本文内容基于 2025 秋季《计算机体系结构》双语班课程讲述,如有差错,欢迎指正
DRAM Cells#
之前我们已经对DRAM cell的基本结构有了一定的了解,这里再次介绍一下
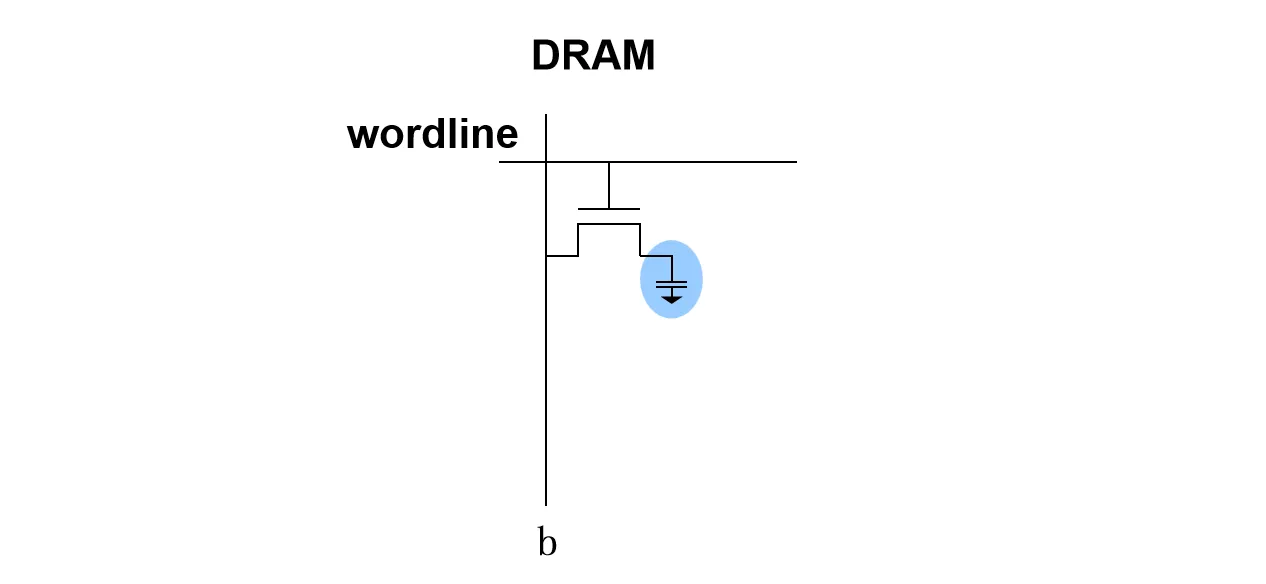
DRAM cell 由由一个晶体管和一个电容组成,晶体管充当开关,由Word Line控制其导通与截止;电容则是存储数据的容器,通过存储电荷量的多少来表示逻辑 或 。Bit Line连接在晶体管的一端,用于数据的读写
随着制程工艺的微缩,DRAM cell的尺寸不断缩小,其中的电容也减小。但这带来一个问题:电容变小意味着其存储的电荷量减少,更难被感知到,同时也容易出错。现代厂商一般会改变电容极板的形状,以增大正对面积来提高电容
DRAM Chip#
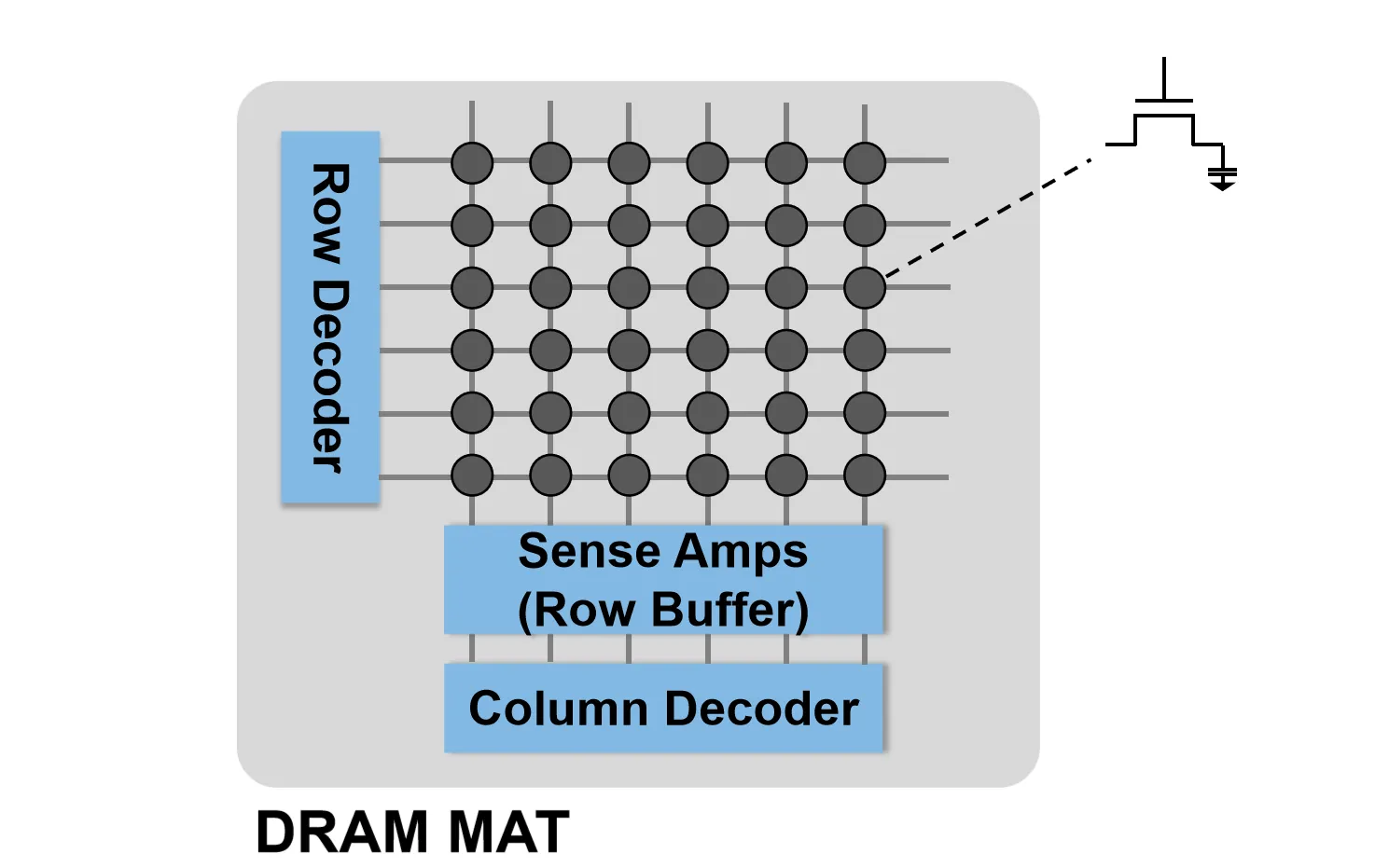
DRAM 内部不是直接将所有的cell连接起来,而是一种套娃的结构,从小到大依次为Mat、Bank、Chip、Rank
Mat像二维数组一样把DRAM cell组织起来,此外还包含了Row Decoder、Column Decoder和Sense Amplifier等电路
DRAM可以通过Row Address和Col Address来进行寻址。选择数据时,Row Decoder先根据Row Address选择数据对应的word line,信号从bit line进入Sense Amplifier中,Sense Amplifier负责检测bit line上的电压变化,并将其放大到可识别的逻辑电平,Sense Amplifier同时也作为row buffer缓存数据。接着,Column Decoder根据Col Address选择具体的列,从而完成对数据的读写操作
读写原理#
DRAM的读写相比SRAM更为复杂,有下面几个原因:
- Destructive Read:
- DRAM在读数据时,需要先在bit line上加一个的电压(precharge)
- 然后Row Decoder选通对应的word line,如果电容存的是 (高电平),电容向bit line放电,bit line电压略微上升;电容存的是 (低电平),bit line向电容充电,bit line电压略微下降
- 此时电压的变化量非常微小,Sense Amplifier将这个微小的电压差放大至完整的逻辑电平(或)
下图是读取1时的示意图:
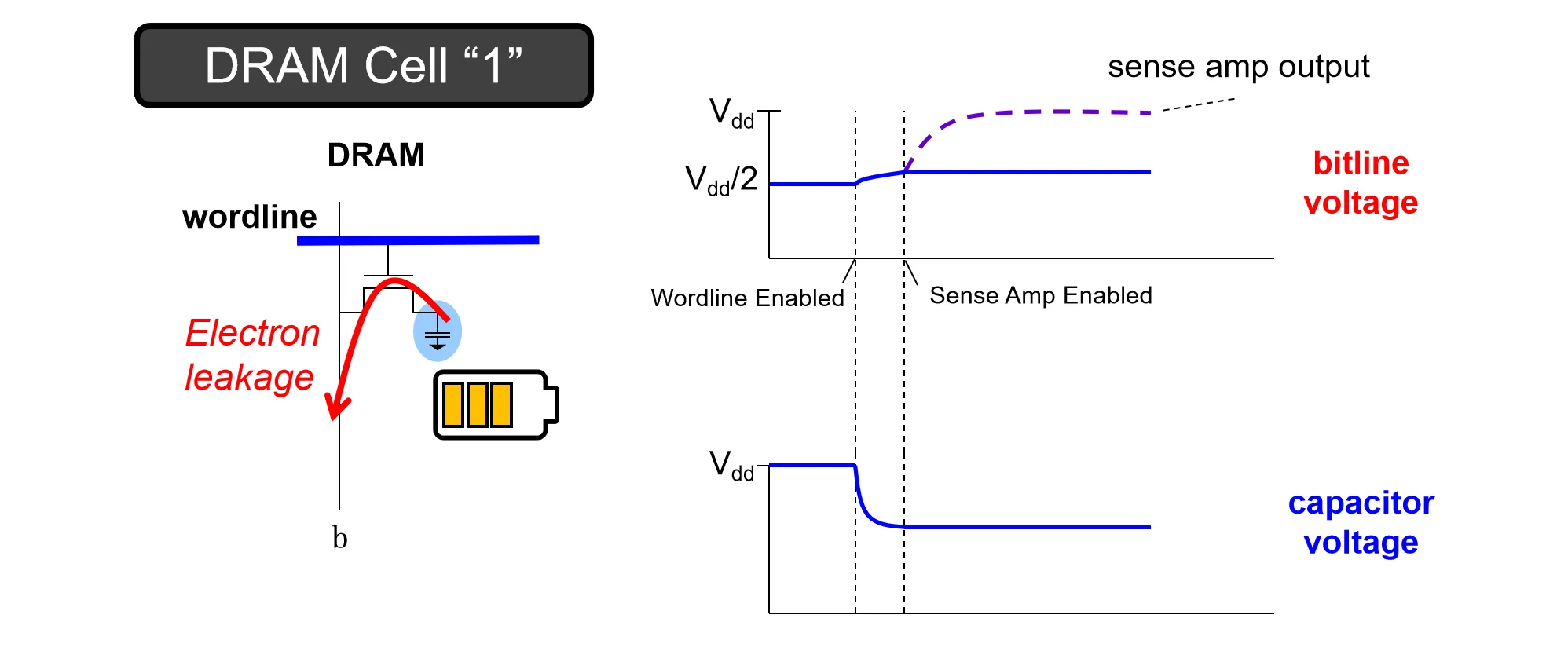
每次读取后,电容器内的电压都会变到 左右,再次读取时就分辨不出来。这种现象叫做 Destructive Read
- Gate Leakage:
- 即使在不进行任何操作的情况下,电容中的电荷也会随时间自然流失
- 在这种情况下,数据没有读取就会丢失
因此,我们需要周期性地对所有单元进行读取并写回,称为 Refresh
DRAM Hierarchy#
之前我们说过了MAT,在MAT上一级的层次叫做Bank。
Bank 内有Global Row Decoder/Column Decoder/Sense Amplifier,用来管理内部的MAT
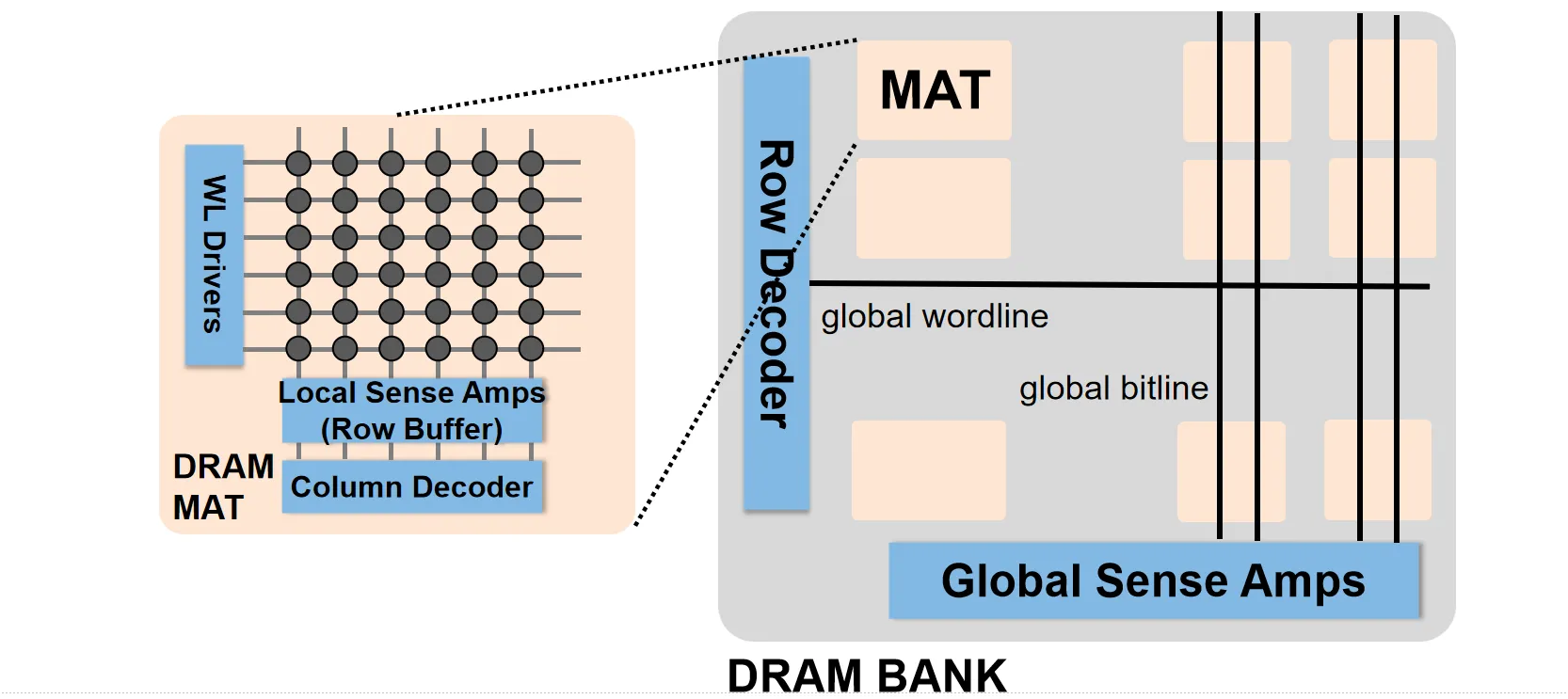
我们在内存条上看到的黑色方块即为 Chip。它包含多个 Bank 以及外围的 I/O 接口与控制逻辑,Bank上的数据通过这条线路传输到Controller。每个Bank可以独立工作,但是需要共享总线
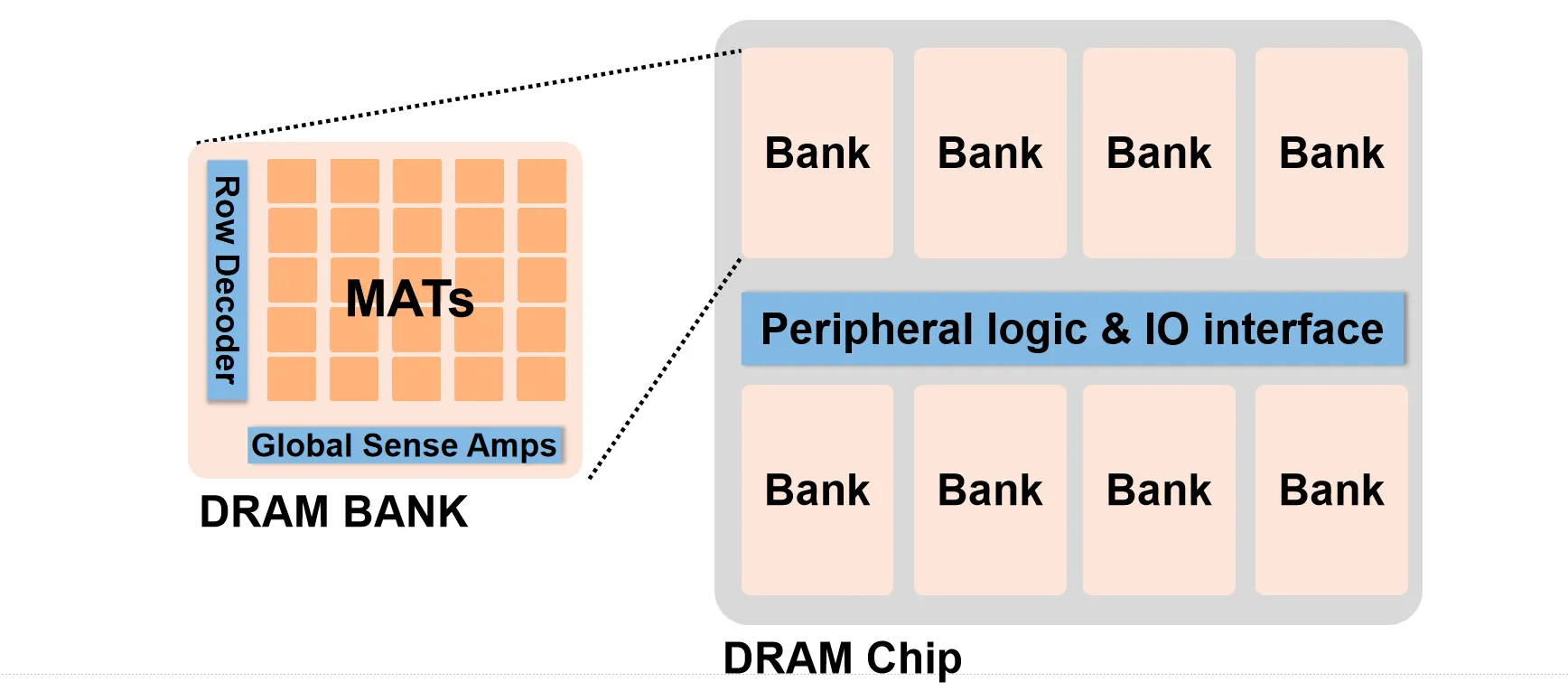
在Chip之上还有Rank的层次,这是内存模组上的逻辑分组概念。由于单个 DRAM Chip 的位宽通常只有 4-bit 或 8-bit,而 CPU 的内存总线宽度通常为 64-bit,因此需要将多个 Chip(例如 8 个 8 bit 的 Chip)组合在一起,协同工作以填满 64-bit 的数据总线。这一组协同工作的 Chips 被称为一个 Rank
一条DIMM条,即我们物理上插在主板上的内存条,可以对应多个Rank,取决于上面的芯片数
Memory Controller与DIMM条通过 Channel 连接,每个Channel可以有多条DIMM
DRAM Timing#
DRAM 在读写时可以分为三步:发送Row Addr,发送Col Addr,读取结果。下面我们看一下DRAM如何演进来使读写更高效,以及控制逻辑怎么设计
DRAM 演进#
最早的DRAM设计叫做 Asynchronous DRAM。读取需要分两步显式发送Row Address和Column Address,并通过 RAS 和 CAS 信号进行通知,在下降沿读取地址
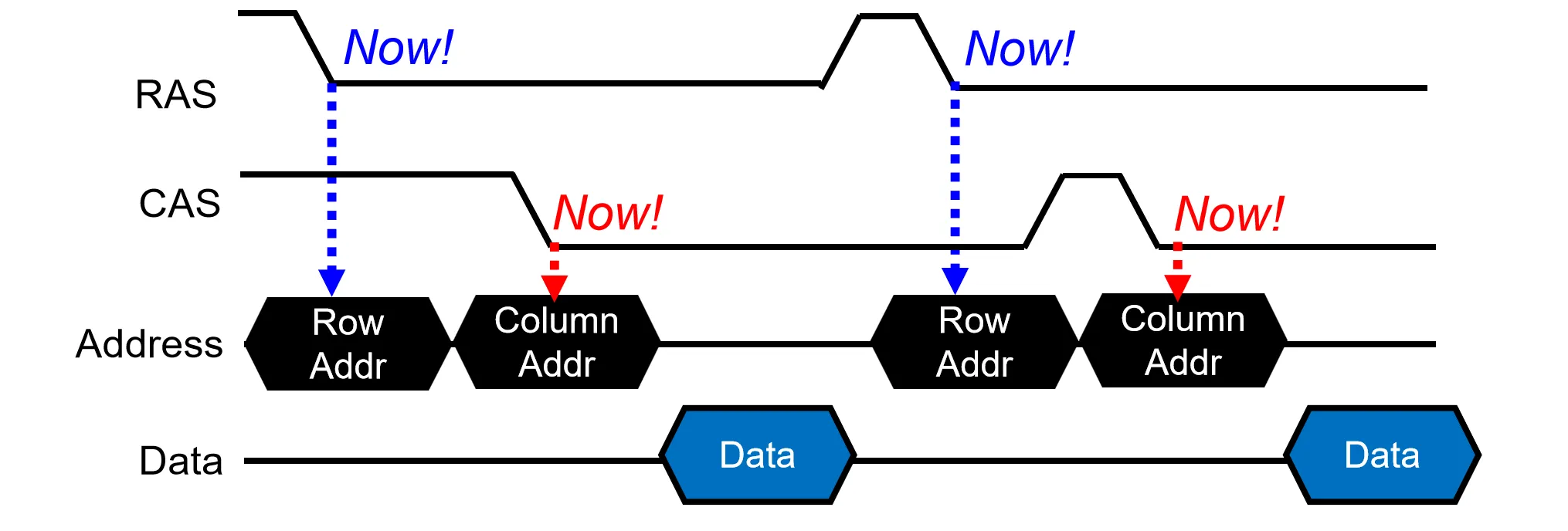
因为读取一般都是连续的,我们可以利用row buffer的特性,发送一次行地址后,连续发送多个列地址,从而快速读取同一行内的数据,这就是Fast Page Mode
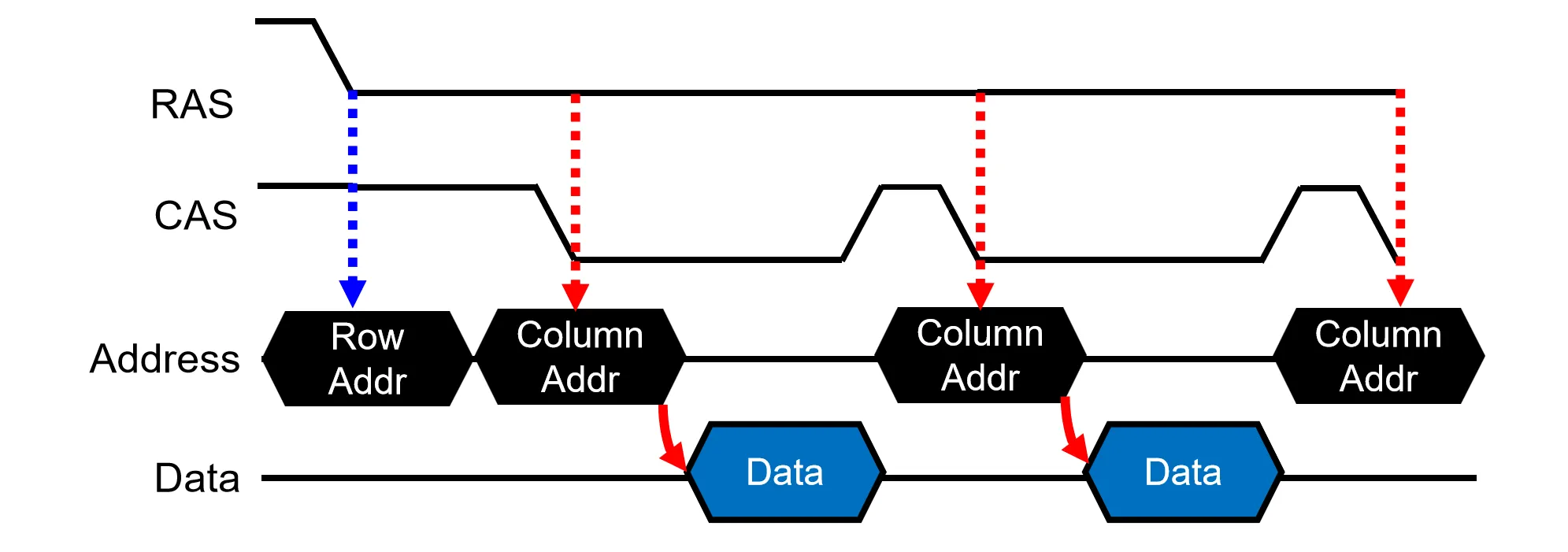
在上面两种设计中,Col Address和Data是串行的关系,但其实这两者之间不会有干扰,可以并行发送。于是,EDO(Extended Data Out)通过在Sense Amplifier 和 data line之间加入一个buffer(I/O gating),使Col Decoder与 Sense Amplifier 解耦,允许在当前数据输出的同时开始下一个列地址的译码
一次访存会填满一个CacheLine的数据(比如64 Bytes),但是DRAM一次Col Address读取的数据不够(比如8 Bytes)。这时可以与DRAM做约定(Brust mode),DRAM 内部维护一个count,发送一次Col Address就会自动读取一个CacheLine的数据,减少了发送Col Address的次数
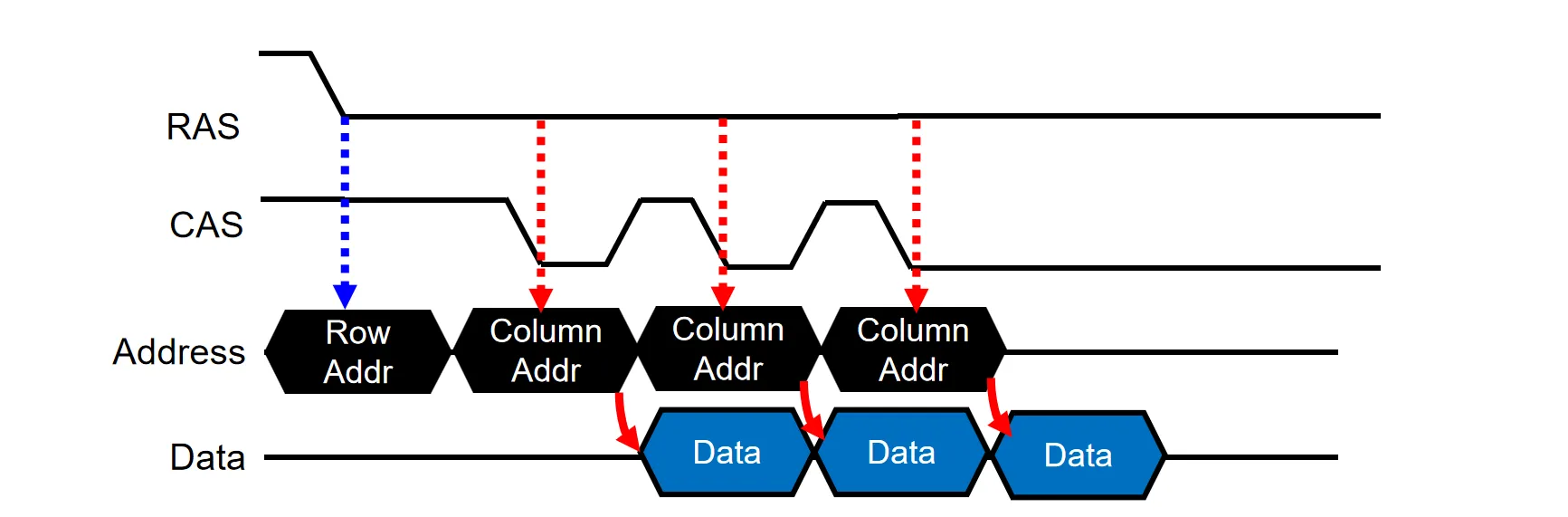
异步的DRAM难以保持时序,因此Synchronous DRAM (SDRAM)引入了时钟信号,所有的指令、地址和数据传输都和时钟对齐,同时将指令和地址合并在同一个总线
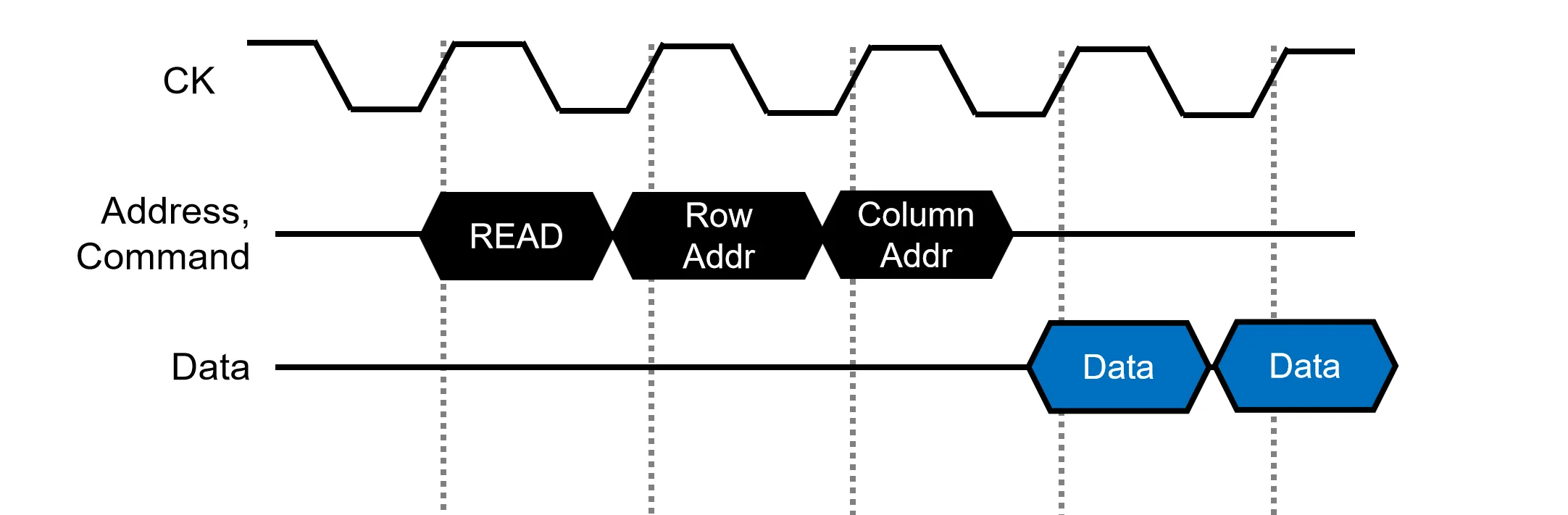
在这之后,DDR DRAM在 SDRAM 的基础上,利用时钟的上升沿和下降沿各传输一次数据,使得在时钟频率不变的情况下,数据传输速率翻倍(这里就不给图了)
DRAM 时序参数#
DRAM 的时序参数不是指某一操作需要花多长时间,而是描述控制器在发出一个指令后,必须等待多久才能发出下一个指令
下面看一下读写DRAM时三个步骤的时序参数:
- Row Activation:
- (RAS to CAS Delay):从发送激活指令到数据被完整读入 Sense Amplifier 并准备好进行列访问所需的最小等待时间
- (Row Access Strobe):从Row Activation开始,到数据被破坏性读取后完全恢复回电容所需的最小时间。在此时间内,不能对该 Bank 进行 Precharge r
- Column Access:
- (CAS Latency):从发送列地址到数据真正出现在数据总线上(可以进行DataBurst)的延迟
- (Column to Column Delay):发送两个Col Address 之间的时间
- :数据从Data Bus传出来的时间
- Precharge:在访问另一行数据之前,必须先关闭当前行,并将bit line电压恢复到
- (Row Precharge):发送Precharge指令后,直到bit line电压恢复完毕,可以进行下一次row activation所需的等待时间
- (Row Cycle Time):完整的一个行周期的最小时间,即 。这是对同一个 Bank 进行连续两次不同行访问的极限间隔
这些操作合在一起的时序如下:
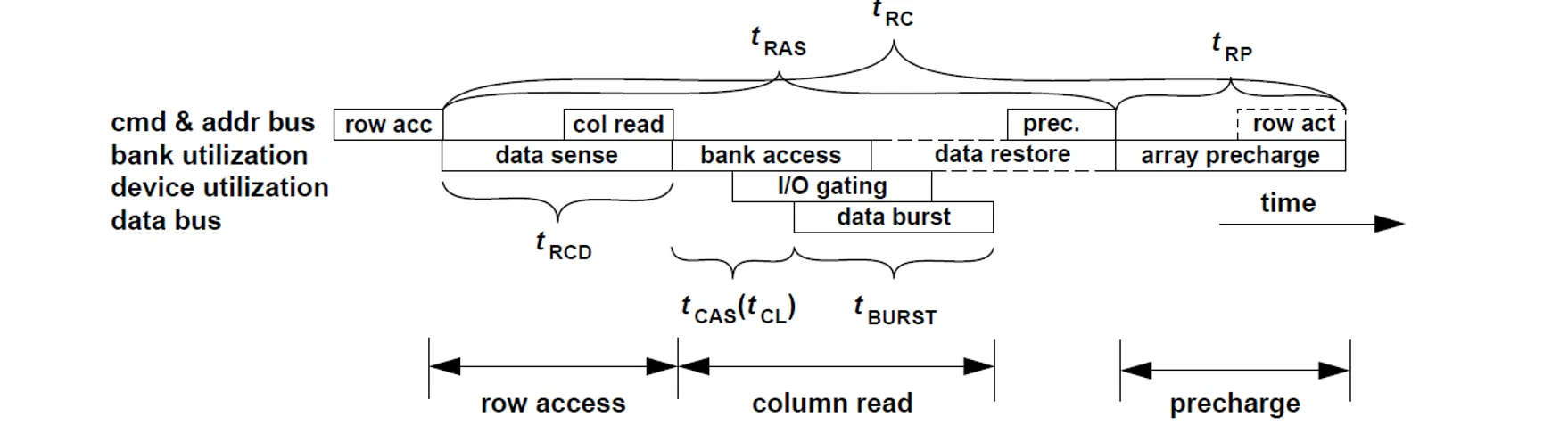
- 在实际上,为了增加并行性,可以在上一条命令还未完成时就发出下一条命令,这样可以隐藏一些时序延迟(比如Precharge可以在Column Access末发送)
此外,真实场景下DRAM的参数很复杂,这里不用了解细节
Trends of Technology#
DRAM设计时主要有几个目标:更大的容量、更高的性能以及更低的功耗。这里我们走马观花的看一下现在DRAM对于这几个目标的一些设计趋势(其中功耗这点与电路太密切就删掉了)
Increase capacity#
为了增加内存容量,一种方法可以将内存的Chip或Die堆叠起来,另一种方法可以在每个Channel上加上更多的DIMM条,这里我们主要看第二种
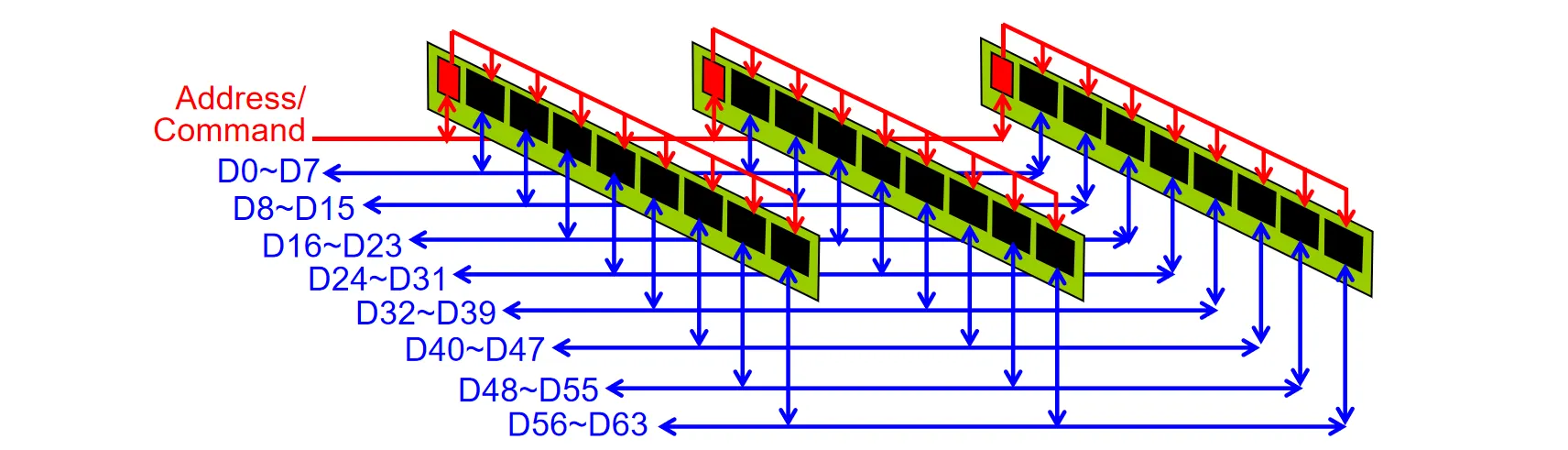
当Channel上连接的设备过多时,信号在传输过程中会发生严重的信号衰减问题
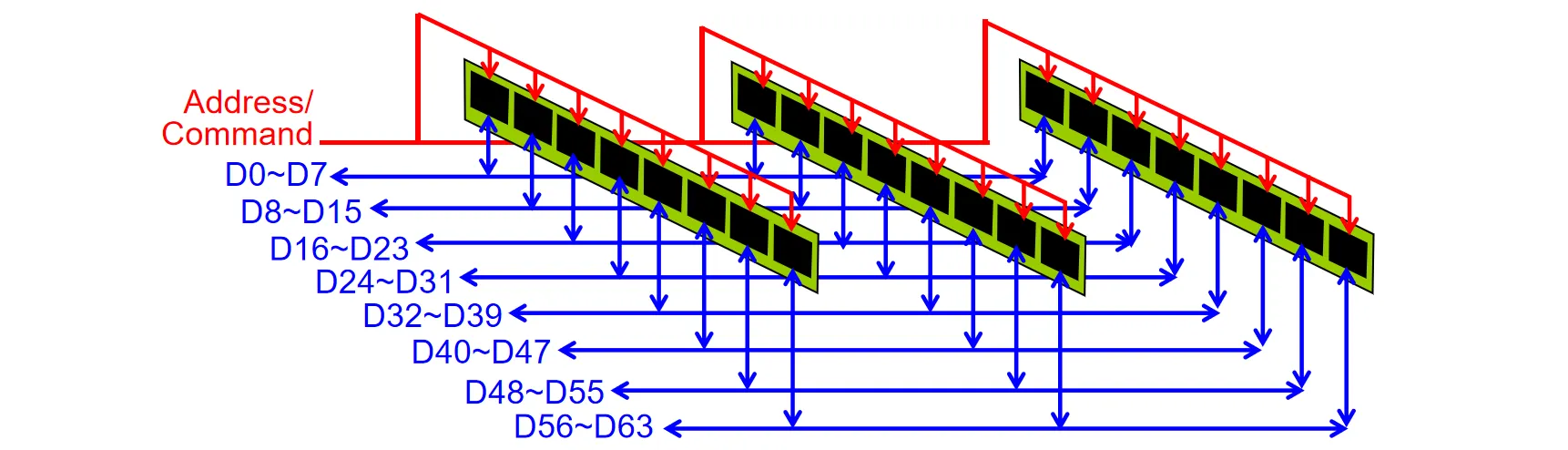
图中一根data line连接三个Chips,但一个command line需要连接24个Chips。控制信号衰减严重
一种解决方案叫做RDIMM(Registered DIMM),它在每个DIMM条上面引入一个寄存器芯片,控制信号先发给寄存器缓存,再由寄存器发给每个DIMM上面的Chip
RDIMM对控制信号做了缓存处理。为了进一步提升容量,FB-DIMM(Fully Buffered)引入了 AMB 芯片,将控制信号和数据信号一同交给 AMB 芯片来接管并在DIMM上转发
但是FB-DIMM的AMB芯片要处理海量信号导致功耗极高、发热严重,因此不再常用。
现在主流的一种解决方式叫做LRDIMM(Load Reduced),在 RDIMM 的基础上,进一步对数据总线进行了优化。它将 AMB 的功能拆解,控制信号由 Register 处理,数据信号由分布在模组上的多个小型芯片处理。减少了芯片的负担,降低功耗
Speed up memory#
Memory Controller(MC) 负责 CPU 和内存的交互。传统的MC位于CPU 外部的北桥芯片中,CPU 通过FSB总线访问 MC,但是由于FSB带宽问题,传输速率不够快。现代的CPU将MC集成在内部,有效降低了延迟,缺点是增加了耦合度,DRAM选择依赖于CPU
不仅是CPU,一些外部设备也会访问DRAM,在请求到来时。MC会做下面的一些事情:
- Arbitration:不同来源的指令对于延迟的敏感性不同,MC会对这些指令进行仲裁
- Address Translation:将物理地址映射为具体的 Rank、Bank、Row、Column 坐标
- Queuing & Scheduling:请求进入针对不同 Bank 或 Rank 的队列。调度器依据策略重排指令顺序
- Command Generation:将读写请求拆解为底层的 DRAM 命令序列,把命令以及数据发送给DRAM
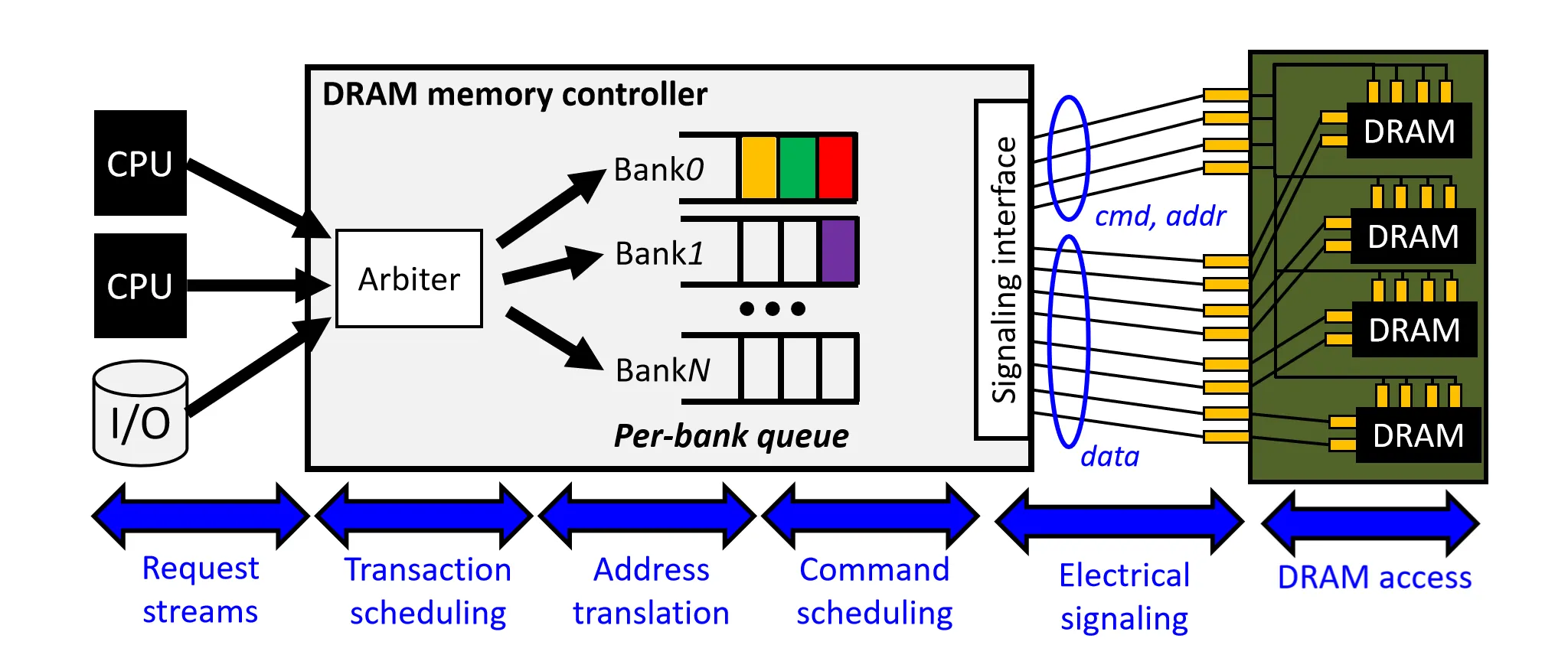
DRAM 调度策略
DRAM 访问中两个可以利用的特点在于:
- Row buffer Hit 的延迟远小于重新取一行的延迟,根据这一特点,有两种Row Buffer管理策略:
- Open-Page Policy
- 访问结束后,尽可能把数据保存在Row Buffer上,直到不Hit Row Buffer
- 这种方法利用了局部性,后续如果访问同一行,延迟低
- 但如果访问不同行,需要重新做Precharge,会增加延迟
- Closed-page policy
- 每次读写完成后,立即自动执行 Precharge 关闭行
- 平摊了Precharge的时间,但是没有利用局部性,适用于低局部性的场景
- Bank之间的访问可以并行
- 不同 Bank 之间共享总线,可以通过Pipeline的方式交错访问不同Bank,以达到更大总线利用率
Address mapping
根据地址,我们需要划分出该地址的Rank ID, Bank ID, Row ID, Column ID。不同的映射规则会有不同的性能
下面是一些常见的映射方法:
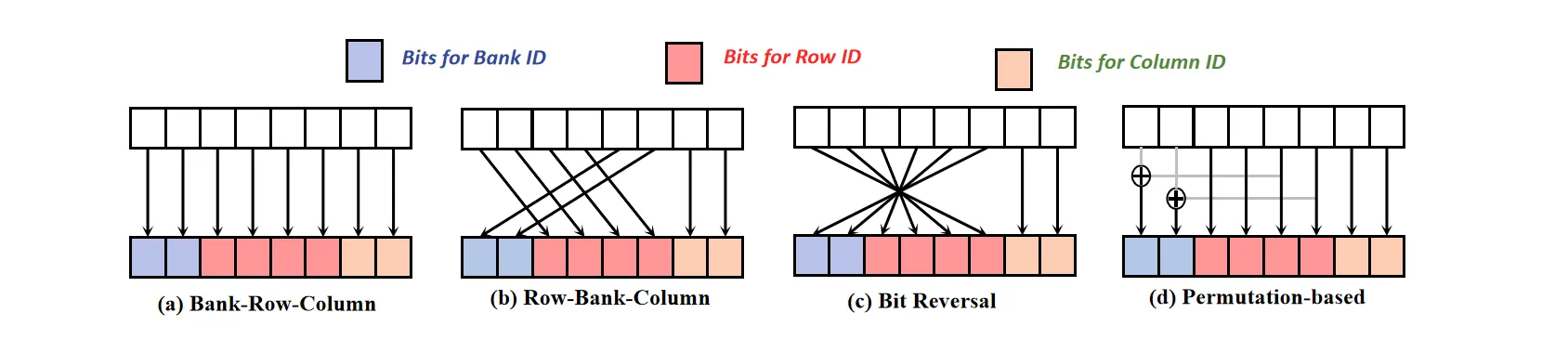
最后一种引入异或的映射方法可以将访问更均匀地打散到各个 Bank,在一些需要高并发的场景下(比如GPU)效果较好
内存调度的几个原则:
- 优先Row Buffer Hit的请求
- 优先处理延迟敏感的请求
- 保证没有饥饿
Multiple Channels
单通道的带宽有限,我们可以通过增加Channel的数量来提升带宽
早期的一种实现是用一个MC来控制两条通道,逻辑上视为一个 128-bit 宽的通道,这种形式在现在多处理器下会引入竞争,多个Core会竞争带宽
现在更多的是每个通道独立控制,多个CPU之间还可以通过UPI等方式访问其他CPU的内存
High speed interface#
DRAM 内部和外部的时钟周期不是一致的,DRAM 内部由于电容器的充放电操作周期较大,而随着MC的变快,DRAM 渐渐跟不上 MC 的速度
为了不改变内部周期的同时提升接口的速度,DRAM 内部设计了一个单元实现并行转串行。即把内部并行的低频率的数据转化为高频率的串行数据输出
在现在DDR5速度非常快的情况下,DRAM 面临几个挑战:
-
Power Consumption:功耗 。频率 大幅提升,为保持功耗可控,必须降低工作电压
-
Clock Skew (时钟偏移):高频下,时钟信号会发生变形,上升沿延后,与数据信号的到达时间出现偏差,可能导致数据读不到。
解决方案:引入 DQS (Data Strobe) 信号。DQS 作为“随路时钟”触发数据的读取,而非依赖全局时钟
- Signal Reflection (信号反射):信号在传输线末端反射,形成干扰波叠加。
解决方案:在 DRAM 内部加入终端电阻,将信号接地,防止反射波干扰
- Noise Signal:Clock Skew和Signal Reflection会带来噪声,我们需要预判信息完整性
Symmetrical T-Branch Topology:早期 DDR2 使用树状布线,保证各芯片路径等长以计算延迟。但长路线导致信号偏移
Fly-by Topology:DDR3引入。信号线串联经过所有芯片。路径不再等长,通过一些技术来预判并补偿不同芯片的延迟差异