本文内容基于 2025 秋季《计算机体系结构》双语班课程讲述,如有差错,欢迎指正
Introduction of Cache#
Memory Wall#
为什么需要高速缓存?
随着流水线、多发射以及乱序执行等技术的引入,处理器核心的性能呈现指数级增长。但与此同时,内存的访问时间却基本上保持不变。随着时钟频率的变快,这使得 CPU 等待一次内存访问所需的时钟周期数急剧增加,导致了“内存墙”问题
Memory Hierarchy Technologies#
不同存储介质之间具有访问模式的区别:
- 随机访问 (Random Access):如 SRAM 和 DRAM。其特点是访问存储阵列中任意位置的数据所花费的时间几乎相等
- 非随机访问:如磁盘、磁带或光盘。这些介质在读取数据前通常需要机械操作(如磁头寻道、盘片旋转),因此访问不同位置的数据延迟差异巨大,通常不适合作为直接的运算内存
关于DRAM和SRAM:
前缀中的Dynamic 和 Static 指的是数据存储的方式。DRAM 需要定期刷新以防止数据丢失(Dynamic),而 SRAM 不需要刷新(Static)。但是这两者都是属于易失性存储器(Volatile),即断电后数据会丢失
DRAM和SRAM的结构:
- SRAM的结构如下图所示,左右的两个晶体管相当于开关;中间的两个结构称作反相器,每个由两个晶体管组成,作用是把一个状态反转后从另一边输出。两个反相器首尾相接,形成了一个环路,数据在反相器之间状态不断变化,将数据保存起来。WL指的是word line,负责选通对应的cell;选通后就可以通过BL(bit line)读写数据
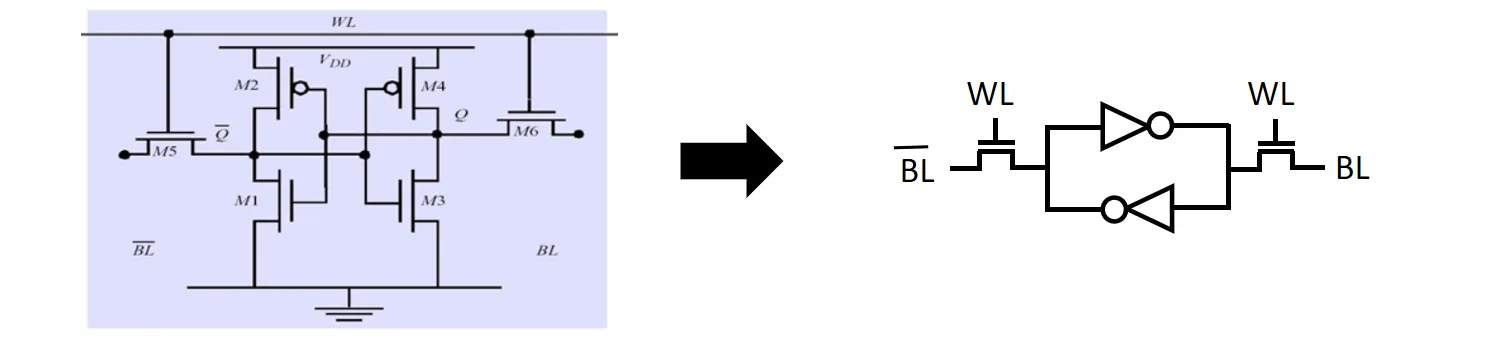
- DRAM的结构相对简单,主要由一个晶体管和一个电容组成。电容用于存储电荷,代表数据的0或1状态;晶体管则作为开关,控制对电容的充放电操作。由于电容会随着时间漏电,因此需要定期刷新以维持数据完整性;同时因为电容的电量很小,电压变化极其微弱,需要放大器对读出的信号进行放大;且由于读取过程会耗散电荷(破坏性读取),读完必须立即写回
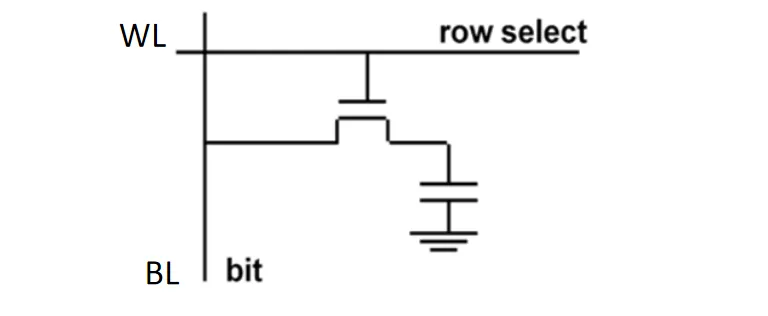
其他差异:
- 密度 (Density):DRAM由一个晶体管一个电容组成,而 SRAM 需要6个晶体管,因此 DRAM 的存储密度远高于 SRAM
- 功耗 (Power):SRAM 在反相器电压转换时会不断消耗电量,功耗较大;DRAM 虽需刷新,但在单纯存储状态下(不读写时)功耗相对较低
- 速度 (Speed):SRAM 极快(通常为纳秒级),两条bit line 同时充放电;DRAM 较慢(通常为几十纳秒),因为电容充放电需要时间,且读取后往往需要写回
- 成本:SRAM 单位容量昂贵,DRAM 相对便宜
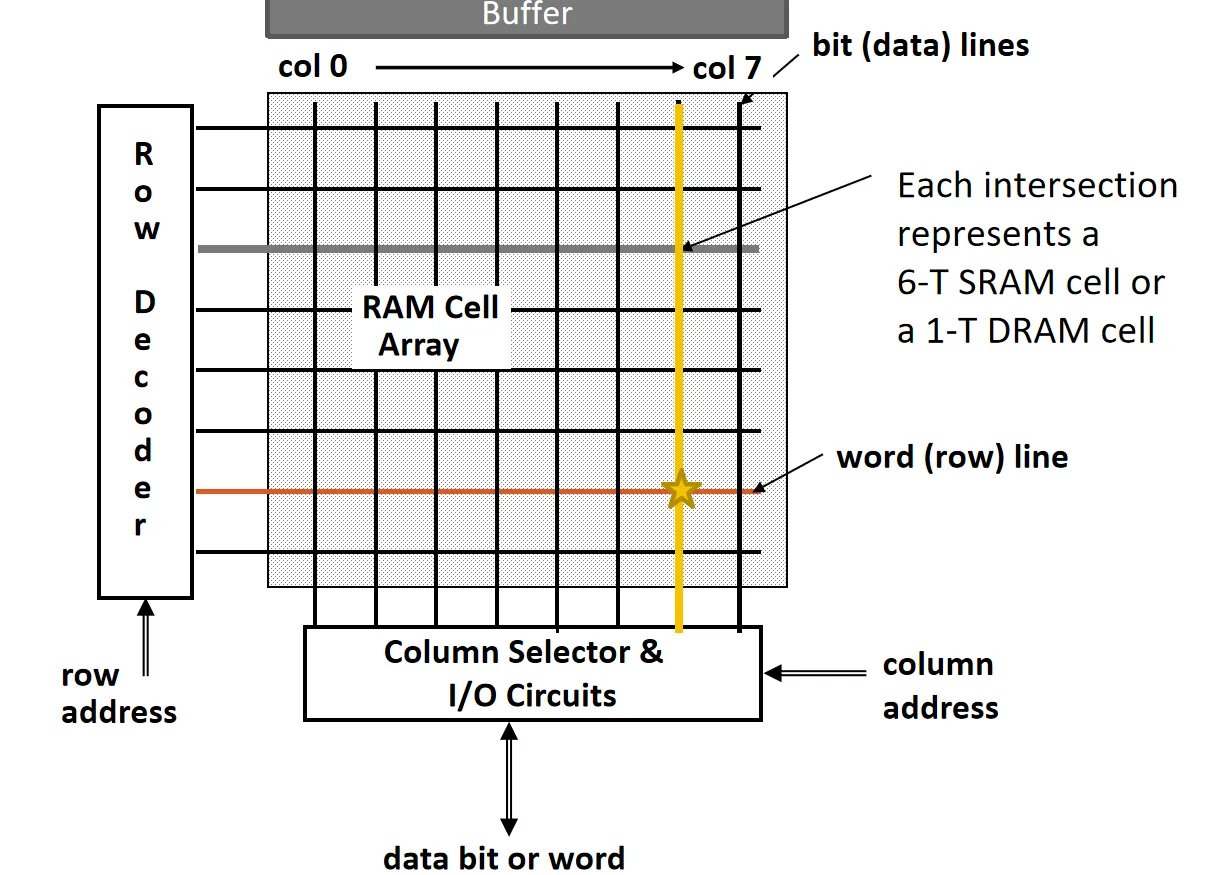
RAM Array Organization
大量的存储单元像二维数组一样排布。Row Decoder接收地址的一部分(Row Address),激活特定的 Word Line,选中一整行的存储单元,有时会先将这一行读到buffer上(DRAM)。Column Selector 通过 Column Address 从被选中的行中筛选出需要的数据位
Locality#
通常来说,大的存储速度较慢,快的存储一般很小。我们希望能得到一块又大又快的存储,因此需要利用局部性。
局部性主要分为两类:
- 时间局部性:如果一个数据项被访问,那么它很有可能在不久的将来被再次访问。比如循环结构中的指令、循环变量
- 对策:将最近访问过的数据保留在靠近处理器的 Cache 中
- 空间局部性:如果一个数据项被访问,那么与它地址相邻的数据项很有可能在不久的将来被访问。比如数组遍历
- 对策:当发生缺失需要从主存取数据时,不只取这一个字,而是将其附近的一整块数据一起搬运到 Cache 中
Cache Behavior#
访问 Cache 的两种结果:
- Hit:CPU 需要的数据在当前层级中找到
- Hit time:判断命中与否以及读取数据所需的时间,通常很短
- Miss:数据不在当前层级,需要去下一层级寻找
- Miss Penalty:处理缺失所需的额外时间,包括:从下层存储器将数据块替换上来所需的时间 + 将数据传输给 CPU 的时间。Miss Penalty 通常远大于 Hit Time
Cache Miss 的分类:
- Compulsory Miss / Cold Miss:
- 这是数据第一次被 CPU 访问,它从来没有在 Cache 中出现过。这是不可避免的。
- Capacity Miss:
- Cache 的总容量太小,无法容纳程序当前正在频繁使用的所有数据。当新的数据进入时,旧的数据必须被挤出
- Conflict Miss:
- 即使 Cache 还有空闲空间,但由于映射策略的限制,多个数据块竞争同一个 Cache 位置。如果这些数据块被交替访问,就会反复互相踢出
因此,考虑存储器性能后,我们对CPU性能的估计也需要修改:
包含指令Miss的penalty和数据Miss的penalty:
如果时钟周期加倍,但是存储访问时间不变,那么也会加倍,Penalty对整体性能的影响会增大
Basic Cache Design#
Cache 的设计核心在于如何高效地管理数据块。我们将 Cache 和 Memory 都划分成若干个固定大小的 Block,数据传输总是以 Block 为基本单位在 Memory 和 Cache 之间进行
设计一个 Cache 系统,我们需要回答四个核心问题:数据放哪里(Placement)、怎么找到数据(Identification)、缓存满了替换谁(Replacement)以及数据更新时怎么写(Write Strategy)
Placement & Identification#
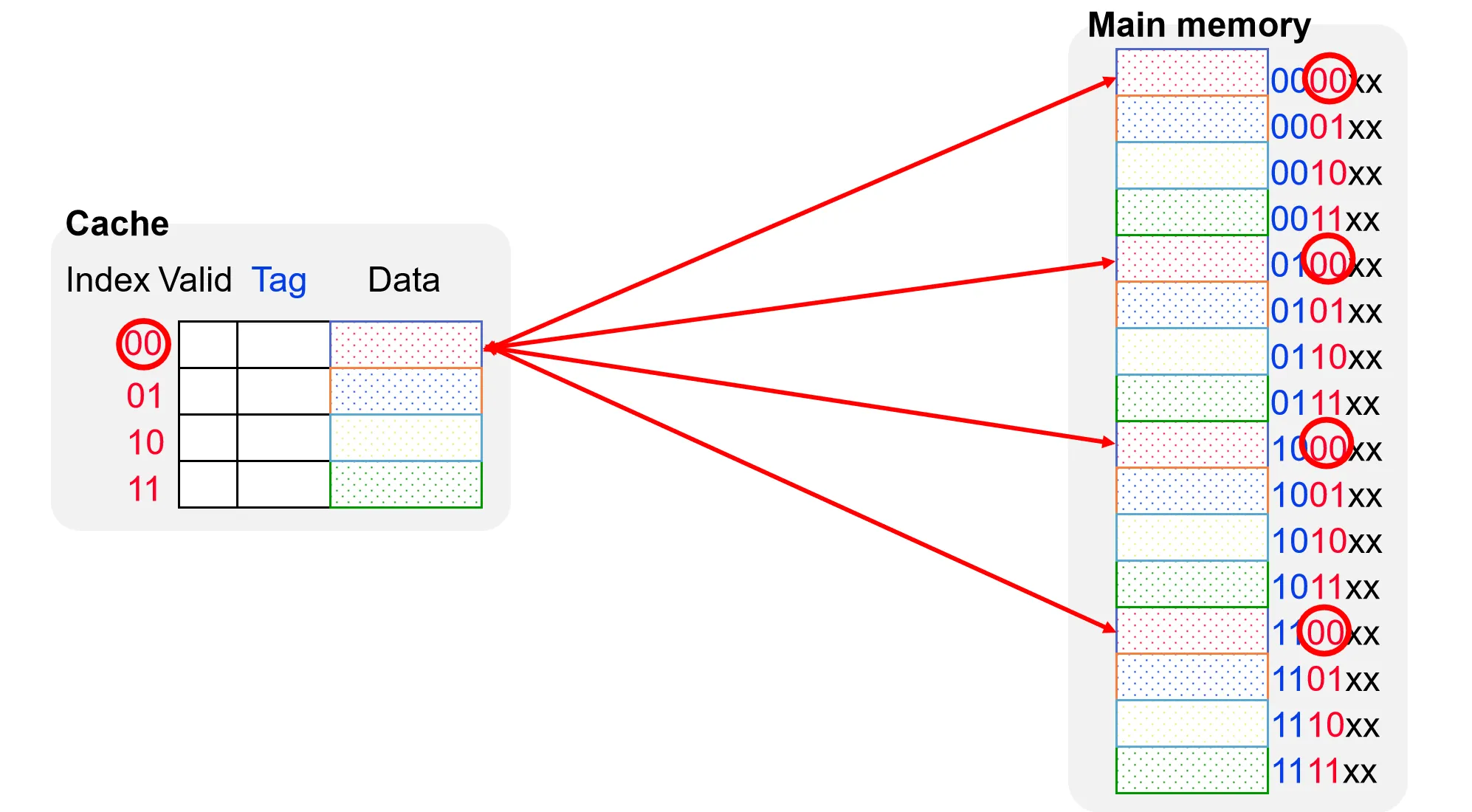
我们假设有一个6位的地址空间。一种传统的Cache设计会将地址划分为三个部位Tag、Index 和 Byte Offset

我们假设一个Cache 块的大小为一个word(4 bytes),那么Byte Offset 需要2位来表示。设Cache 总共有4个块,那么Index 需要2位来表示。剩下的2位作为Tag,用于区分不同的块
Direct Mapped Cache
直接映射是一种最简单的缓存映射策略,一个地址对应一个Cache Block
当我们要从Cache中取数据时,首先根据地址的Index部分定位到Cache中的特定块,然后比较该块的Tag与地址的Tag部分是否匹配。如果匹配且有效位为1,则表示 Hit,否则为 Miss
Direct Mapped Cache 虽然简单,但是效果不一定好。一种改进方式是增大Block Size,即一个Block内存多个word(利用空间局部性)
在发生 Compulsory Miss时,会一次性调入多个相邻的 Word。虽然这增加了 Miss Penalty,但通常能显著降低 Miss Rate。但是Block Size 并非越大越好,过大的 Block 会导致 Cache Line 数量过少,反而引发更多的 Capacity Miss 和 Conflict Miss
Direct Mapped Cache另一个缺点是乒乓效应。当多个频繁访问的数据块映射到同一个 Cache 位置时,会导致它们不断互相替换(Conflict Miss),造成高 Miss Rate
Set-Associative Cache
在组相连缓存中,我们将 Cache 划分为多个 Set,每个 Set 包含多路(Way)Cache Line。主存中的 Block 依然通过 Index 映射到固定的 Set,但在该 Set 内部,Block 可以放置在任意一路中
一个简单的二路组相联Cache:
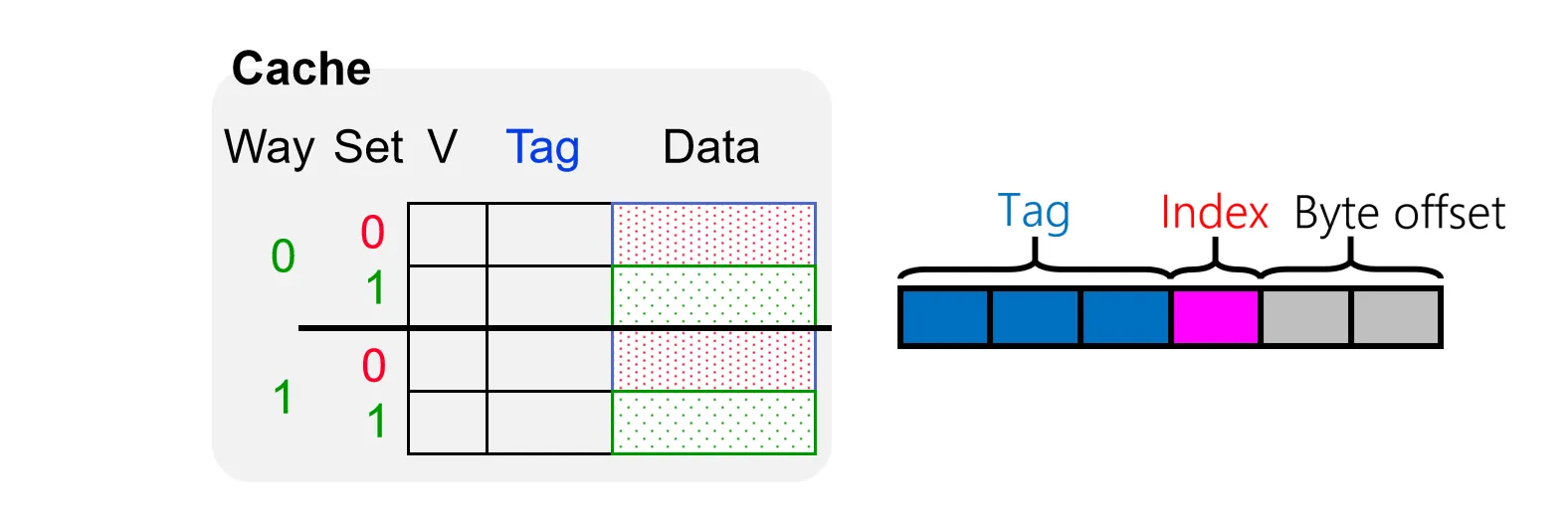
查找数据时,硬件需要:
- 使用 Index 选中对应的 Set
- 并行读取该 Set 中所有路的 Tag
- 使用多个比较器同时将这些 Tag 与地址中的 Tag 进行比对
- 只要其中任意一路匹配且 Valid,即为命中
这种设计增加了硬件成本和访问延迟,但显著降低了Conflict Miss
一般来说,随着路数的增多,Cache 的 Miss Rate 会降低。当Cache只有一个Set时,被称作全相联Cache,该 Set 包含了所有的 Block。数据可以放在 Cache 的任意位置。此时没有 Index,只有 Tag 和 Offset
Block Replacement#
当 Cache 发生缺失且对应的 Set 已满时,我们需要决定 Evict 哪一个 CacheLine 来腾出空间。对于直接映射缓存,因为位置固定,没有选择余地;而对于组相连和全相连缓存,则需要替换算法
常见的一些替换策略:
- Random: 随机选择一个 CacheLine 进行替换
- FIFO:替换最早的 CacheLine
- LRU(Least Recently Used):替换掉最长时间未被访问的 CacheLine。理论上比较优的一种策略(时间局部性),但实现较难
- NRU(Not Recently Used):替换最近不常使用的 CacheLine。对LRU的一种近似,但实现较简单
Least-Recently Used (LRU):
对于关联度较高的Cache,要实现一个精确的LRU,理论上需要知道所有CacheLine访问的时间,然后比较找出最老的。所花时间会较长,代价很大
为了近似LRU,人们提出了一些方法
Pseudo-LRU
利用二叉树的思想记录访问历史。
假设有四路,把这四路放在二叉树的叶子上,中间三个节点记录状态
- 0表示左侧的叶子更旧
- 1表示右侧的叶子更旧
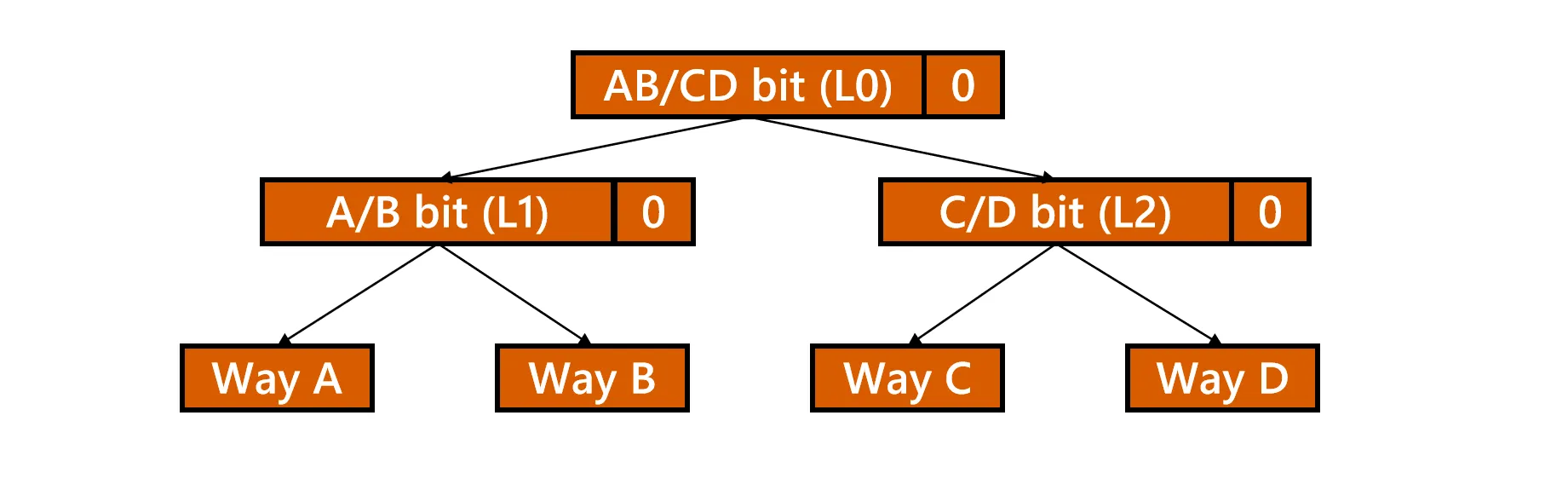
- 每次访问时更新路径上的状态位(指向未被访问的另一侧)
- 替换时,顺着状态位指向的“旧”方向寻找叶子节点,即为 victim
只需少量的bit就可以模拟LRU,时间复杂度
Clock Algorithm
将 CacheLine 看作一个环形列表,每个 CacheLine 有一个 Reference Bit
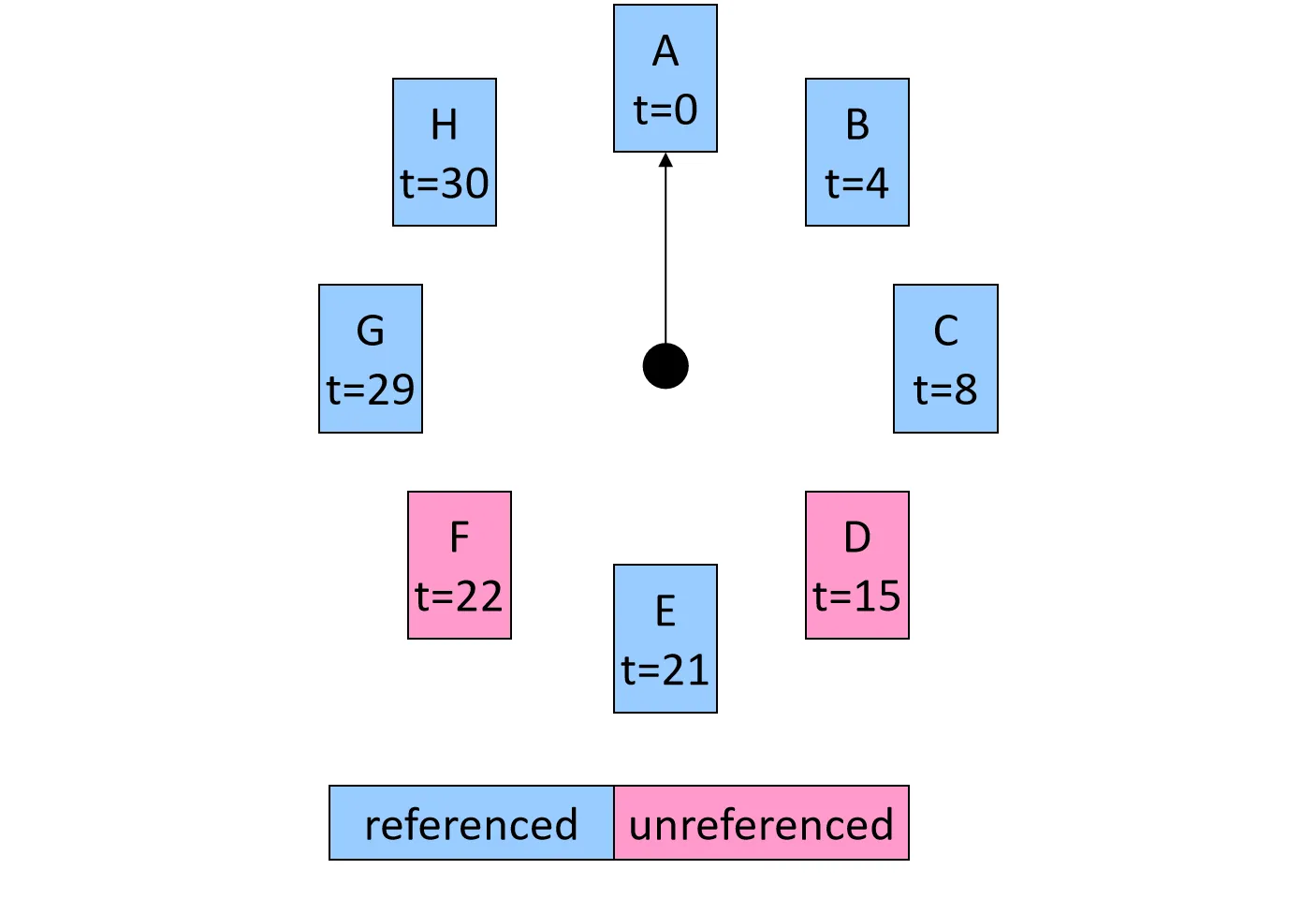
- 每次访问某行,将其引用位置 1
- 替换时,指针像时钟一样移动
- 如果遇到引用位为 1,将其清零,指针继续移向下一个
- 如果遇到引用位为 0,则该行被选为替换对象
实现比较简单,但是需要依次扫描,选择的时间不确定
Write Strategy#
写操作比读操作更复杂,因为需要维护 Cache 与 Memory 的一致性
Cache Hit时,Cache上已经有所需的数据,要做的是将数据更新。有下面两种策略:
- Write Through:同时更新 Cache 和 Memory
- 优点:实现简单,Cache 和 Memory 数据始终一致
- 缺点:Memory 写入慢,拖慢 CPU
- 优化:使用 Write Buffer。CPU 将数据写入 Buffer 后立刻返回,由 Buffer 异步写入 Memory。只有当 Buffer 满时 CPU 才会被阻塞
- Write Back:只更新 Cache,不立即更新 Memory
- 需要一个 Dirty Bit 标记该 Block 是否被修改。只有当该 Dirty Block 被 Replace 时,才将其写回 Memory
- 优点:速度快,显著减少 Memory 带宽占用
- 缺点:实现复杂,数据存在不一致风险
当要写入的数据不在 Cache 中时,也有两种策略:
- Write Allocate
- 先把对应的 CacheLine 从 Memory 读入 Cache,然后再在 Cache 中更新数据(基于局部性假设,认为写后通常会伴随读)
- 通常与 Write Back 搭配使用
- No write Allocate
- 跳过 Cache,直接写入 Memory。Cache 中不保留该数据。延迟长
- 通常与 Write Through 搭配使用
Cache Optimizations#
Cache 优化的核心在于降低平均内存访问时间(Average Memory Access Time,AMAT),根据公式
我们可以从三个方面对于Cache进行优化:缩短命中时间(Hit Time)、降低缺失率(Miss Rate)以及减少缺失代价(Miss Penalty)
Miss Penalty#
Multi-level Caches:
在CPU与主存之间再加一级缓存,填补鸿沟。比如在L3 Cache和主存之间再加一级L4 Cache;在主存和二级存储之间加一级Storage-Class Memory (SCM)
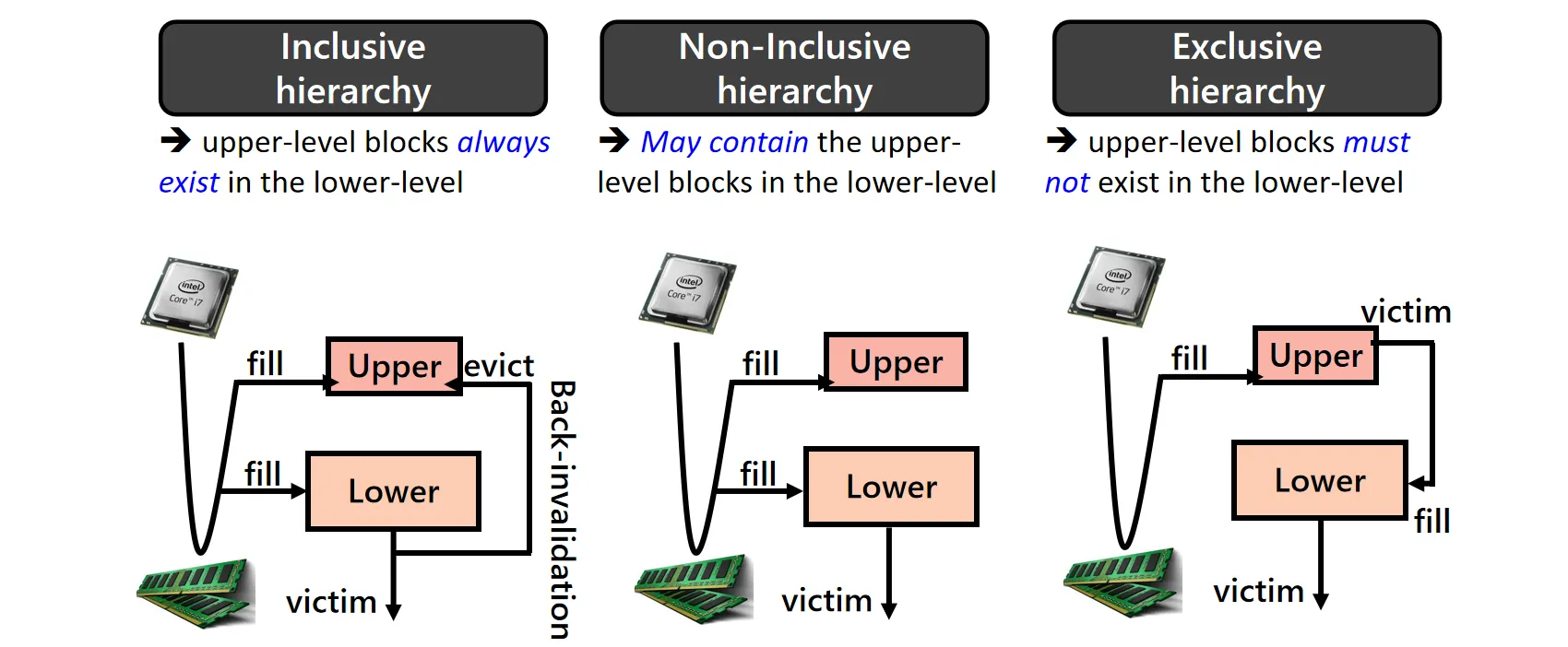
多级Cache之间数据的包含策略会影响数据管理的复杂性,常见的有三种策略:
- Inclusive Hierarchy:在这种策略下,上层 Cache(如 L1)的数据必定是下层 Cache(如 L2)的子集。如果 L2 中的某个块被替换,系统必须也将 L1 中对应的数据无效化。这种设计的优势在于管理简单;但其缺点是空间浪费,同一份数据在多级 Cache 中都有备份
- Non-inclusive Hierarchy:它允许上层 Cache 存储下层 Cache 中没有的数据。当 L2 发生替换时,数据虽然被移出 L2,但仍可保留在 L1 中。这种方式减少了不必要的 invalidation 操作,提升了 Cache 的整体性能
- Exclusive Hierarchy:这是最为极端的策略,要求上层 Cache 和下层 Cache 的数据完全不重叠。当数据在 L1 被替换出来时,才会被写入 L2。这种设计最大化了有效的 Cache 容量,因为没有数据冗余,但代价是管理极其复杂
Early Restart & Critical Word First
CPU想要访问的一般是Block中的某个word,我们没有必要等到Block全被load后再把数据给CPU
- Early Restart:按照正常顺序load Cache Line,但一旦所需的特定 Word 到达,立即发送给 CPU 恢复执行,其余数据在后台继续load
- Critical Word First:优先load CPU 急需的那个 Critical Word,收到后CPU立即恢复执行,然后再填充 Cache Line 的其余部分
Combining Writes
将多个针对连续地址的小块写操作合并为一个大的写请求,一次性写入内存
通常是基于MTRR技术,将写分为不同部分,如:
- UnCacheable(UC),不经过缓存直接写内存
- UnCacheable Speculative Write-combining(USWC),越过缓存但写入Write Buffer
- WriteBack(WB),WriteThrough(WT)
对于USWC的写操作可以使用合并写优化
Non-Blocking Cache
当发生 Cache Miss 时,CPU 不应完全停滞,而应继续检查后续指令是否可以执行,并处理他们的Load/Store请求
为了支持这一特性,硬件引入了 MSHR (Miss Status Holding Registers)。它记录当前所有未完成的 Memory request 请求状态。
- 允许多个请求并行进行,MSHR对应多个Cache bank,可以同时访问这些bank
- 如果后续指令访问的是同一个缺失的 Block,MSHR 会将它们合并,只向下一级存储发送一次请求,数据返回后同时满足所有等待的指令
Miss Rate#
Hardware Prefetching
利用硬件单元监测访问模式,提前将可能需要的数据放入Cache
比如对于连续的访问,系统维护一个FIFO的流缓冲区,自动预取当前块的后续 N 个块。如果在流缓冲区中命中,则直接将数据移入 L1
Cache-friendly Compiler
软件层面可以通过改变代码结构或数据布局来提升局部性
- 循环交换(Loop Interchange):对于多维数组访问,如果内层循环导致内存地址跳跃,编译器可以交换循环嵌套的顺序,使得数据按照内存存储的顺序被连续访问(比如二维数组访问行优先/列优先)
- 循环融合(Loop Fusion):将两个共享变量且循环域相同的独立循环合并为一个。这样,第一个循环加载的数据可以直接被第二个循环复用
- 数组合并(Merging Arrays):将两个被连续访问的独立数组合并为一个结构体数组。这使得同一索引下的两个数在内存中相邻,优化了空间局部性
Hit Time#
Virtually Indexed Cache
传统的缓存需要先完成虚拟地址到物理地址的转换才能开始索引,我们可以直接使用虚拟地址的一部分来索引 Cache
Trace Cache
在指令缓存上,把多个不连续的指令块打包成一个连续的 trace CacheLine,使得CPU可以一次取出多条指令