Classic CV Pipeline#
经典的计算机视觉流程包括以下几个步骤:
- Keypoint detector(比如Harris算子):找到图像中相关的关键点
- Keypoint descriptor(比如SIFT):描述关键点的局部特征
- Image representation(比如Bag of Visual Words):整合所有关键点的特征,得到图像的整体特征
- Classifier(比如SVM):简单的分类器,根据图像的整体特征进行分类
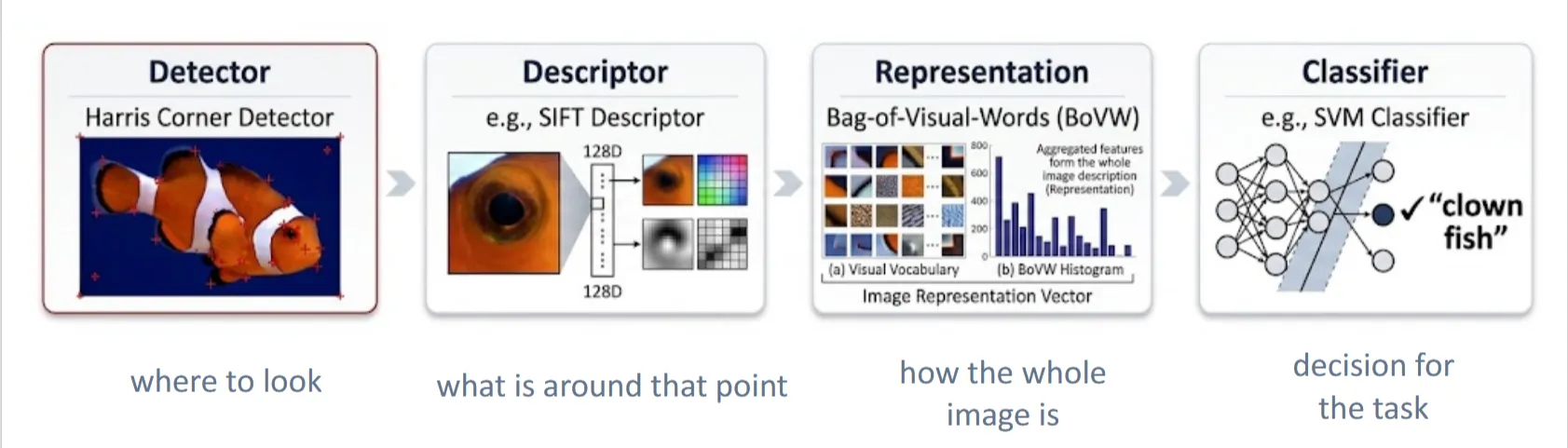
经典CV的一些缺点:
- 高度依赖于人工设计的特征提取方法
- 前一个阶段的错误会传播到后续阶段,导致整体性能下降
- 对于复杂几何的理解能力有限(比如一些难以描述的图像结构)
- 难以用数据进行扩展(不能像CNN一样通过大量数据进行训练和优化)
- 生成能力有限
Deep Learning#
Set up the task#
对于一个任务,我们要定义输入和输出,比如对于识别一个手写数字是不是5
- 输入:一张图像
- 输出:一个二分类的标签(是5或者不是5),有时也可以是一个概率值
Prepare the data#
需要有标注的数据集,比如MNIST,将其分为训练集和测试集
Built a model#
对于输入图像,我们可以使用线性模型来进行训练,此外,我们还需要将模型的输出转化为0到1之间的概率值,这时候我们可以使用sigmoid函数来进行转化:
y^=σ(wTx+b)=1+e−(wTx+b)1
Loss function#
使用MLE(Maximum Likelihood Estimation)来优化模型
具体来说,就是最大化训练数据的似然函数:
L(w,b)=i=1∏NP(yi∣xi;w,b)=i=1∏Nyi^yi(1−yi^)(1−yi)
因为乘法的形式不太方便计算,我们通常会取对数来转化为加法的形式:
logL(w,b)=i=1∑N[yilogyi^+(1−yi)log(1−yi^)]
习惯上我们会取负号来转化为最小化的形式,这样就得到了NLL损失函数:
J(w,b)=−N1i=1∑N[yilogyi^+(1−yi)log(1−yi^)]
对于复杂的模型,没有解析解,我们需要使用数值优化的方法来进行求解,比如梯度下降法(Gradient Descent):
w:=w−α∂w∂J(w,b)b:=b−α∂b∂J(w,b)
α是学习率,即每次更新的步长,是一个超参
sigmoid函数和损失函数也需要进行求导
∂w∂J(w,b)=N1i=1∑N(yi^−yi)xi∂b∂J(w,b)=N1i=1∑N(yi^−yi)
∂zσ(z)=σ(z)(1−σ(z))
现在的模型都是一次性使用很多数据进行训练,此时梯度的计算一般使用这些数据梯度的平均值。
根据每次训练时使用的数据量不同,梯度下降法可以分为以下几种:
- Full Batch Gradient Descent:每次使用整个训练集进行梯度计算和参数更新
- Stochastic Gradient Descent:每次使用一个样本进行梯度计算和参数更新
- Mini-batch Gradient Descent:每次使用一个小批量的样本进行梯度计算和参数更新
Testing#
我们的输出是一个概率值,我们需要设定一个阈值来进行分类,比如0.5,如果y^≥0.5,我们就预测为1,否则预测为0
Multilayer Perceptron#
单层神经网络只能处理线性可分的数据,对于非线性可分的数据,我们需要引入隐藏层来进行非线性变换,这样就得到了Multilayer Perceptron(MLP)
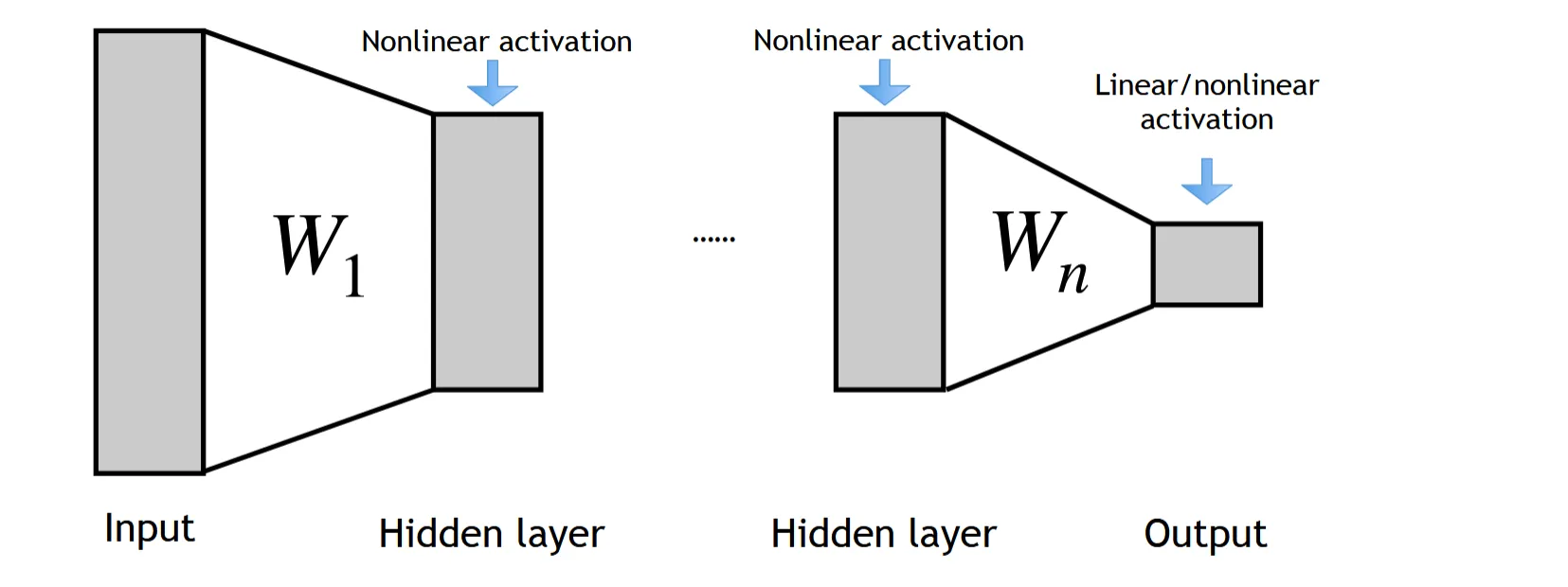
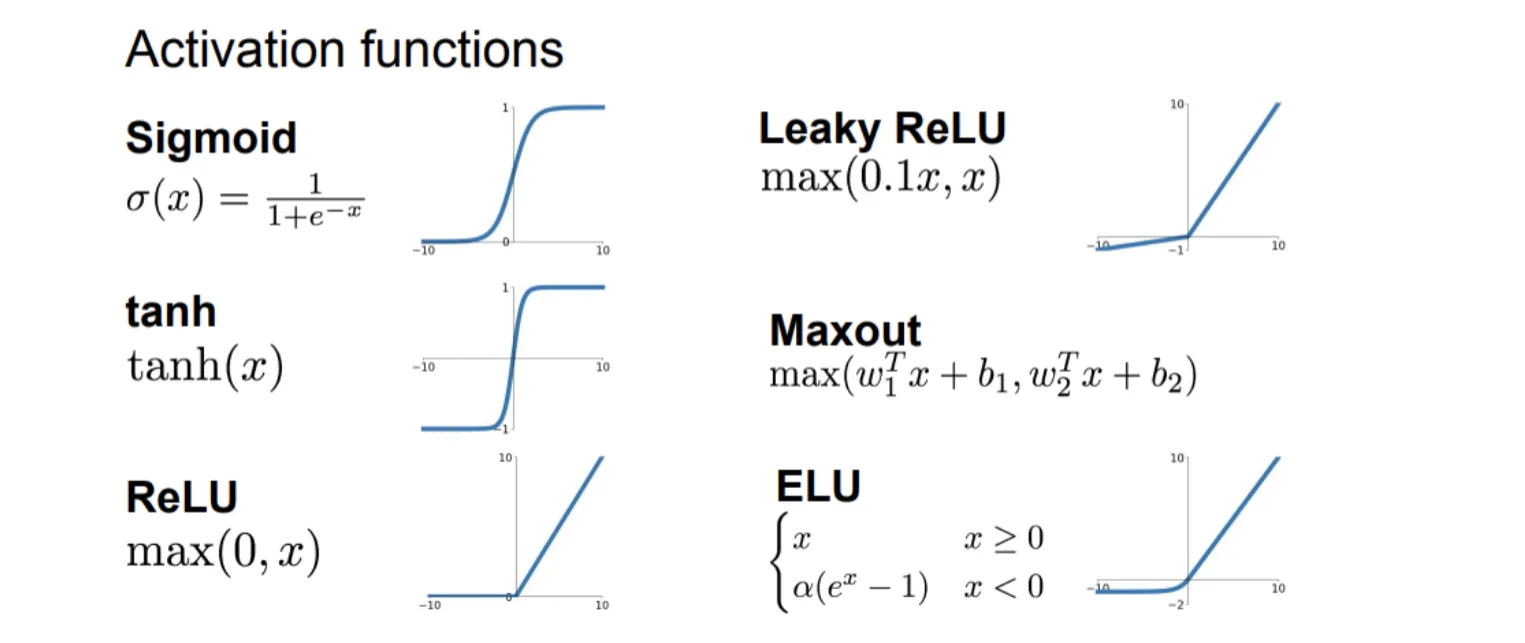
在线性层之后加入非线性激活函数,增强模型的表达能力,下面是一些常用的激活函数:
MLP training#
MLP的训练过程和之前的单层神经网络类似,也是使用梯度下降法来进行参数更新,但是由于MLP的结构更复杂,我们需要使用反向传播算法(Backpropagation)来计算梯度
反向传播算法的核心思想是链式法则,通过从输出层开始逐层向前计算梯度,最终得到每个参数的梯度值,然后进行参数更新
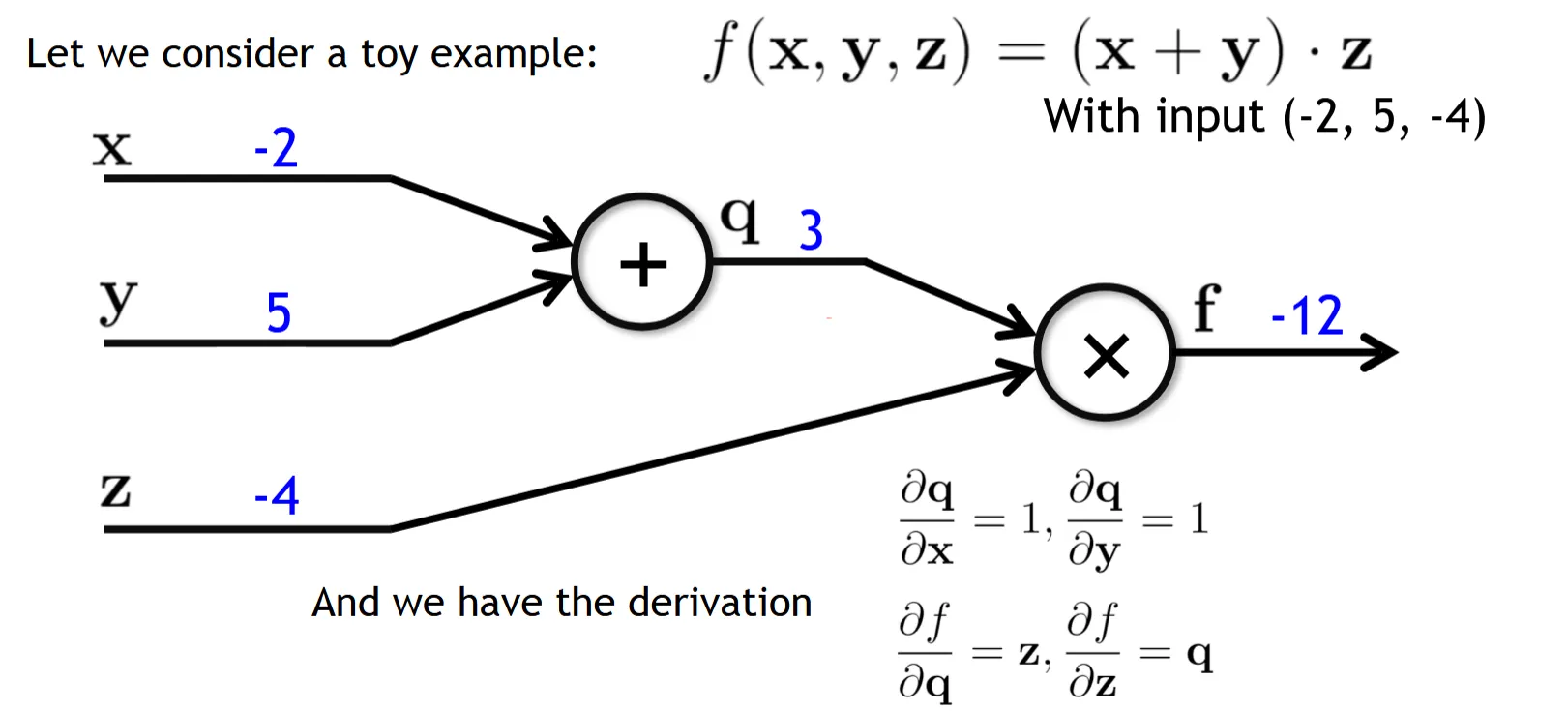
正向传播如上图所示,现在我们从输出往前进行反向传播
∂z∂f=∂f∂f⋅∂z∂f=1×q=3
同样可得∂q∂f=1×z=−4,看后续的加法:
∂x∂f=∂q∂f⋅∂x∂q=−4×1=−4
对y也同理