本文内容基于 2025 秋季《计算机体系结构》双语班课程讲述,如有差错,欢迎指正
Performance Metrics#
体系机构里面关于性能有很多名词:
- Response time (aka execution time, latency): 响应时间,完成某个任务所需的时间
- 想要增强性能,就要减少响应时间,
- 如果我们说的性能是的倍,意味着
- Throughput: 吞吐量,给定时间内完成的任务数量
- 一般来说,减少响应时间会增加吞吐量(反之不一定)
- Clock rate: 时钟频率,单位Hz,表示每秒钟时钟周期数
- CPI: Cycles Per Instruction,每条指令平均需要的时钟周期数
- 一种用来比较同一种指令集不同实现的好坏的性能指标
- Effective CPI: 在一个程序中,考虑到不同指令有不同CPI的平均值
- 其中是第类指令的CPI,是第类指令在总指令中所占比例
- IPC: Instructions Per Cycle,每个时钟周期内执行的指令数
CPU Performance Equation#
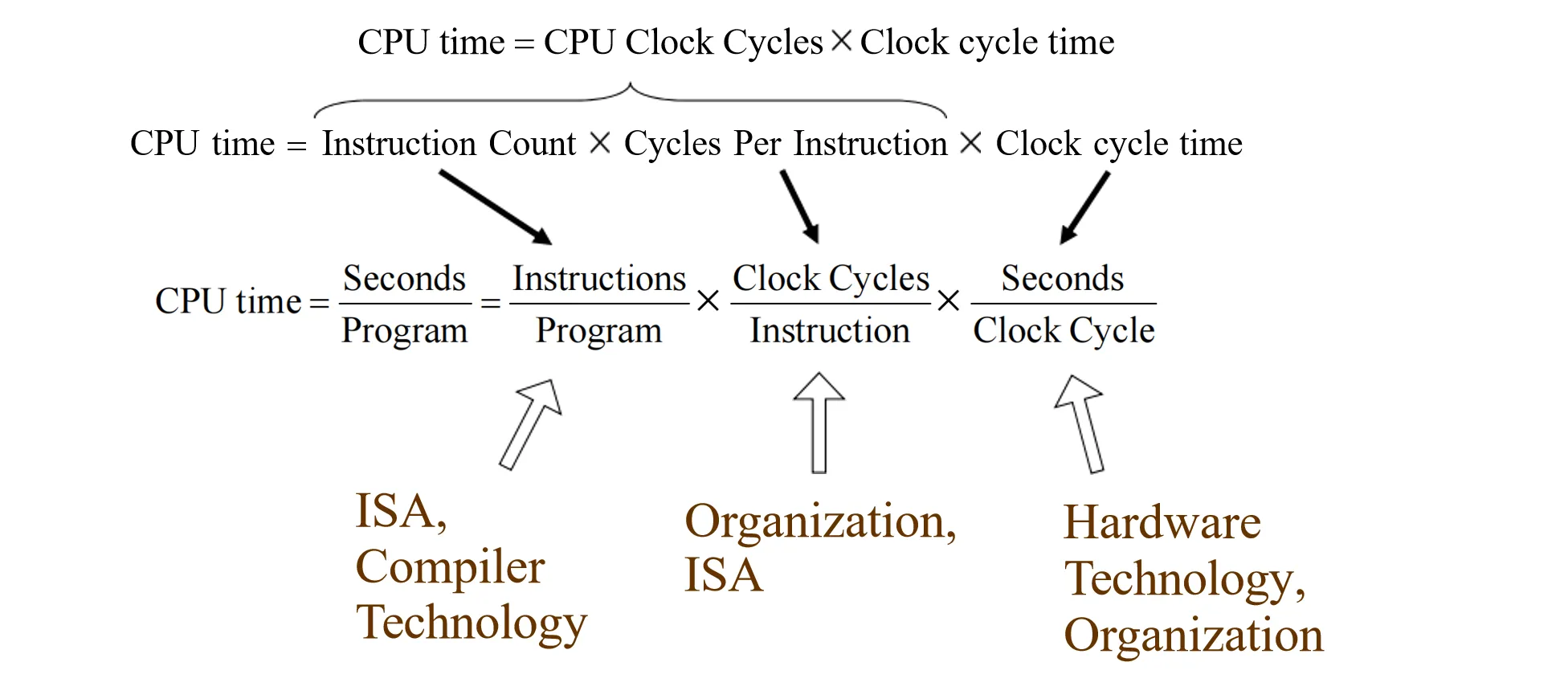
cpu 执行时间由三个要素决定:
- Instruction Count (IC): 指令数量,对于同一个程序,IC由ISA和编译器决定
- CPI: 每条指令平均需要的时钟周期数,取决于ISA和底层硬件实现
- Clock Cycle Time (CCT): 每个时钟周期的时间长度,取决于硬件实现和硬件制成工艺
这三个要素之间彼此有牵制,会相互影响,因此在做优化时需要权衡。
用 Effective CPI 的形式,上面的公式可以写成:
Amdahl’s Law#
加速比(Speedup)是用来衡量优化效果的指标,定义为优化前后的性能比值:
有时候我们常常对一个系统的某个部分进行优化,那么整体的加速比就会小于部分的加速比。这就是Amdahl定律所描述的现象
这里面的指的是被优化部分所花时间在整体中所占的比例
Amdahl定律告诉我们,优化时间占比大的代码,会有更显著的整体性能提升
RISC-V ISA#
CISC vs RISC:
- CISC: Complex Instruction Set Computer
- 指令长度不固定
- Programmer friendly
- 指令集复杂
- 对于硬件的实现要求高,每加一条指令都需要额外的硬件支持
- RISC: Reduced Instruction Set Computer
- 指令长度固定(RISC-V是32位指令)
- 引入load/store架构,运算指令只能在寄存器之间进行,只有专门的Load和Store指令才能访问内存
- 寻址方式有限
- 操作有限
RISC-V 的设计具有高度的模块化和可扩展性。它定义了一个最基础的整数指令集,仅包含加减法、跳转、Load/Store 等最基本功能。 在此基础上,用户可以根据需求选择添加标准扩展模块,如 M(乘除法)、A(原子操作)、F(单精度浮点)、D(双精度浮点)和 C(压缩指令)。 这种组合方式通过命名体现,例如 RV32I 代表基于 32 位基础整数指令集
User-Level ISA#
最简单的 RISC-V 指令集包括以下三类指令:
- 算术逻辑指令(Arithmetic,Logical,Shift)
- 数据传输指令(Load/Store)
- 控制流指令(Branch/Jump)
可以分为六种格式
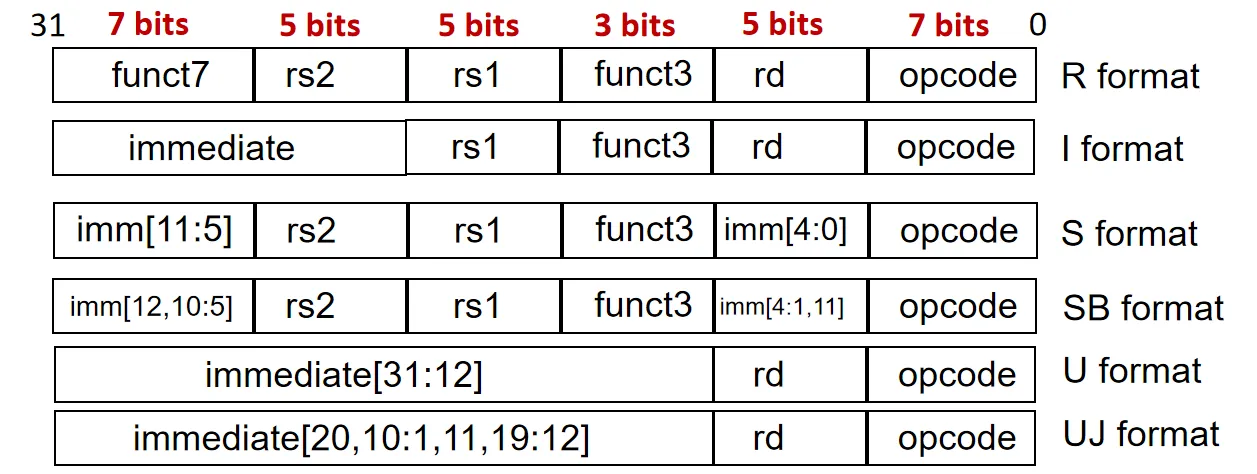
R-format:
比如寄存器加法指令:add rd, rs1, rs2,表示将寄存器rs1和rs2的值相加,结果存入寄存器rd
这类指令中用到了三个寄存器,由于RISC-V一共有32个寄存器,因此每个寄存器需要5位二进制数来表示(2^5=32)
另外操作码也分为了三个部分来表示:opcode(7位),funct3(3位),funct7(7位)。这与RISC-V指令集的不断扩展有关
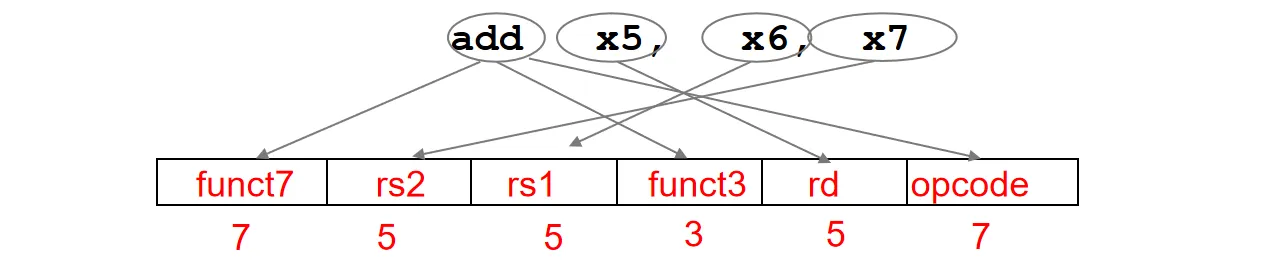
I-format&S-format:
RISC-V中的load/store指令分别使用I-format和S-format
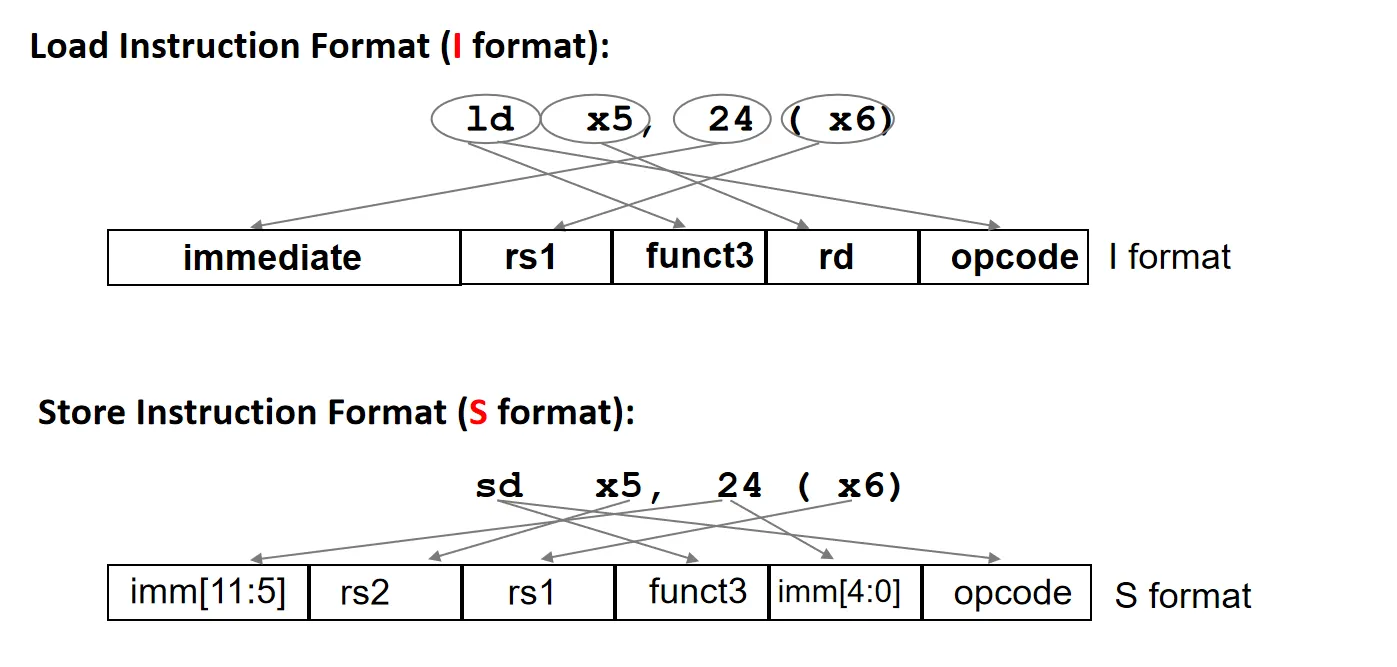
这里的ld\sd其实是load doubleWord和store doubleWord。
类似的还可以有lb\sb(load/store byte),lw\sw(load/store word)
访问的内存地址为address = rs1 + offset,这点与y86一样。offset是一个12位的有符号立即数
当我们把8位的数据加载到32位寄存器时(lb),对于高位会进行符号扩展;如果将寄存器中的低8位数据写入内存时(sb),会将低8位截断后储存
对于一些立即数指令,比如addi rd, rs1, imm,表示将寄存器rs1的值与立即数imm相加,结果存入寄存器rd。这种指令也可以使用I-format
但是注意到,I-format中的立即数是12位的有符号数,如果需要更大的立即数,就需要使用其他指令组合来实现
U-format
对于把一个大常数加载到寄存器,RISC-V提供了lui rd, imm指令,表示将立即数imm加载到寄存器rd的高20位,低12位补0

通过这个指令,我们可以把一个32位的常数分成两部分来加载:高20位通过lui指令加载,低12位通过addi指令(或者其他)加载
SB-format
RISC-V中的分支指令使用SB-format,比如beq rs1, rs2, offset,表示如果寄存器rs1和rs2的值相等,则跳转到当前指令地址加上offset的位置继续执行。
类似的指令还有bne(不等则跳转)
对于SB-format,比较有意思的一点是,立即数offset的编码方式比较特殊(见下图)

为了支持压缩指令集(C-Extension),指令地址需按 2 字节(16-bit)对齐。 因此,编码中的立即数实际上省略了最低位(bit 0 默认为 0),指令中存储的是 bit[12:1] 的信息,这扩大了跳转范围( to words)。
UJ-format
对于函数调用,与普通跳转的区别在于必须能够返回。 这需要保存调用处的下一条指令地址(Return Address)。有两条常用的指令:
JAL(Jump and Link):JAL rd, offset。该指令跳转到目标地址,同时将下一条指令的地址()保存到目标寄存器 rd 中。按照惯例,rd 通常使用 x1(即 ra 寄存器)作为返回地址寄存器。JALR(Jump and Link Register):JALR rd, offset(rs1)。这是一种间接跳转,目标地址为 。
一些应用场景:
JAL x1, offset:函数调用,跳转到 offset 处,同时将返回地址保存到 ra 寄存器(x1)JALR x0, offset(rs1):函数返回,从 ra 寄存器中获取返回地址并跳转JAL x0, Label:无条件跳转到 Label 处lui rd, imm+JALR x1, offset(rd):实现长跳转
UJ-format的立即数编码方式与SB-format类似,也省略了最低位
RISC-V Registers#
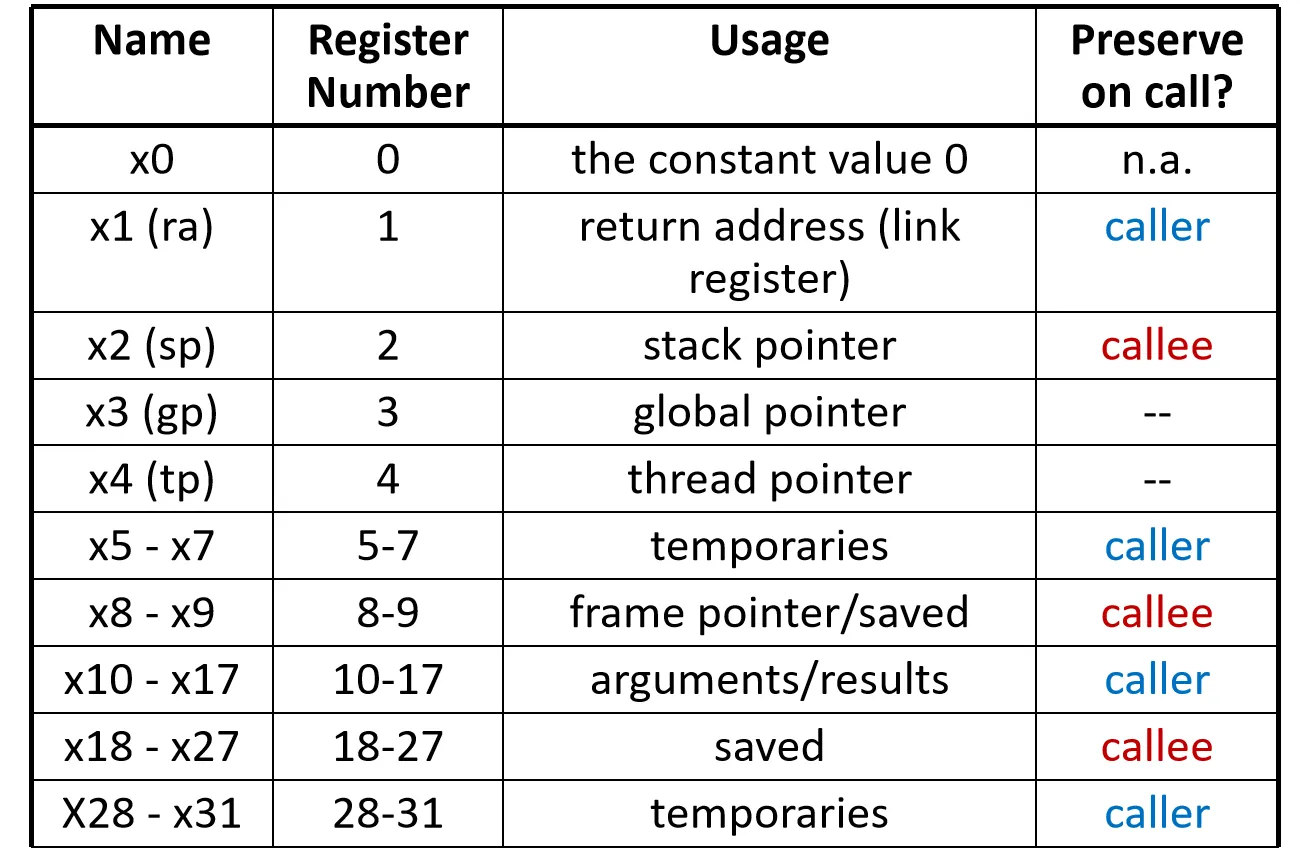 一些没太听过的寄存器
一些没太听过的寄存器
- global pointer (gp): 全局指针,用于访问静态数据
- thread pointer (tp): 线程指针,指向线程私有存储
从硬件实现的物理层面来看,寄存器堆(Registers File)通常包含 2 个读端口和 1 个写端口,包含32个通用寄存器
Caller-Saved vs Callee-Saved:
- Caller-Saved (临时寄存器): 由调用者负责保存和恢复
- t0-t6 (x5-x7, x28-x31)
- Callee-Saved (保存寄存器): 由被调用者负责保存和恢复
- s0-s11 (x8, x9, x18-x27)
Synchronization#
对于同步原语,CISC中有像C&S这样的指令,在RISC-V中也提供了两个原子操作指令:
lr.d rd, (rs1)(Load Reserved): 从内存加载一个值到rd,并在处理器内部标记该内存地址为“保留”状态sc.d rd, rs2, (rs1)(Store Conditional): 尝试将rs2的值存储到rs1中的内存地址。如果该地址自LR以来没有被其他处理器修改过,则存储成功,并将rd设置为0;否则,存储失败,并将rd设置为失败码- 里面的
.d表示操作的是double words,类似的可以有.w(word),.b(byte)
在使用这两个指令时的一些注意事项:
SC指令只有在保留的地址有效且该地址包含被写入的值时才会成功,例如;
lr.d t0, (a0)
sc.d t1, t0, (a1) # 失败,因为 a1 之前没有被保留过SC执行后会清除之前所有的保留状态,例如:
lr.d t0, (a0)
lr.d t1, (a1)
sc.d t2, t0, (a0) # 成功,把所有的保留状态都清除了,a0 和 a1 都不再是保留状态
sc.d t3, t1, (a1) # 失败,因为 a1 不再是保留状态