本文内容基于 2025 秋季《计算机体系结构》双语班课程讲述,如有差错,欢迎指正
Overview#
SSD Position#
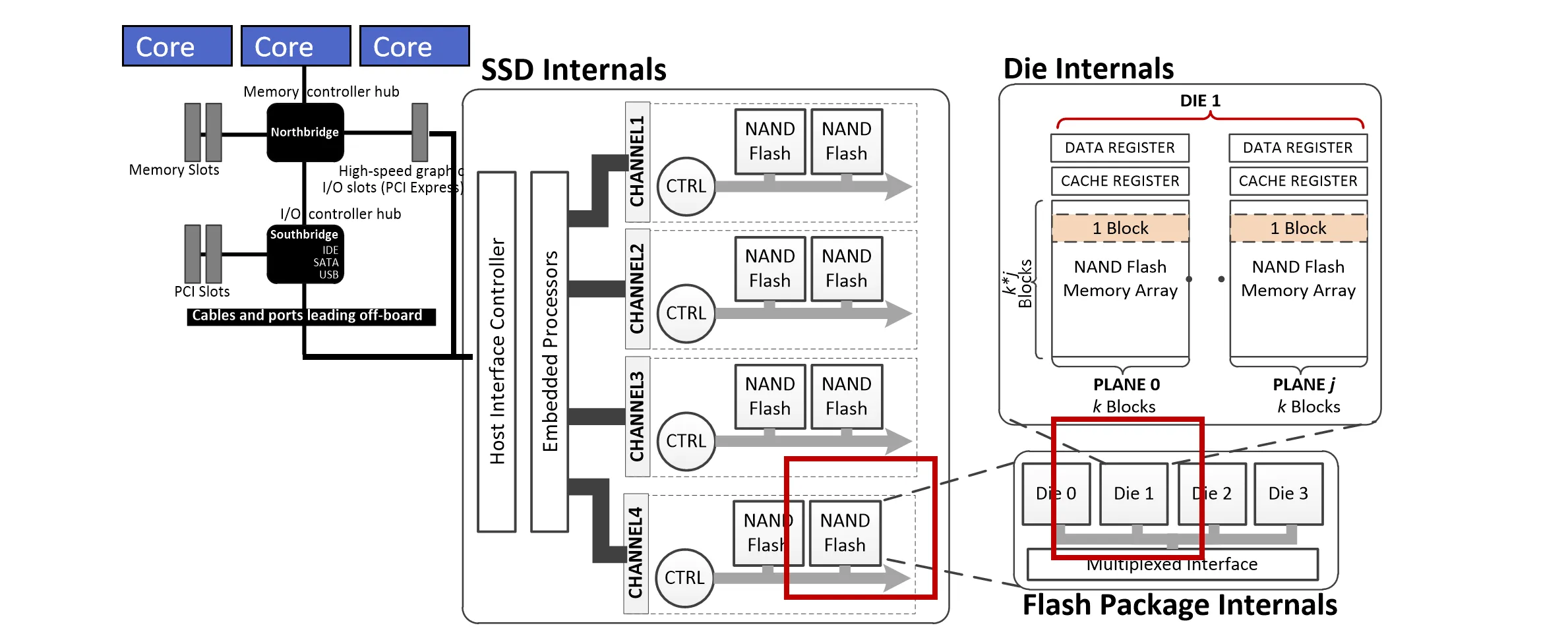
这里先整体看一下 SSD 在系统中的位置: CPU 核通常连接到北桥(或者Memory controller hub),北桥连接到内存和南桥(I/O controller hub)。 南桥连接到各种 I/O 设备,包括 SSD。我们一般认为南桥和北桥都能连接到 SSD,不过接口不同:北桥通常使用 PCIe 接口,而南桥通常使用IDE、SATA 或 USB 接口。
SSD 内部主要分为三部分:Host Interface Controller(主要负责与 Host 通讯),Embedded Processors(就是我们之前说过的 FTL)以及许多 Channels。
Embedded Processors连接着多条channel,每条channel内部有自己的控制器和多个NAND Flash Packages。 每个Package 上面会连多个闪存Die,一个Die上会连两个 Plane,每个Plane上有自己的闪存阵列。
像 DRAM 一样,SSD 内部也是一个套娃的结构,以提高并行性
一般来说,一个 Die 里面的两个 Plane 共用一条总线,一个请求只能访问一个 Plane。
Plane 里有两个 Register,这两个 Register 的作用和我们之前说的 PCM 里面的buffer ↗类似, 可以用来提高并行性(比如在读第一个 Register 的数据时,可以同时向第二个 Register 写数据)
Software View#
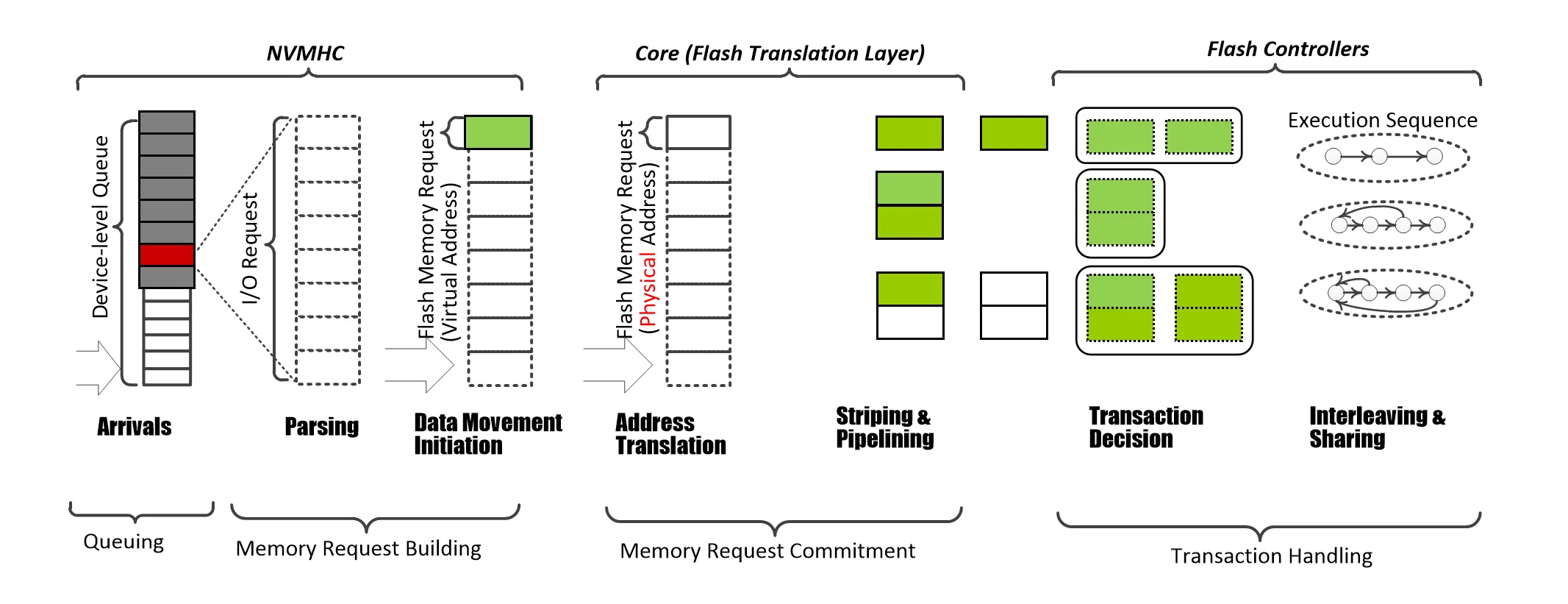
里面一些术语可能不太一样,比如 NVMHC(Non-Volatile Memory Host Controller)就是 Host Interface Controller 的意思
NVMHC 内部维护一个请求队列,从 Host 端获取请求,放入队列。
队列中的请求可能包含多种数据的访问,下一步需要把指令进行拆分,拆成多个对单页的 IO 指令
接下来 FTL 会把页的地址翻译成物理地址,然后对这些指令进行调度,把指令和数据(写操作)交给 Flash Controller
Flash Controller 负责完成细粒度的读写操作,和 Flash 芯片进行交互
下面我们主要会关注 NVMHC 获取请求、FTL 调度这两部分
SSD Architecture & Parallelism#
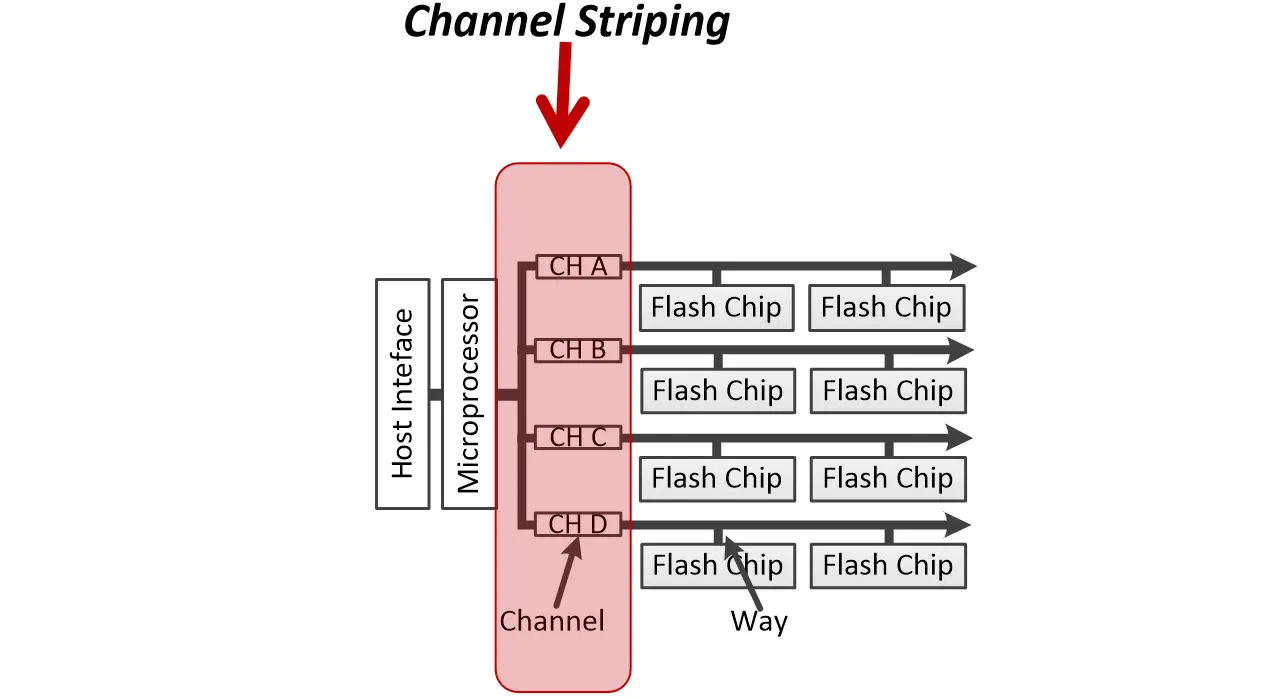
Embedded Processors 会连接多个 Channel,这些 Channel 其实就是一条数据总线
对于连接在总线上的每个 Flash Package,我们称作 Way
这里面有几种并行方式:
- Channel Striping:channel 级别的并行。是一种完全的并行方式,因为每个 Channel 都有自己的控制器
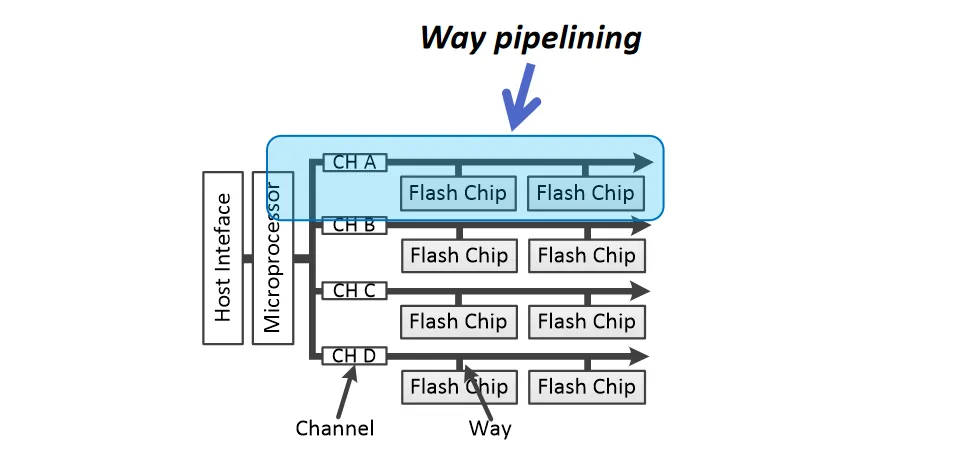
- Way pipelining:在同一个 Channel 上的多个 Way 之间进行流水线操作(比如way1 在使用总线时,way2在内部读取数据),每个 way 会征用同一条总线
上面这两种属于System-Level Parallelism
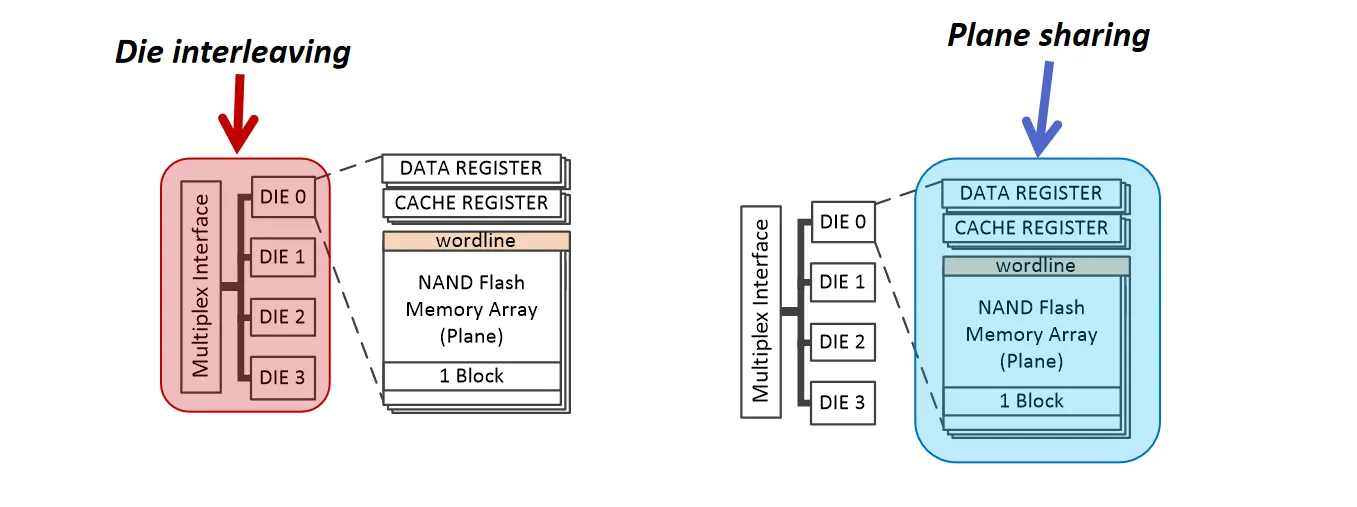
- Die interleaving:在同一个 Way 上的多个 Die 之间进行流水线操作
- Plane sharing:通常来说 Die 一次性只能访问一个 Plane ,但可以通过一些手段,比如访问的两个页正好共用一条wordline,从而实现同时访问
这两种属于Flash-Level Parallelism
Page Allocation Strategies#
也是联想 DRAM,我们知道了物理地址,但需要策略决定这些物理地址存放的位置在哪(哪个 Channel、Way、Die、Plane 上)
在 SSD 里面,一共有 24 种不同的分配策略,主要可以分为四类:
- Channel first:优先使用不同的 Channel,充分利用 Channel Striping。后面同理
- Way first
- Die first
- Plane first
我们用首字母顺序来称呼不同决策,比如 CWDP — 按照Channel, Way, Die, Plane的顺序来分配。按照排列组合可以得出24种
不同的策略会影响 SSD 的性能
吞吐上来说,Die first 和 Plane first 会更好一些; 延迟上来说,Channel first会更好一些
Host Interface Overview#
如今SSD内部存储系统的速度已经很快了,但是Host和SSD之间的通讯速度成为一个瓶颈。
NVMe Machinism#
曾经流行的IDE和SATA接口已经不能满足需求了,现在主流的是NVMe over PCIe接口
- PCIe从北桥出来,SATA从南桥出来,北桥的带宽更大
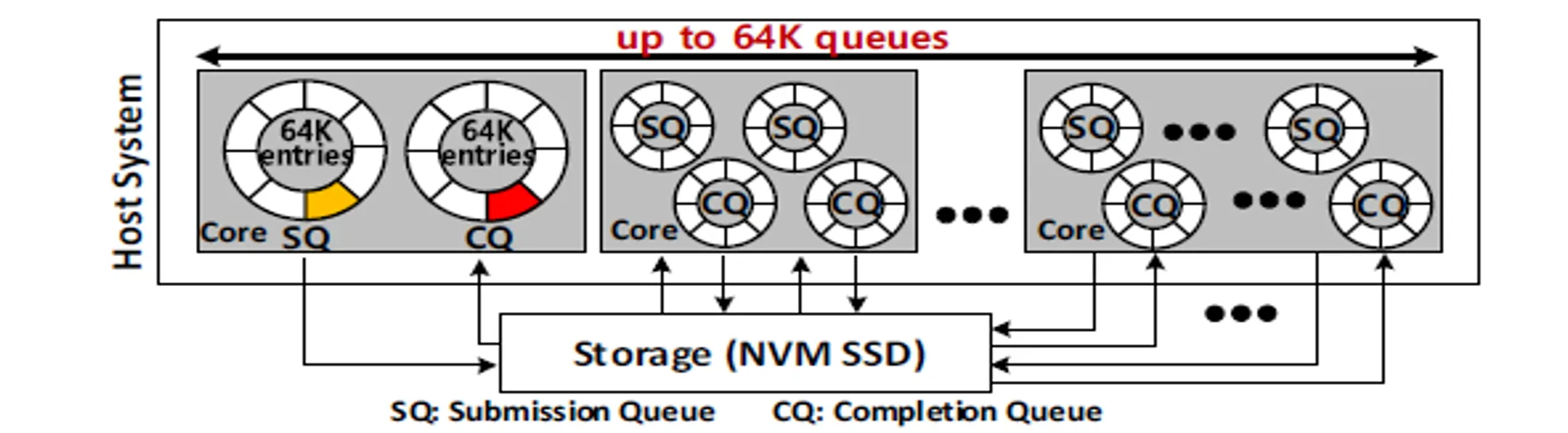
- 传统的接口只提供一个 I/O 队列和少量的 entry ,NVMe提供了 64K 个队列,每个队列有 64K 个 entry,提高了并行性
- 每个 Core 分配独有的队列可以减少锁竞争
SSD Interface 主要分为两种,基于硬件的(H-Type,Hardware driven,比如SATA)和基于软件的(S-Type,Software driven,比如NVMe)
这两种构造的主要区别见下图:
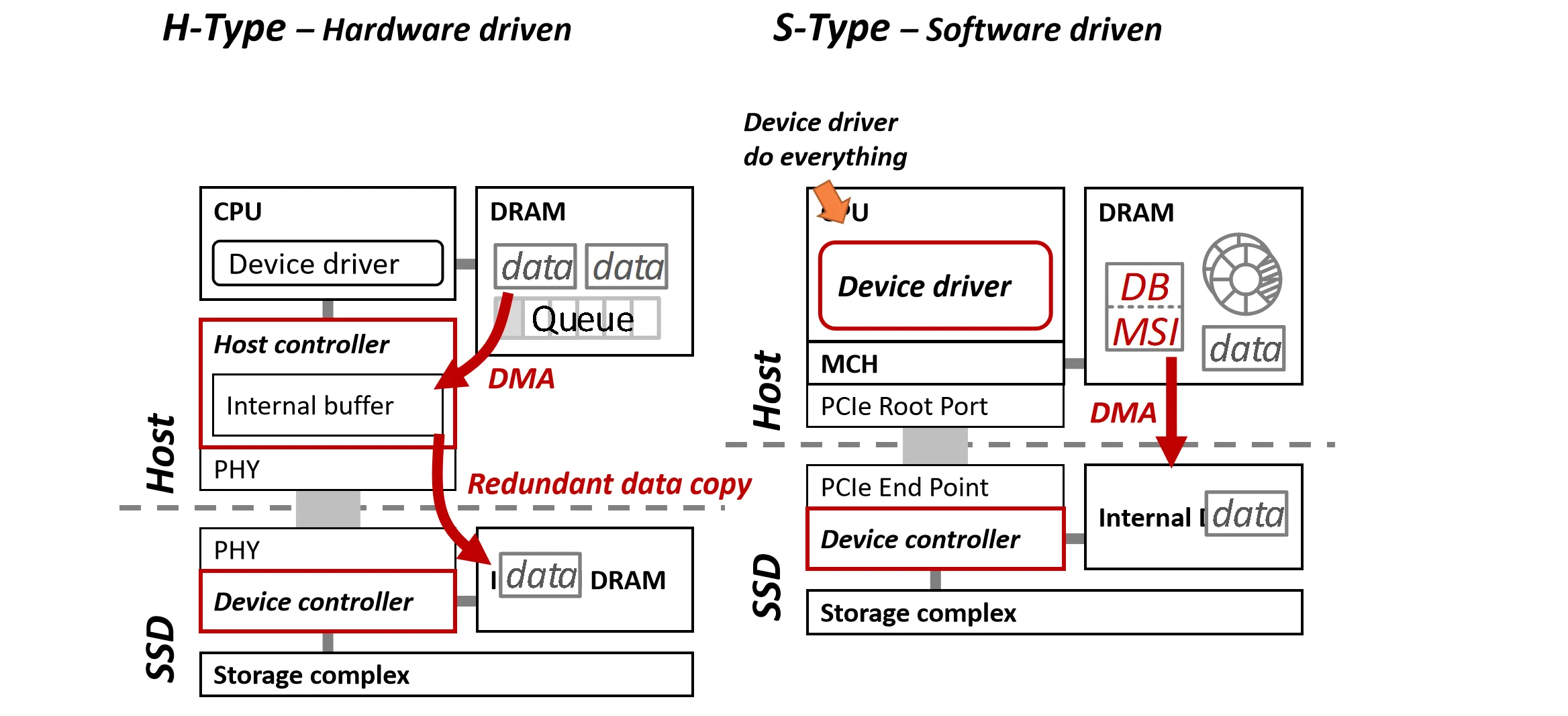
H-Type 中包含一个硬件(Host Controller)和 SSD 通讯,而S-Type 中没有这个硬件,直接通过 Device Driver 和 SSD 通讯
- 因为早期 SSD 很慢,Host Controller 作为托管,可以避免拖慢 CPU;现在因为 SSD 速度上来了就不再需要额外一层硬件了,减少了一次通讯开销
H-Type 中数据需要两次拷贝(DRAM Host Controller SSD),而 S-Type 只需要一次(DRAM SSD)
NVMe Queue Management#
两个队列:Submission Queue (SQ) 和 Completion Queue (CQ)
- 都是环形队列,有头指针和尾指针
- 实际NVMe中不需要每个 SQ 和 CQ 都有头尾指针,一般 SQ 只需要尾指针,CQ 只需要头指针
- SQ 用来存放 Host 发给 SSD 的请求,CQ 用来存放 SSD 完成的请求
下面简化介绍一下 NVMe 的工作流程:
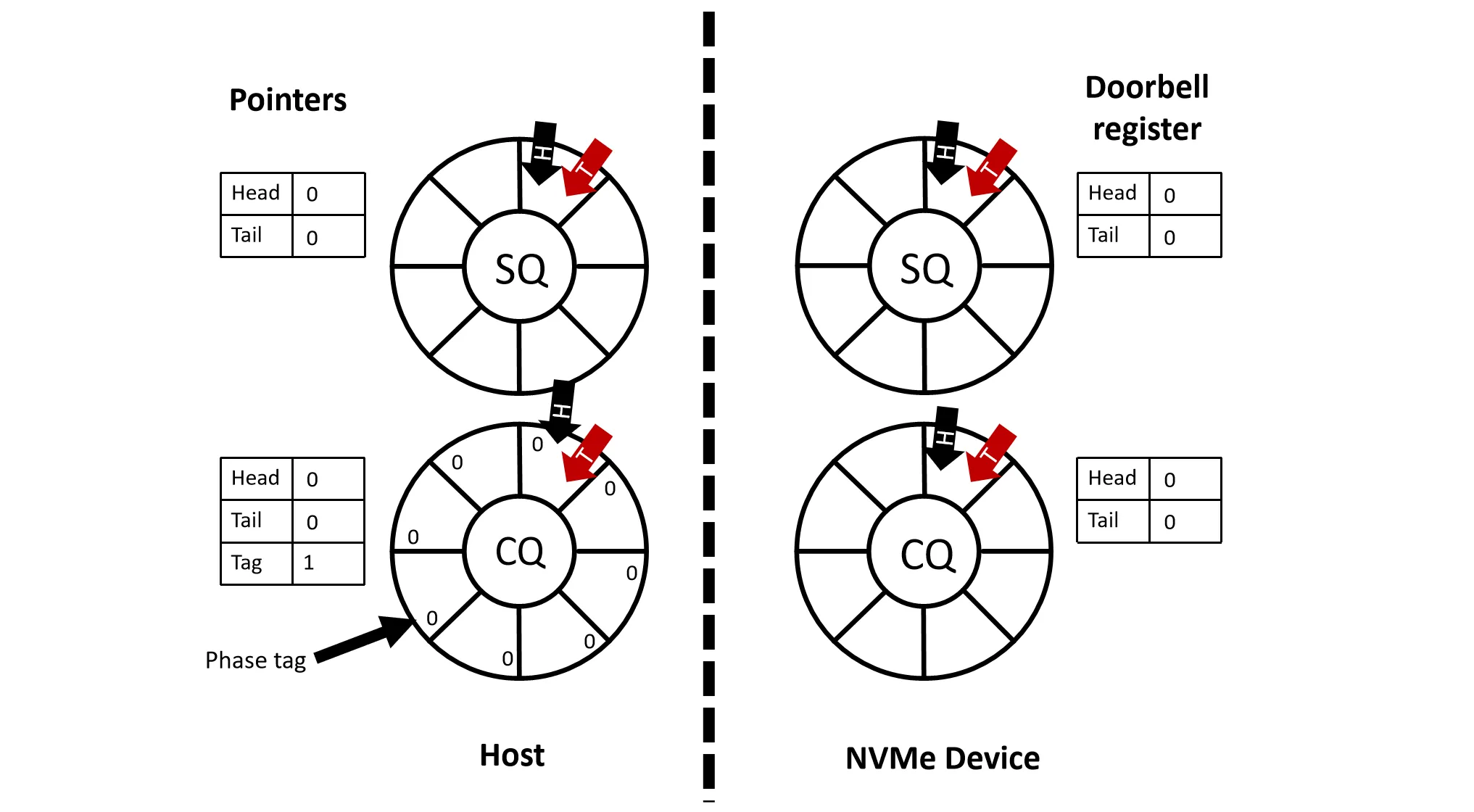
- 注:实际NVMe Device中不一定有 SQ 和 CQ,这里为了方便理解才画出来的
- doorbell register:Host 和 SSD 之间的一个通信机制,Host 通过写这个寄存器来通知 SSD 有新的请求
- phase tag:用来标记 CQ 中的 entry 是否是新的,防止 Host 重复读取同一个 entry
Step1: Host 把请求放入 SQ 中,尾指针后移,然后写 doorbell register 的尾指针,通知 SSD 有新请求(通过 MMap I/O 技术向 SSD 的寄存器写入)
Step2: SSD 轮询 doorbell register,发现尾指针后移,通过 DMA 从内存中读取 SQ 中的请求到内部,对请求进行处理
Step3: 处理完成后 SSD 把结果通过 DMA 写入 CQ 中,然后通过中断(MSI)通知 Host,Host 通过 phase tag 读取 CQ 中的结果,头指针后移,并写 doorbell register 的头指针,通知 SSD 已经完成
其他接口的通讯#
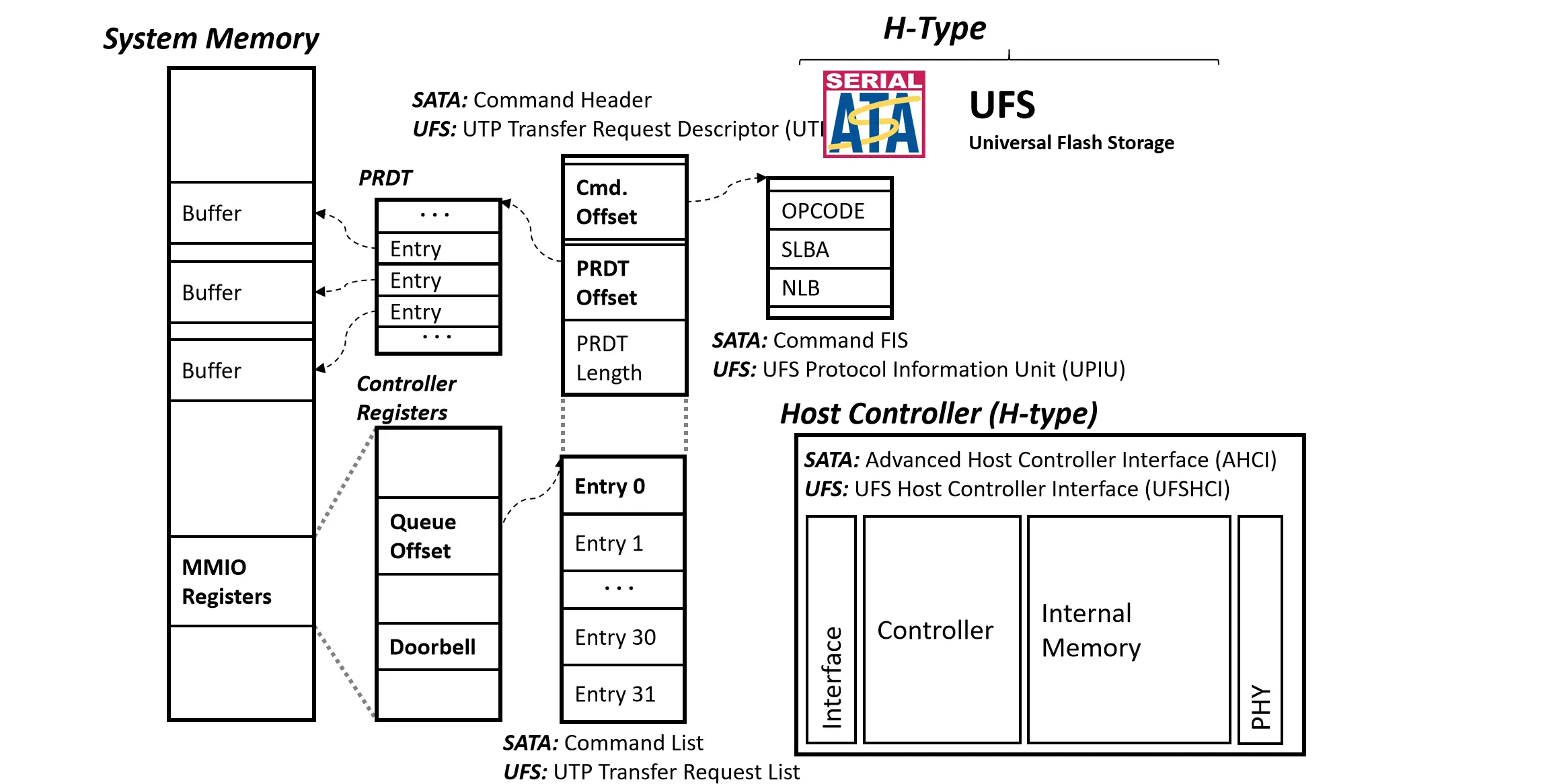
像 SATA 这种 H-Type 接口,Host 通过 Host Controller 和 SSD 通讯。
在主存中 MMIO 映射了一块内存区域,区域中有一个 Queue Offset 指针,指明了 SQ 和 CQ 在内存中的位置
每个 Queue Entry 中包含了 Command、数据位置(PRDT Offset)以及数据长度等信息
数据可以不是连续存放的,PRDT中有一系列指针指向数据块的位置
NVMe 的接口和上面的非常类似
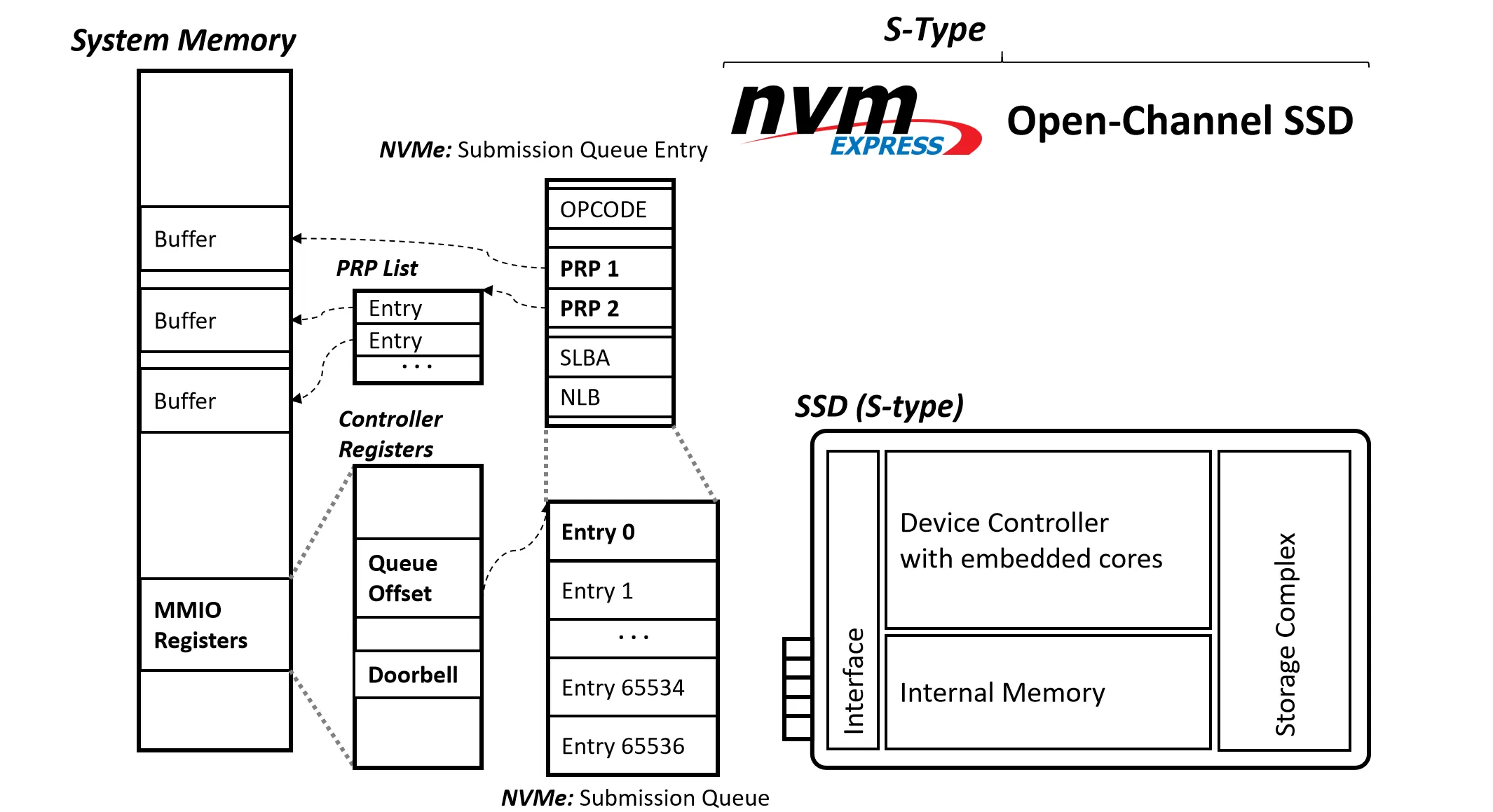
注意到 NVMe 中没有 Host Controller,Host 直接通过 Device Driver 和 SSD 通讯
NVMe 中的 SQ 和 CQ 的 Entry 很多,Entry 内容也复杂一些,对于数据存放做了些优化(有点像文件系统中的处理)
- PRP1:对于小请求,数据直接写在这里指向的内存区域
- PRP2:对于大请求,PRP2 指向一个链表(PRP List),链表中每个节点指向一块数据区域
OCSSD#
NVMe 中 FTL 的功能内置于 SSD 内部,而 OCSSD (Open-Channel SSD) 则把 FTL 的功能放到了 Host 端
- SSD 内部的 Processor 不需要很强,可以降低成本
- 需要 CPU 的计算单元来完成 FTL 的功能(CPU的计算能力真的够用吗?)
- 商家机密的 FTL 技术放到 OS 里面
RAID#
冗余磁盘阵列(RAID)技术通过将多个较小的独立磁盘组合起来,向外部提供一个逻辑上的巨大、快速且可靠的存储设备
RAID 0:Striping#
在RAID 0中,数据被分割成固定大小的Chunk(最小是1个block),并分散存储在阵列的所有 个磁盘上
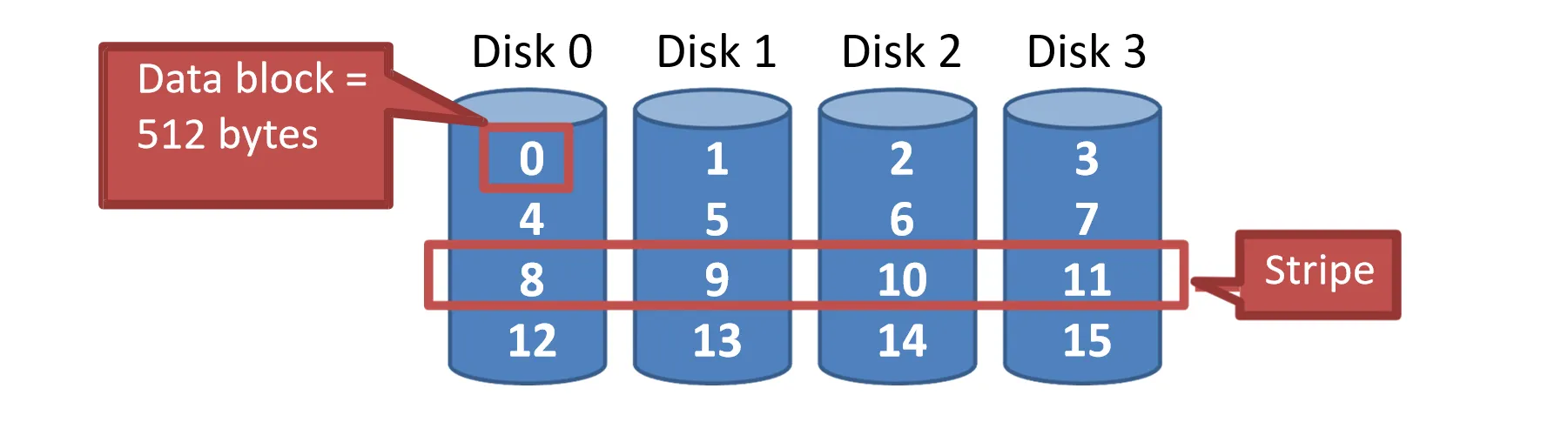
为了定位数据,假设我们要访问逻辑块号 ,可以通过以下公式计算出数据所在的磁盘号和磁盘内偏移量:
- 磁盘号 =
- 磁盘内偏移量 = (从0开始)
性能分析:
- 容量: 倍的单盘容量
- 可靠性:无保障
- 顺序读写性能:(设单个盘顺序读写速度为 )
- 随机读写性能:(设单个盘随机读写速度为 )
- 因为读写可以全部并行进行
RAID 1:Mirroring#
RAID 1的核心是镜像,所有数据进行双份存储
一般来说,不会单独使用RAID 1,而是和RAID 0结合使用,形成RAID 1+0/RAID 0+1
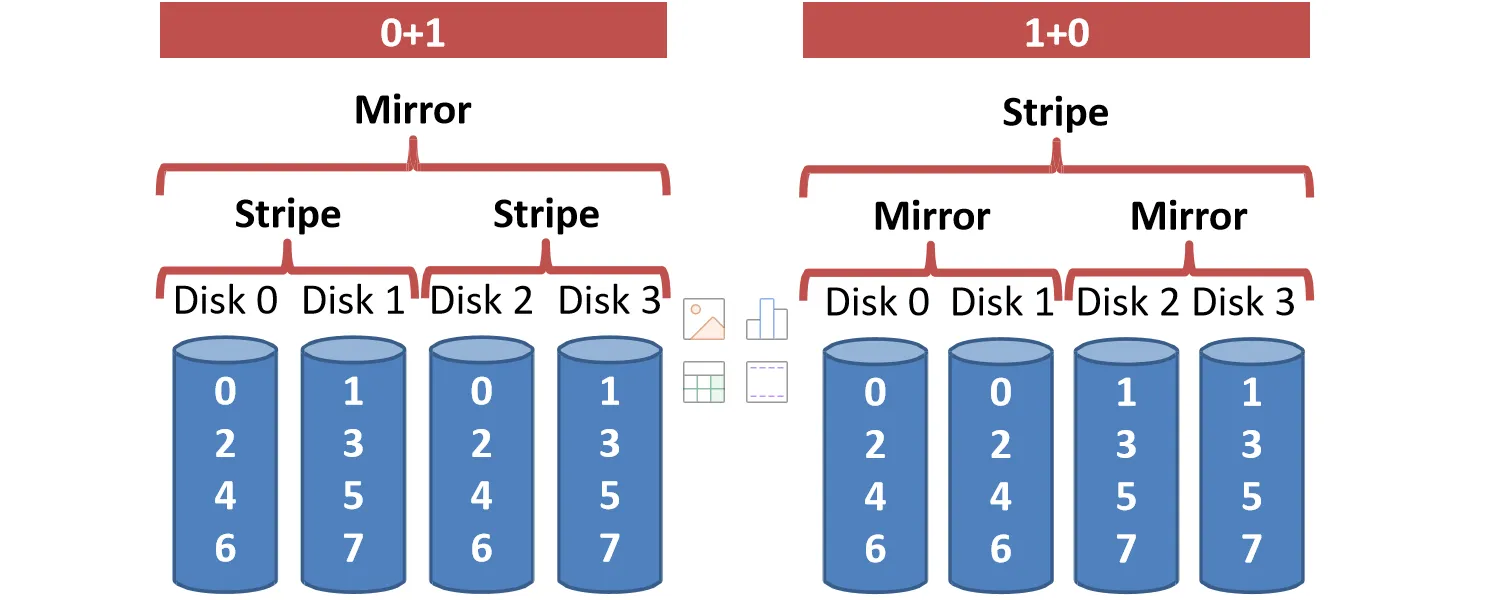
一般来说,右边的性能好于左边,因为如果Disk0坏掉了,左边因为Disk1需要和Disk0一起工作,因此不能使用,只剩下Disk2和Disk3;而右边的Disk1可以继续工作
RAID 01性能分析:
- 容量: 倍的单盘容量
- 可靠性:可以容忍最多 个盘坏掉(坏掉的盘不能在同一组镜像中)
- 顺序读写性能:
- 随机读性能: 镜像盘可以同时服务
- 随机写性能:
RAID 4#
RAID 1提供了很高的可靠性,但是现实中一般不需要这么高的可靠性。因此RAID 4引入了奇偶校验的概念,只储存少量的冗余信息来提供容错能力
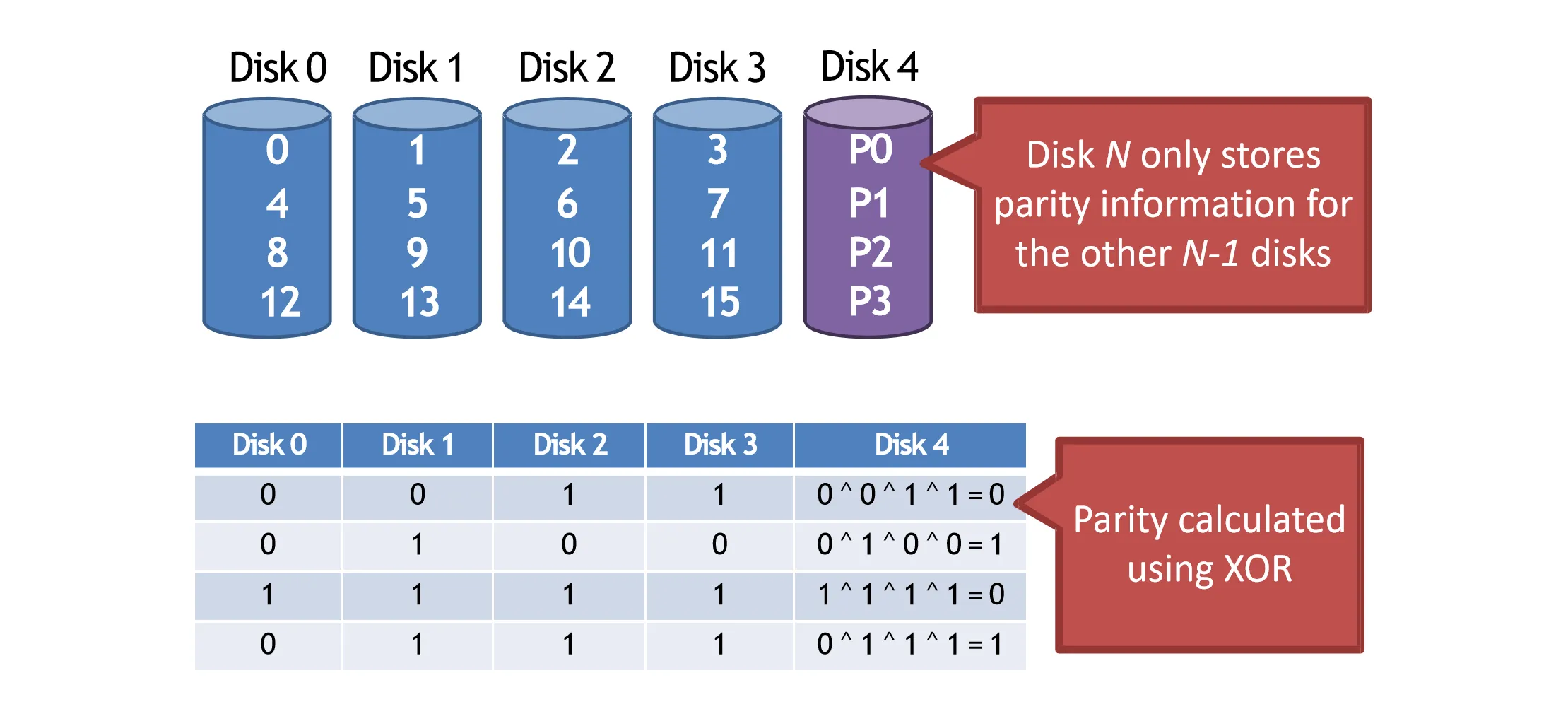
RAID 4中,有单独的一块盘被用于存储校验信息,当其他的一块盘坏掉时,可以通过校验信息恢复数据
RAID 4在进行数据更新时也需要更新校验数据,具体方法有两种:
- Additive parity:每次更新时把其他盘上的数据读出来,重新计算校验和,再把数据和校验信息写回去(代价较大)
- Subtractive parity:先把旧数据和旧校验信息读出来,把旧数据、新数据、旧校验信息计算xor,得到新校验数据,最后把数据和校验信息写回
这个性质导致RAID 4的随机写性能较差,每次都要读写校验盘各一次,使得校验盘成为瓶颈
- 容量: 倍的单盘容量
- 可靠性:可以容忍最多 1 个盘坏掉
- 顺序读写性能:
- 随机读性能:
- 随机写性能: 校验盘读写各一次
RAID 5#
为了解决RAID 4中校验盘的瓶颈问题,RAID 5引入了分布式校验,把校验信息分散存储在所有盘上
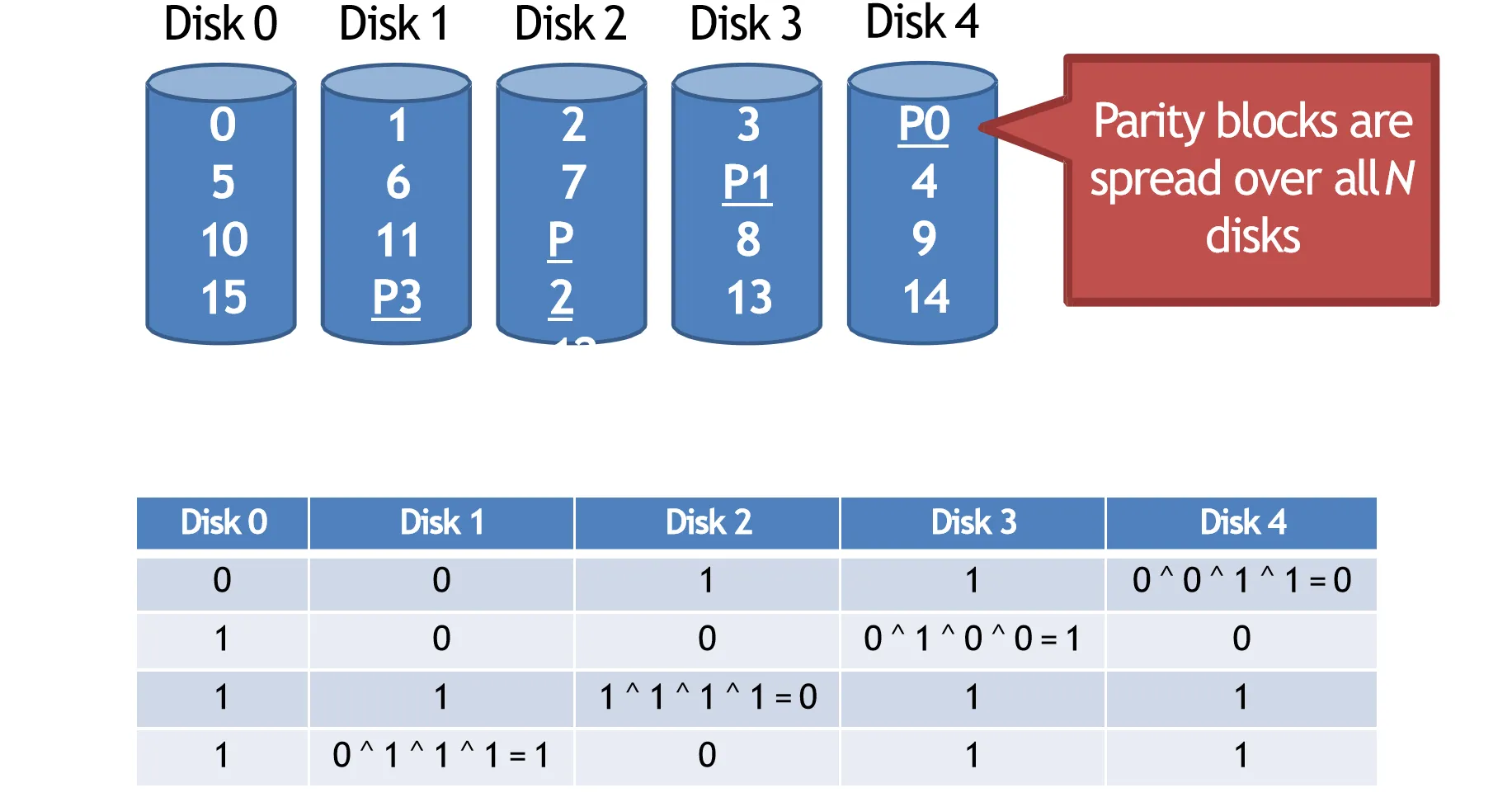
性能分析:
- 容量: 倍的单盘容量
- 可靠性:可以容忍最多 1 个盘坏掉
- 顺序读写性能: 每次有一个盘的该位置存储校验信息,不能存数据
- 随机读性能: 因为数据分散,所有盘都可以服务
- 随机写性能: 每次写要读写两个盘,每个盘要读写两次
最后RAID 0、1、4、5的对比如下表所示:
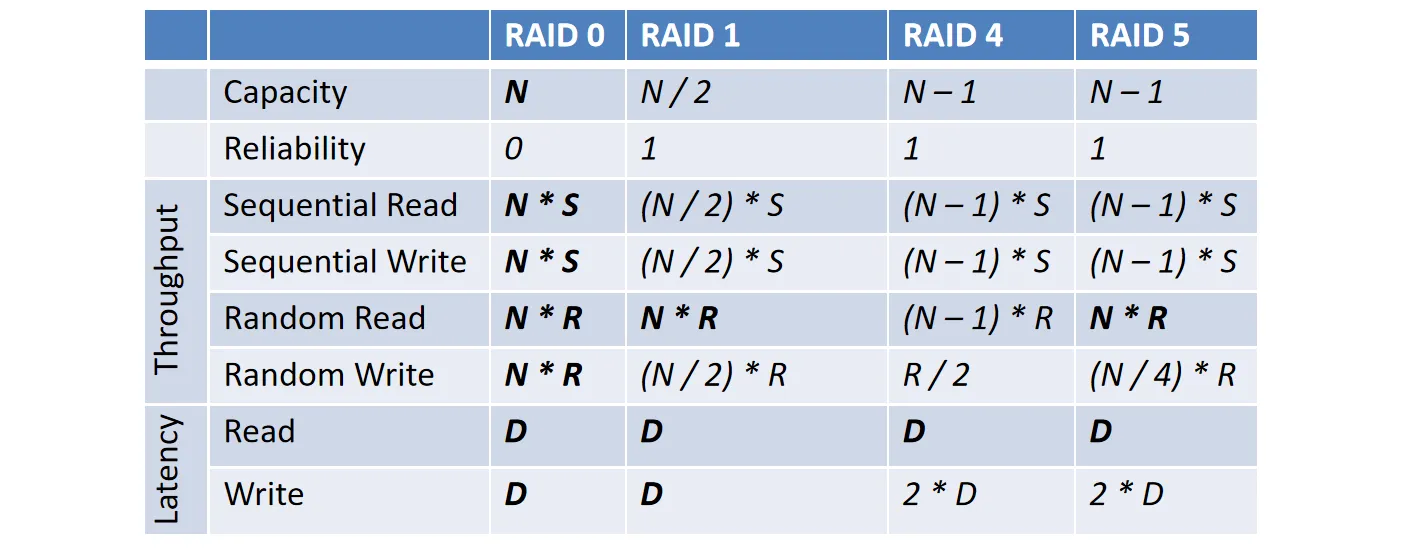
这里面多了一个Latency,这个也比较好理解,因为RAID 4、5 一个盘要读写两次,因此是2D
RAID 6#
和RAID 5类似,RAID 6引入了双重校验,保留两个校验信息,可以容忍最多两个盘坏掉
具体细节我们这里不讨论