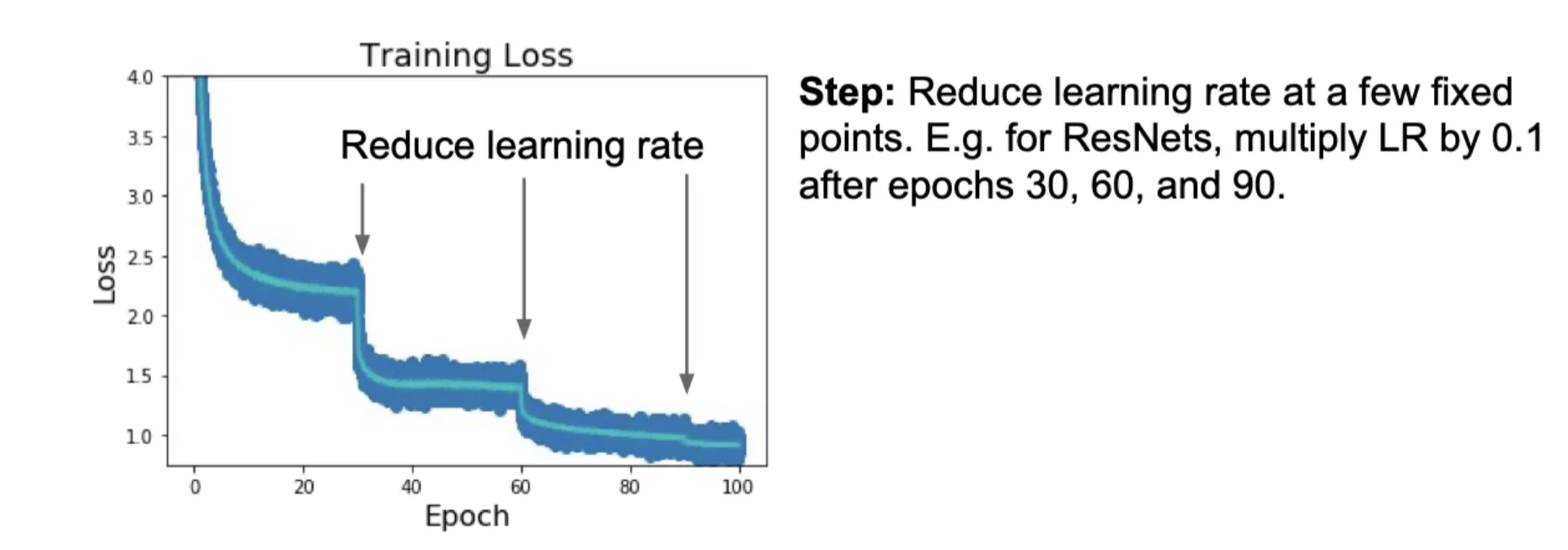
一些常见的学习率调整方法:
- Step:每隔一定的epoch数将学习率降低一个固定的比例(上图)
- Cosine:
- Linear:
- Inverse sqrt:
是初始学习率,是当前的epoch数,是总的epoch数
一个经验规律:如果增大batch size N倍,则初始学习率也要对应放大N倍