本文内容基于 2025 秋季《计算机网络》课程讲述,如有差错,欢迎指正
可靠传输的基本概念#
问题背景#
- 网络层的不可靠性:底层信道(如 IP 层)是不可靠的,主要面临三个问题:
- 数据出错:比特翻转(通过校验和检测)
- 数据丢失:路由器缓冲区溢出导致丢包
- 数据乱序:多路径传输导致到达顺序不一致
- 传输层目标:在不可靠的底层信道之上,提供可靠、有序、无差错的数据传输服务(逻辑管道)
- 适用范围:不仅限于 TCP,也适用于链路层、应用层(如 TFTP)、RDMA 等
基本假设#
-
计算机网络中对底层不可靠信道的假设
- 通讯链路会丢失信息
- 消息会发生乱序
- 通讯数据在传输过程中可能发生随机的错误,但能通过校验技术进行检测
-
不考虑的场景
- 数据在通信中可能遭到有意的篡改,且无法通过校验检测
- 收到的数据可能不是来自发送方,而是某第三方编造
一些接口名称以及功能:
rdt_send():上层应用调用,请求发送数据udt_send():传输层协议调用,通过不可靠信道(Unreliable)发送数据包rdt_rcv():下层信道调用,当数据包到达接收端时触发deliver_data():传输层协议调用,将正确的数据交付给上层应用
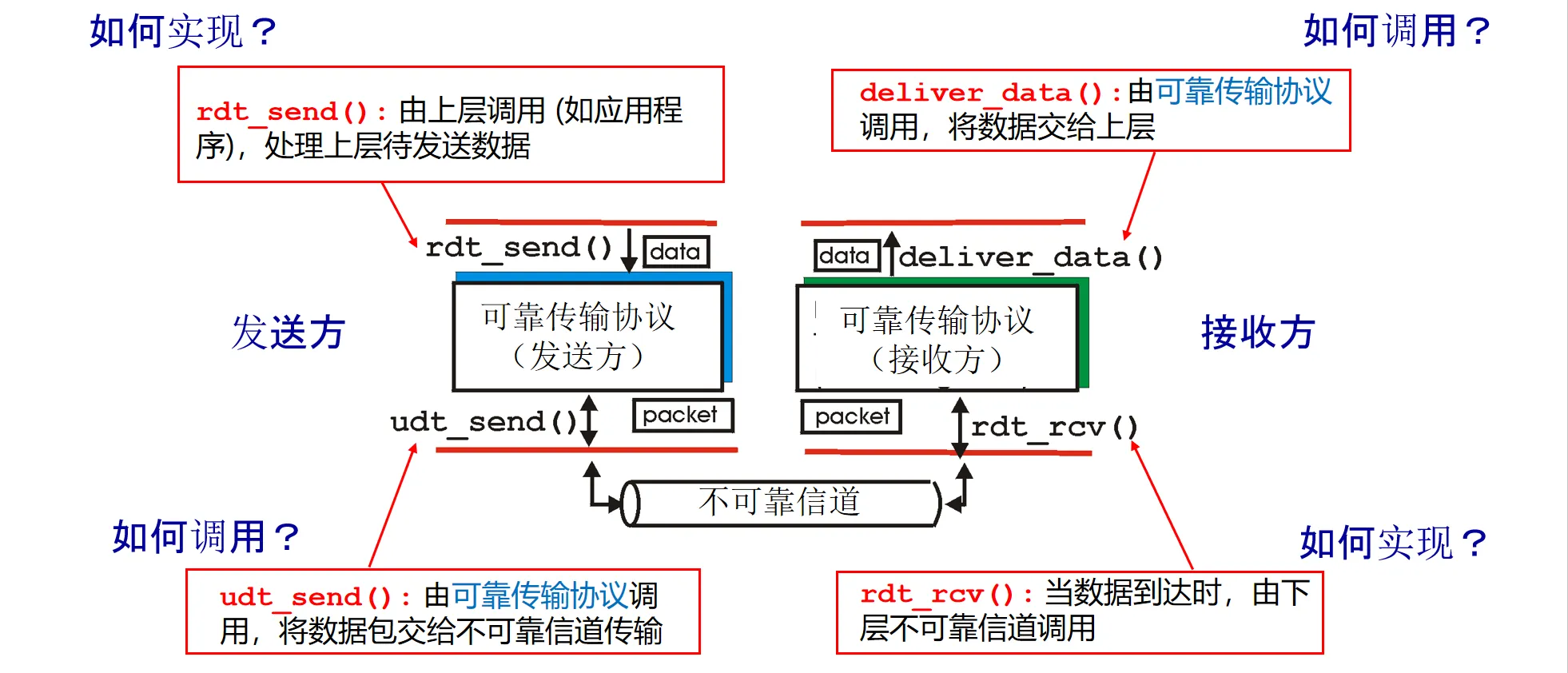
一般的可靠性方案#
rdt1.0 到 rdt3.0 协议族,通过逐步放宽对信道的假设,推导出可靠传输所需的机制
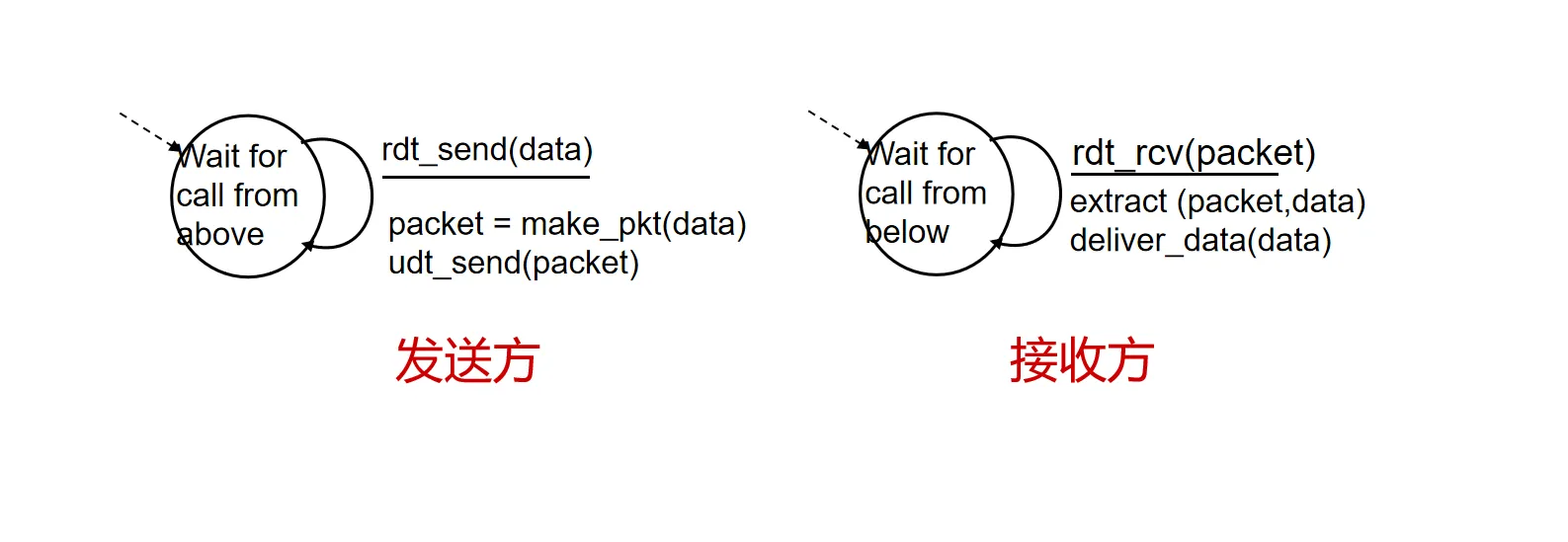
RDT 1.0#
- 假设:信道完全可靠(不丢包、不出错)
- 机制:直接发送,直接接收。不需要任何控制信息
对应的状态机描述:
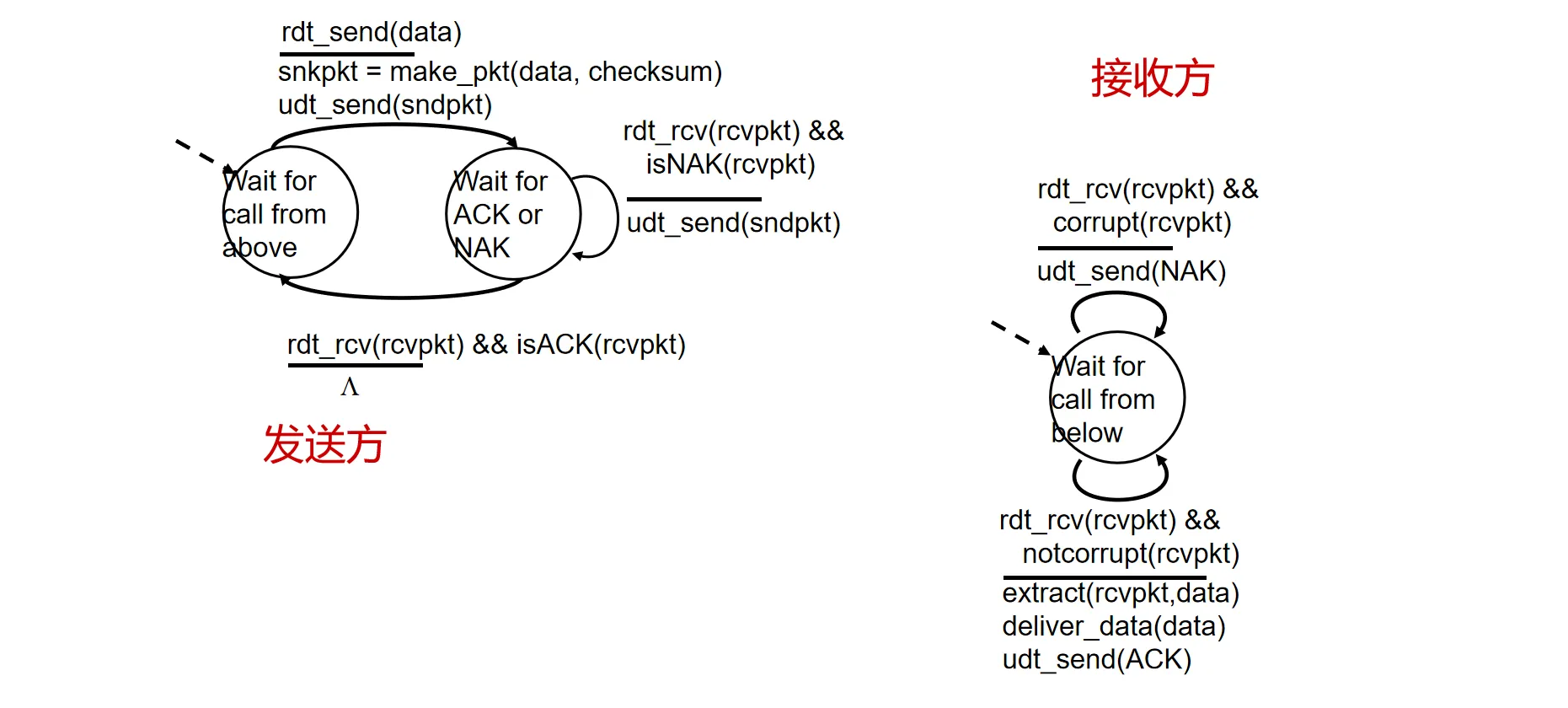
RDT 2.0#
- 假设:比特可能受损,但包不会丢
- 解决方法(ARQ 自动重传请求):
- 使用校验和 (Checksum) 来发现错误
- 接收方根据接收到的数据包进行反馈:
- ACK (Acknowledgement):确认收到
- NAK (Negative Acknowledgement):否认收到(出错)
- 发送方重传机制重传:发送方收到 NAK 后重传
- 问题:如果 ACK 或 NAK 本身受损怎么办?
- 发送方无法判断接收方意图。若盲目重传,接收方会收到重复数据且无法识别。
对应的状态机描述:
RDT 2.1#
如果ACK/NAK出错怎么办:
- 选择1:发送方通知接收方重传ACK或NAK
- 缺陷:通知本身也可能出错,陷入死循环
- 选择2:采用更复杂的校验技术,不仅可以检测差错,还能纠正差错
- 缺陷:额外的计算与传输开销
- 选择3:发送方直接重传
- 缺陷:接收方收到多份数据
在这三种选择中,现实中往往采用了选择3,相对于选择2,方法三只在出错时重传,不需要对每一个包都进行复杂的纠错编码,减少了开销
因此需要引入序列号机制,以区分不同数据包:发送方在数据包中加上序号Seq,接收方忽略序号重复的数据包
- 机制:序列号 (Sequence Number)。
- 对于停等协议,只需要 0 和 1 两个序号。
- 流程:
- 发送方在报文中加入序号 (0 或 1)
- 若 ACK/NAK 受损,发送方重传当前数据包
- 接收方若收到重复序号的数据包,丢弃并重发 ACK
发送方状态机描述:
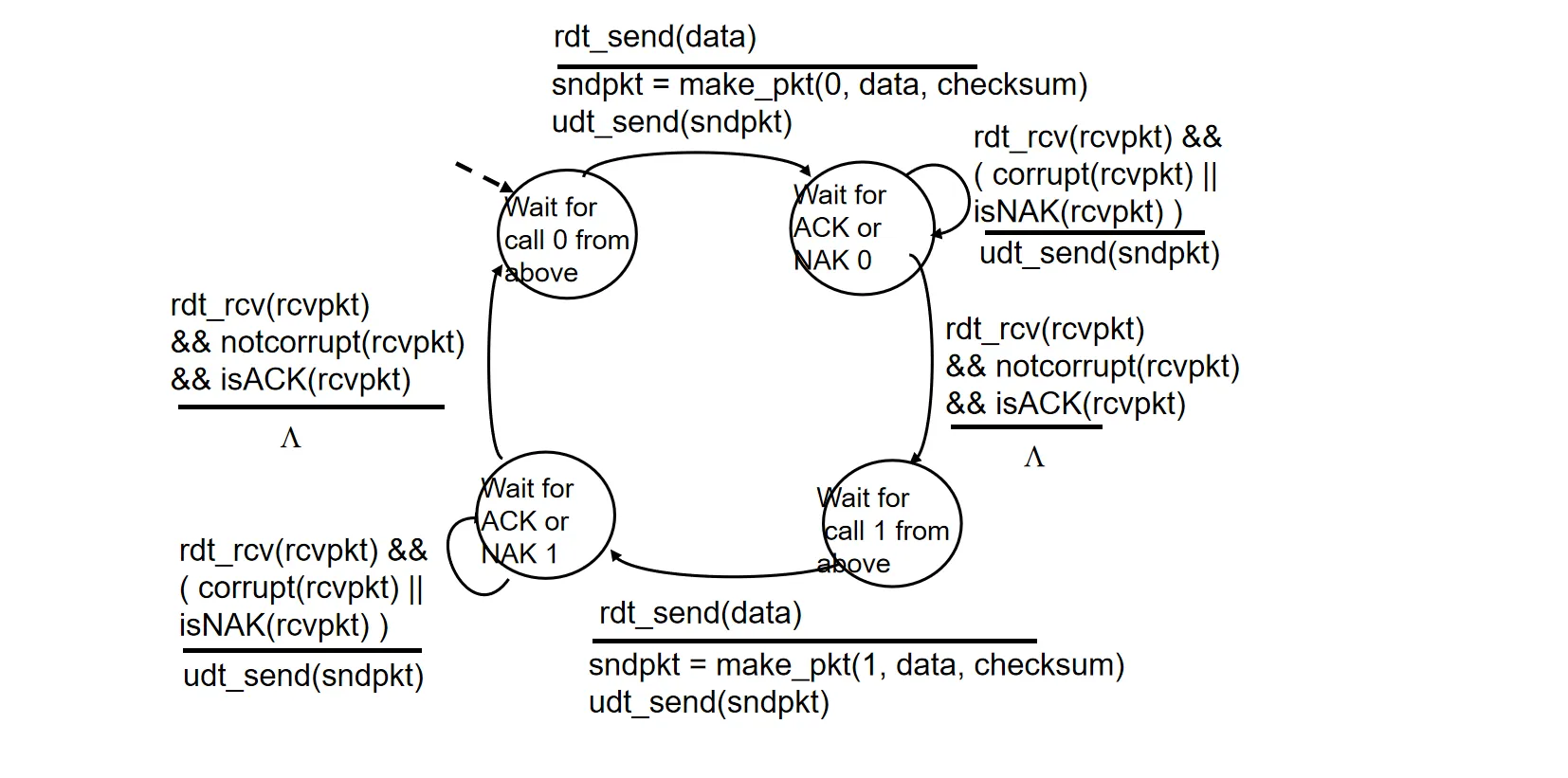
接收方状态机描述:
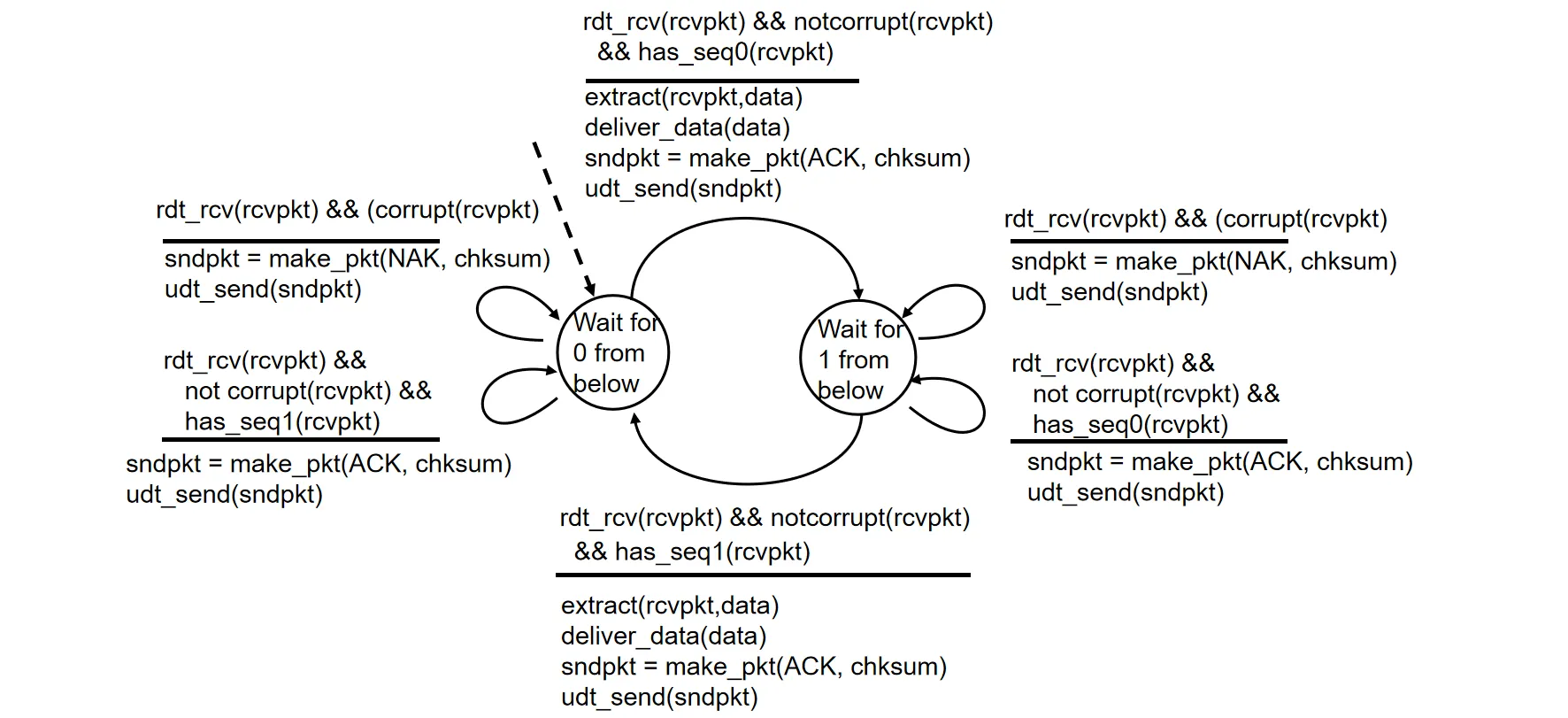
RDT 2.2#
ACK和NAK本身都不携带任何内容,我们可以直接用序列号来判断是否收到了正确的数据包,从而移除 NAK
- 机制:
- 接收方不发送 NAK,而是对上一个正确接收的分组发送 ACK(在ACK中加上最近成功接收的seq)
- 发送方可以判断最近发送是否成功(通过比较ACK的seq与自己的seq),当ACK出错或ACK.seq seq,触发重传
发送方状态机描述:
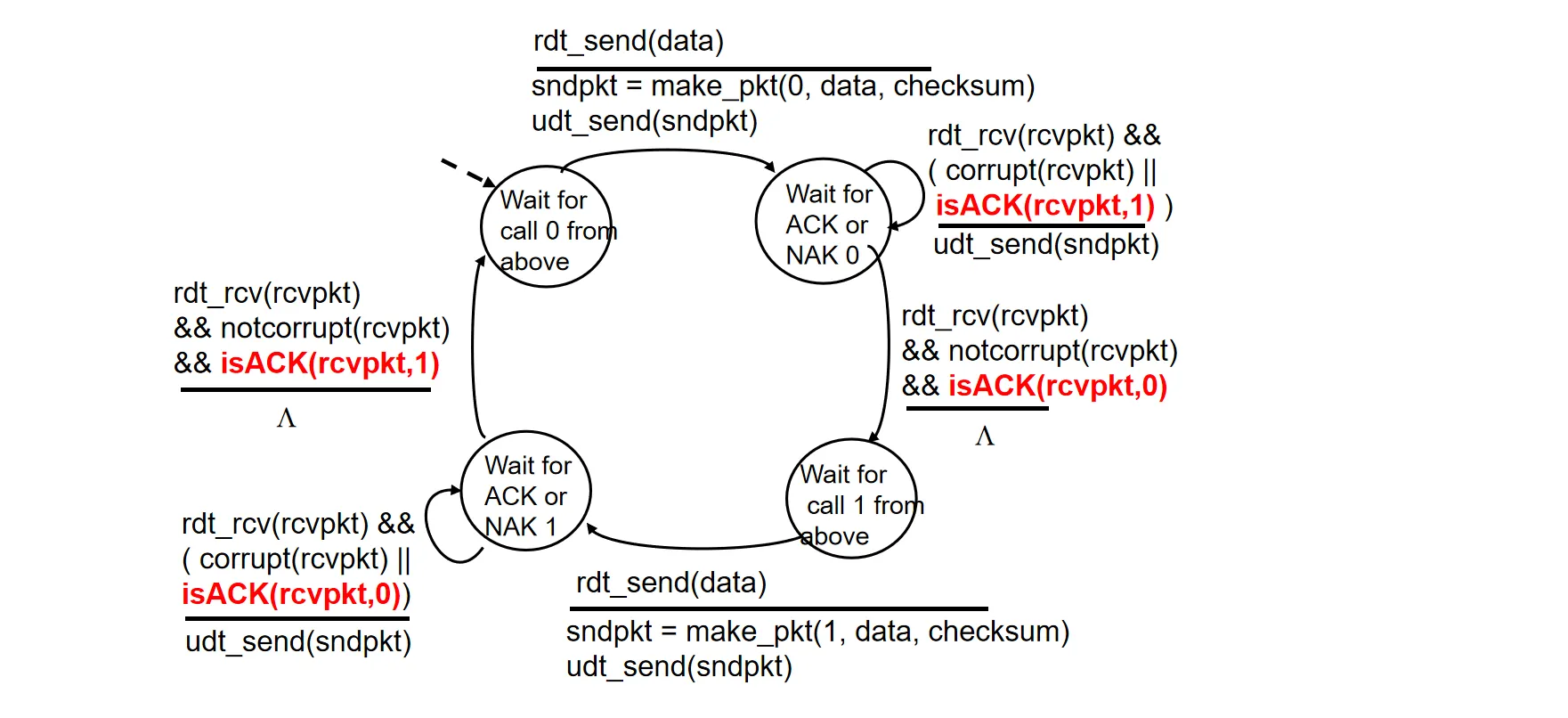
接收方状态机描述:
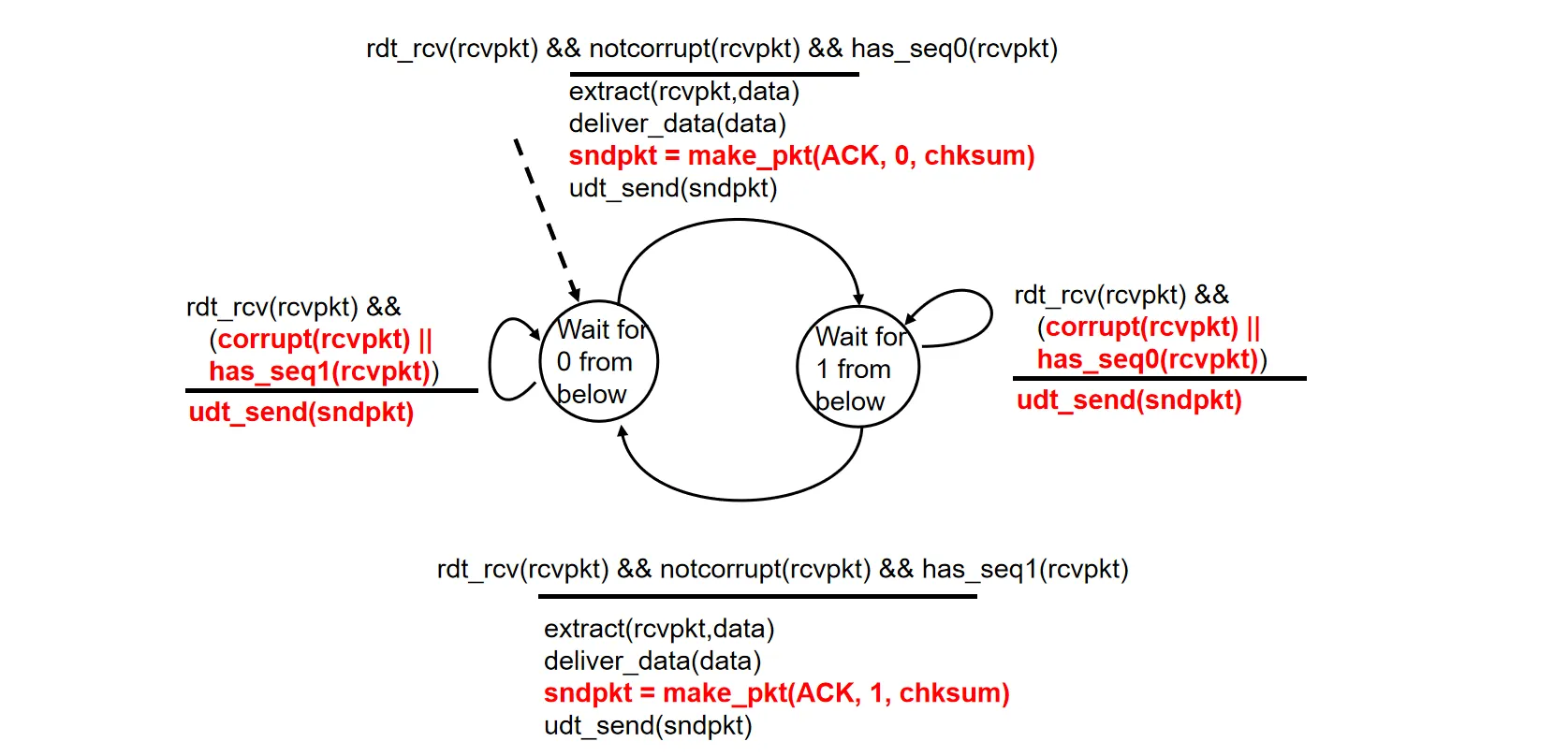
RDT 3.0#
- 假设:信道既可能出错,也可能丢包(数据包或 ACK 丢失)
- 引入机制:计时器
- 发送方每发送一个包,启动定时器。若在规定时间 (Timeout) 内未收到 ACK,则重传
- 如果数据包只是延迟到达,接收方会收到重复包(序列号判重),将包丢弃并发送 ACK
发送方状态机描述:
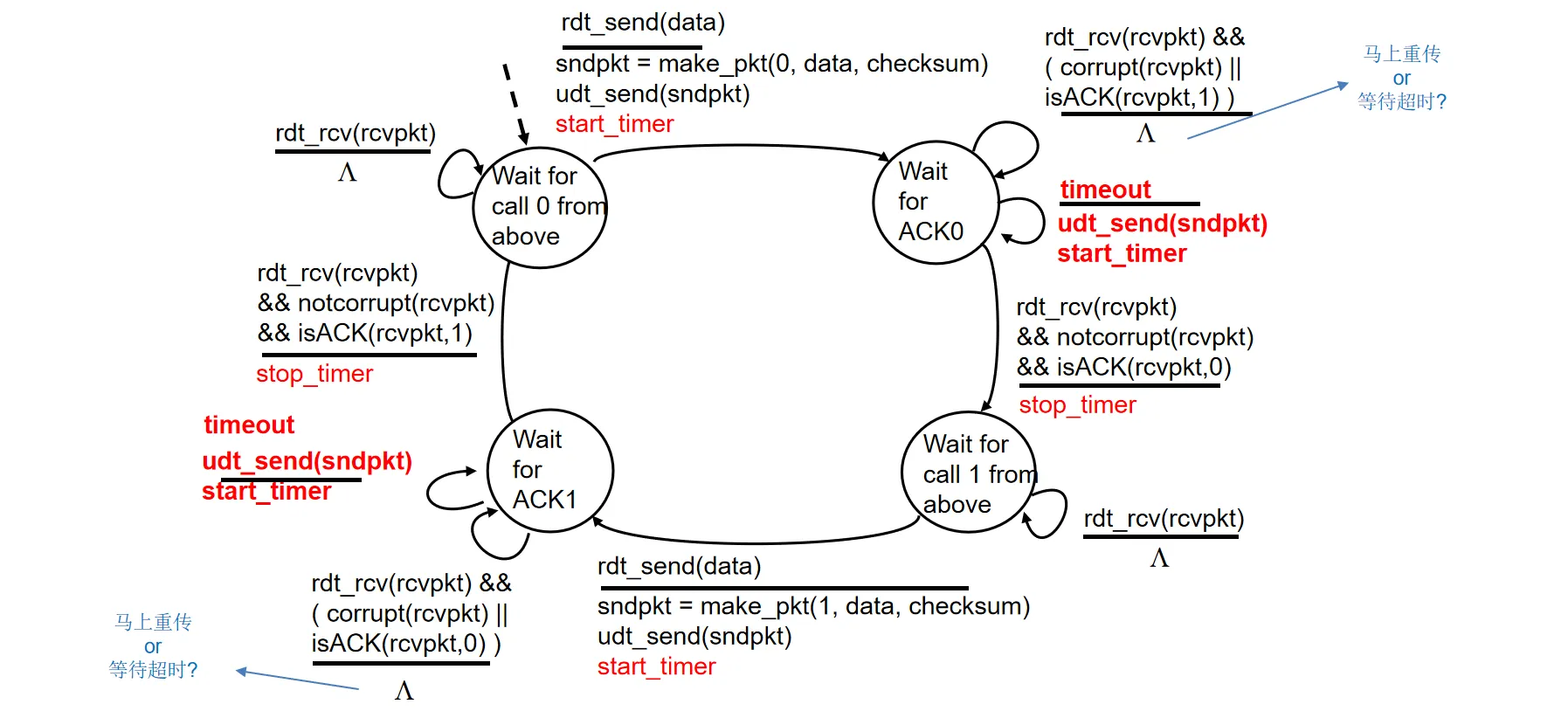
- 右上角和左下角在收到错误ACK时采用的是继续等待直到超时重传的策略,主要是为了避免过多重传导致带宽占用的情况。因此动作为空
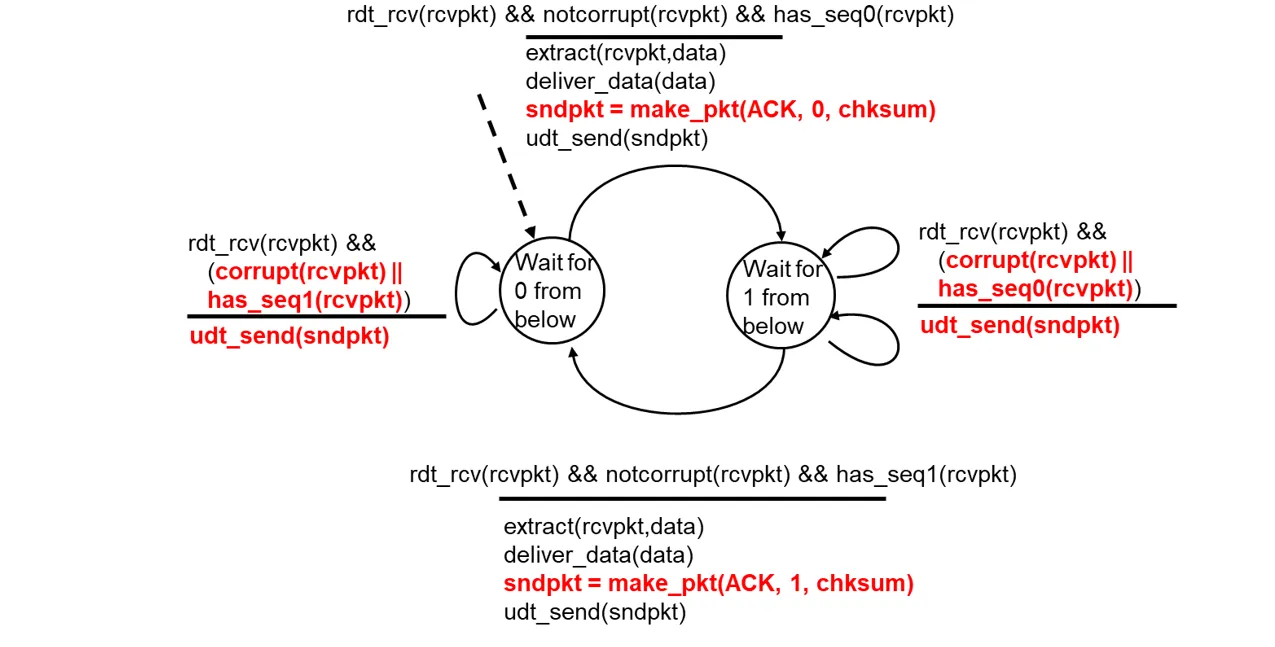
接收方状态机描述:和rdt 2.2完全一样
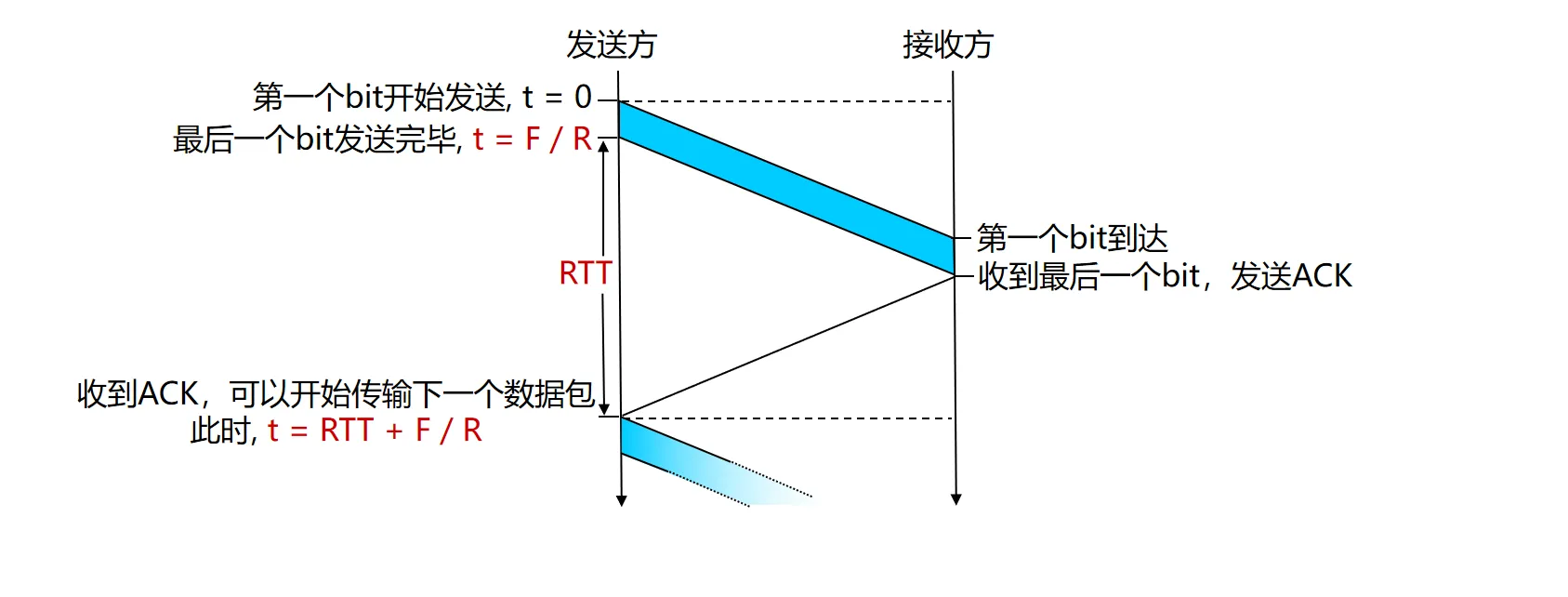
停等式协议的效率分析#
一些评估指标:
- 数据大小 (bits)
- 信道发送速率 (bits/second)
- 信道传播延迟(不考虑接发送端与收端处理延迟、接收端发送ACK延迟)
- 数据发送时间 (Time to transmit a single frame)
- 往返延迟
- 停止等待协议的发送工作时间是,空闲时间是
- 信道利用率
RTT 较大或数据包较小时,信道利用率会很低,在长肥网络(带宽很大,延迟很长的网络)中尤其明显
一种可能的优化方法:使用更大的数据包,但是帧越大,在传输中出错的概率越高,将导致更多的重传 ,且不适用于所有应用场景
一般可靠性方案的性能优化#
流水线 (Pipelining)#
为了解决停等协议效率低的问题,允许发送方在未收到确认前发送多个分组。 发送方源源不断的去发送了一系列的数据包。接收方这边每收到一个数据包的话都会去进行反馈
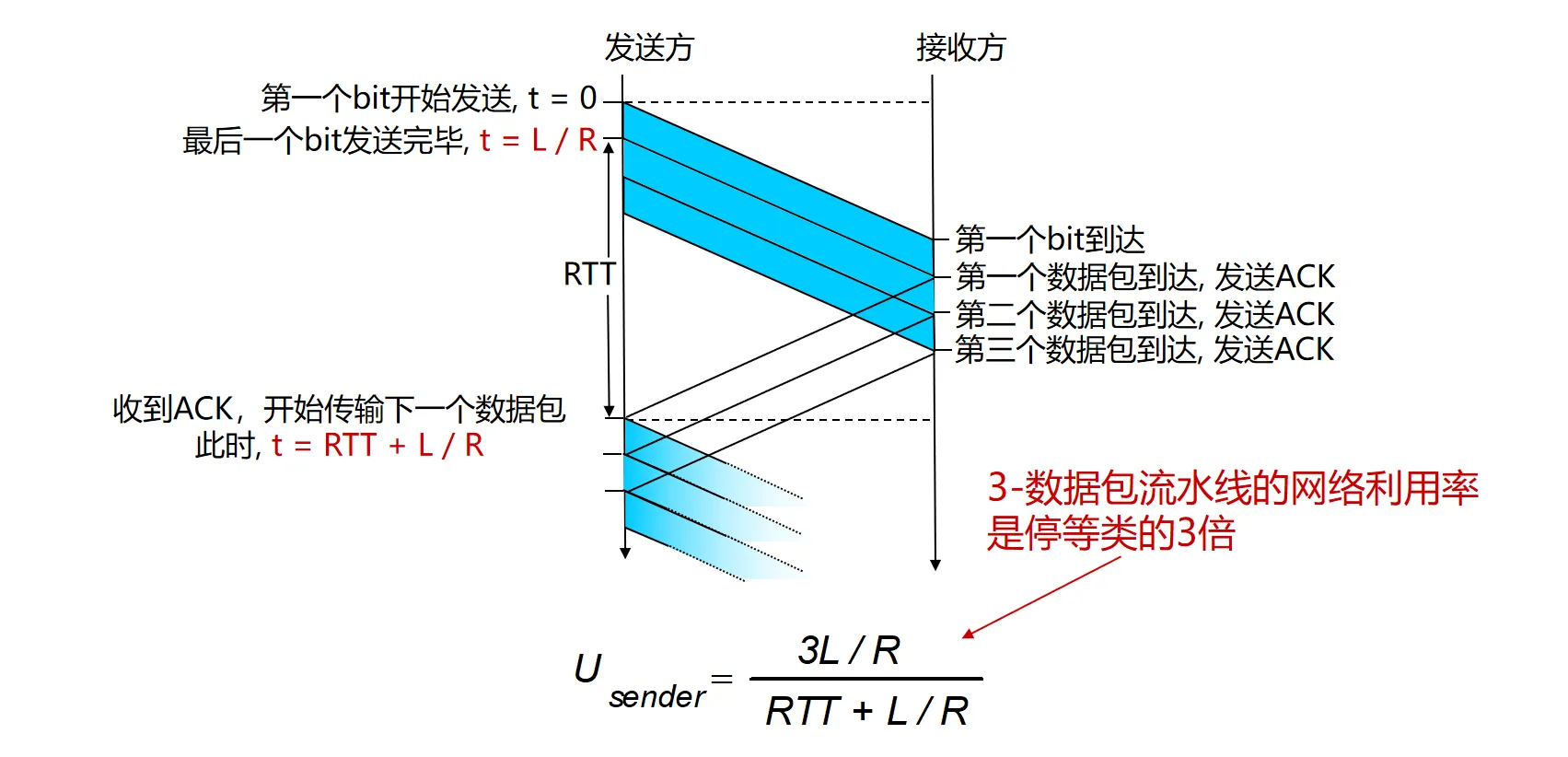
为实现流水线传输,需要以下机制:
- 增加序列号范围:每一个等待确认的数据包都需要一个唯一的seq,不能只用 0 和 1
- 缓存能力:发送方需缓存已发送但未确认的包;接收方可能缓存乱序到达的包
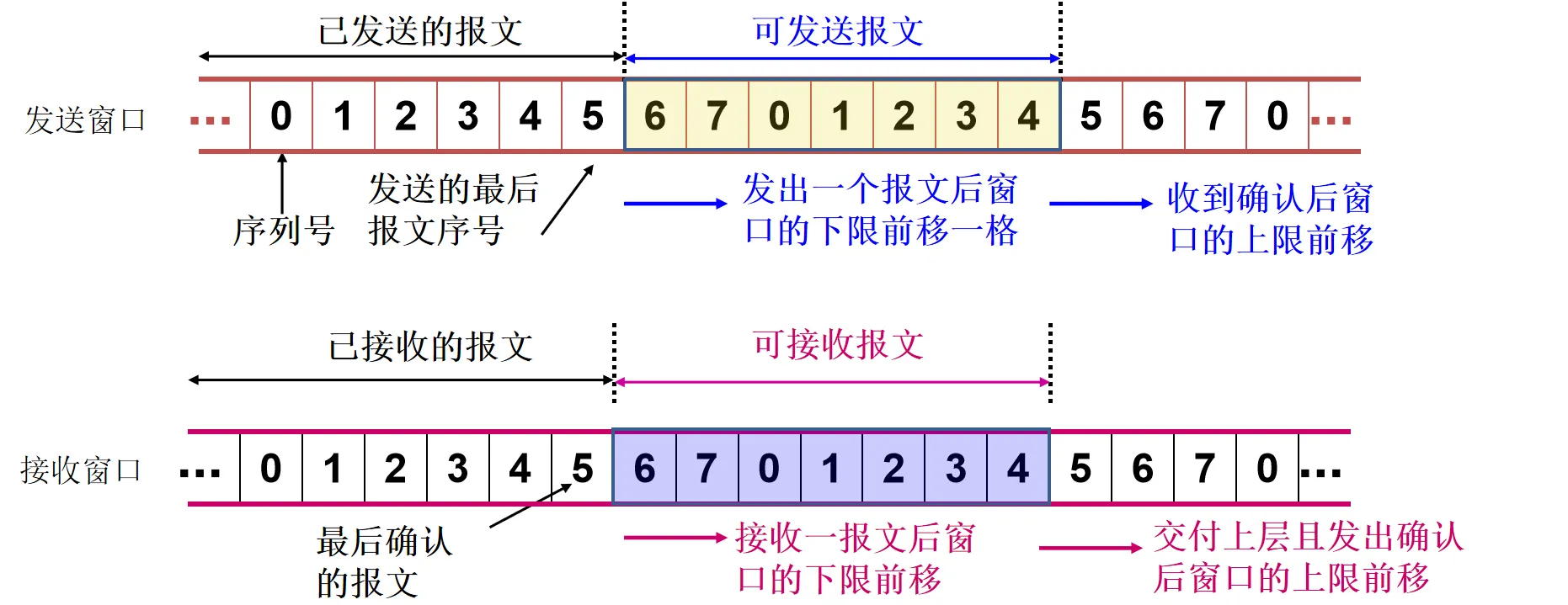
- 滑动窗口机制:限制管道中未确认的数据包数量 ()
一个长度为7的滑动窗口示意图:
回退 N (GBN)#
思想:
- 当接收端收到一个出错报文或乱序报文时,丢弃(即使从未收到过)并且不发送确认
- 发送端超时后,重传所有未被确认的报文
具体操作:
- 发送方:
- 维护窗口 ,记录send_base(当前第一个未确认数据包)和next_seqnum(下一个发送数据包的seq值)
- 累积确认:收到
ACK(n)表示 及之前的所有分组都已确认 - 单一计时器:只为最早发出但未确认的分组维护一个计时器
- 超时处理:一旦超时,重传窗口内所有已发送未确认的分组
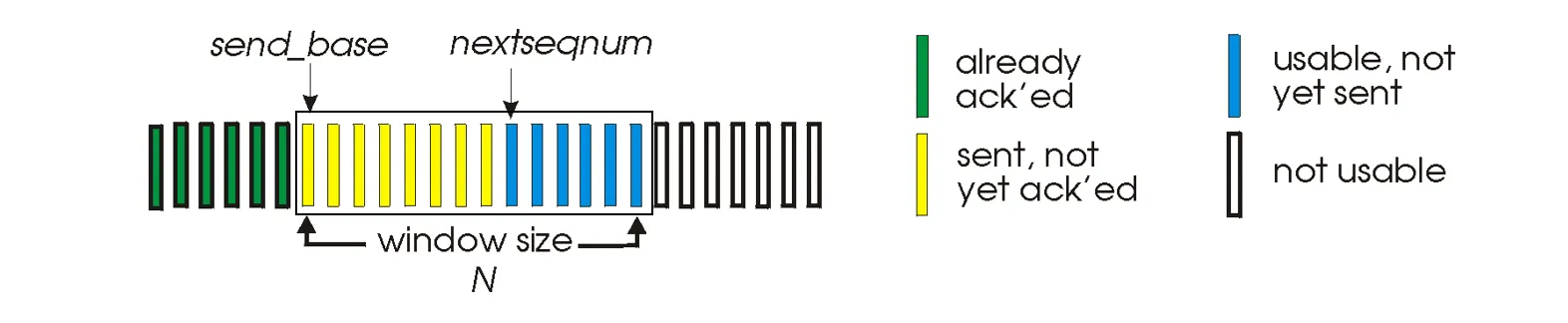
发送方要处理四个事项:
- 事件1:发送
- 更新next_seqnum
- 事件2:收到ACK(n)
- 更新send_base向前移动
- 重设计时器
- 事件3:超时
- 重传所有未确认数据包
- 重设计时器
- 事件4:收到错误ACK(重复ACK、校验差错)
- 忽略,等到超时重传
发送方状态机描述:
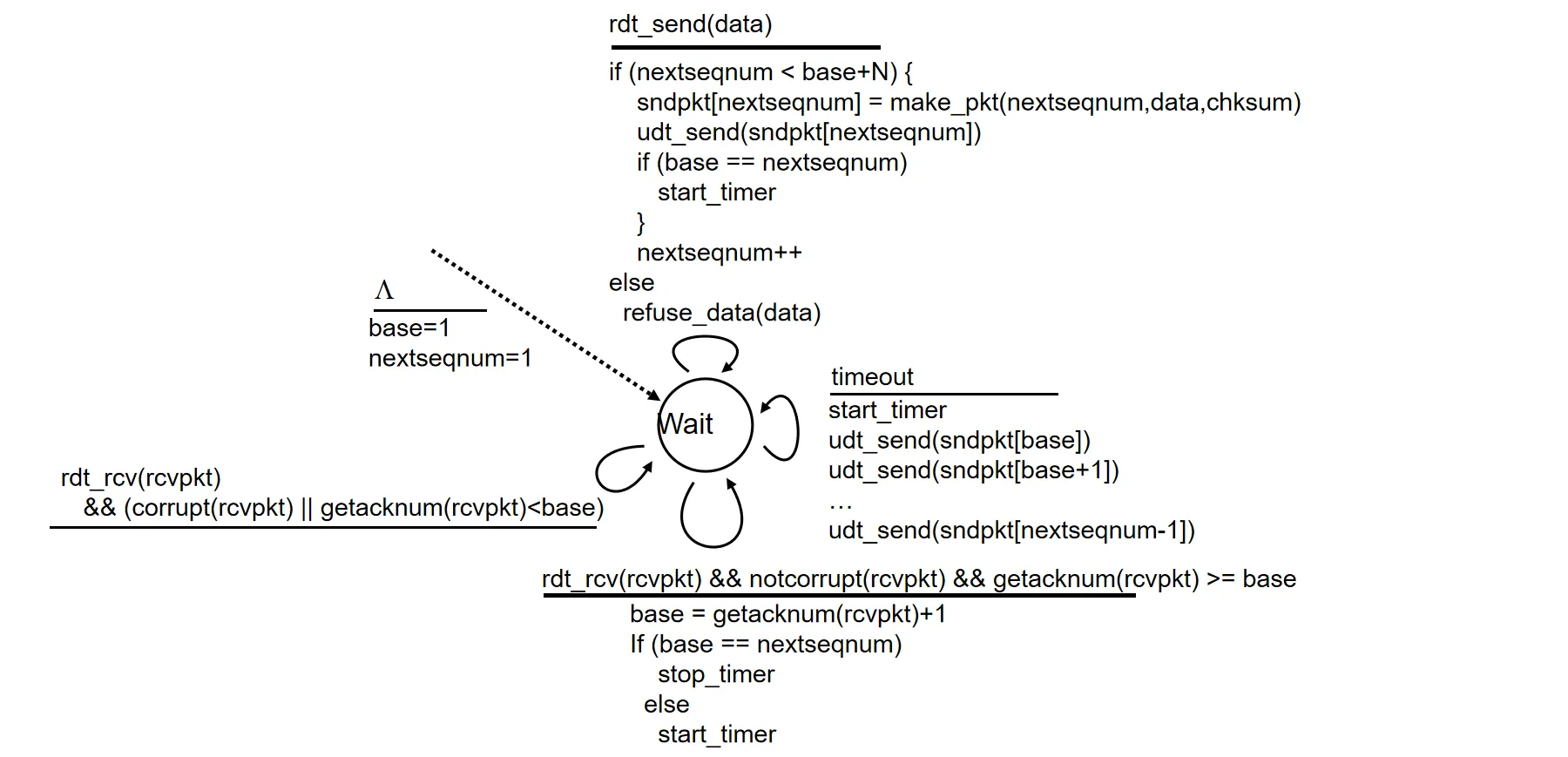
- 接收方:
- 只维护下一个期待的seq值
- 不缓存乱序分组:只接收期待序号的分组。
- 若收到乱序分组(期待 ,来了 ),直接丢弃,并重发
ACK(n-1)。
接收方状态机描述:
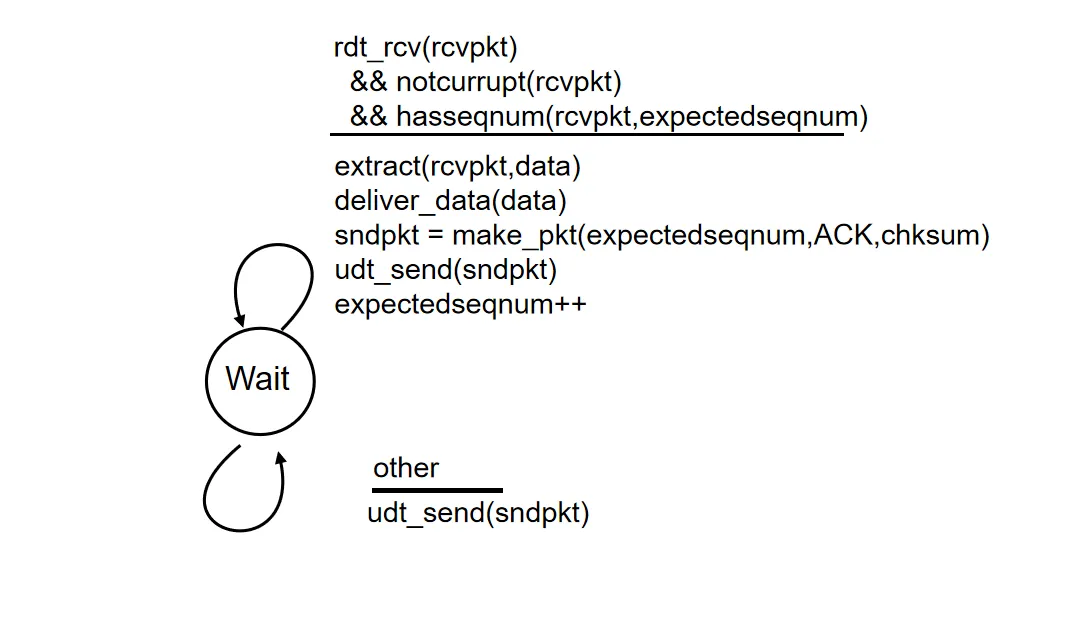
这个方案减轻了接收端负担,但是导致重传包数量大,增加发送端与信道负担
选择重传 (SR)#
思想:在回退 N 的基础上对每个数据包进行更细粒度的一个管理
- 接收方对每个数据包独立确认
- 若发送方发出连续的若干包后,收到对其中某一包的ACK错误,或某一包的定时器超时, 则只重传该出错或超时的数据包
具体操作:
-
发送方:(与GBN相比只在计时器和重传方法上不同)
- 独立计时器:每个分组都有自己的逻辑计时器。
- 选择重传:超时后只重传那一个未收到 ACK 的分组。
-
接收方:(与GBN相比需要缓存乱序分组)
- 独立确认:对每个正确接收的分组单独发送 ACK。
- 缓存乱序分组:收到乱序分组先缓存,等缺漏的分组到达后一并交付。
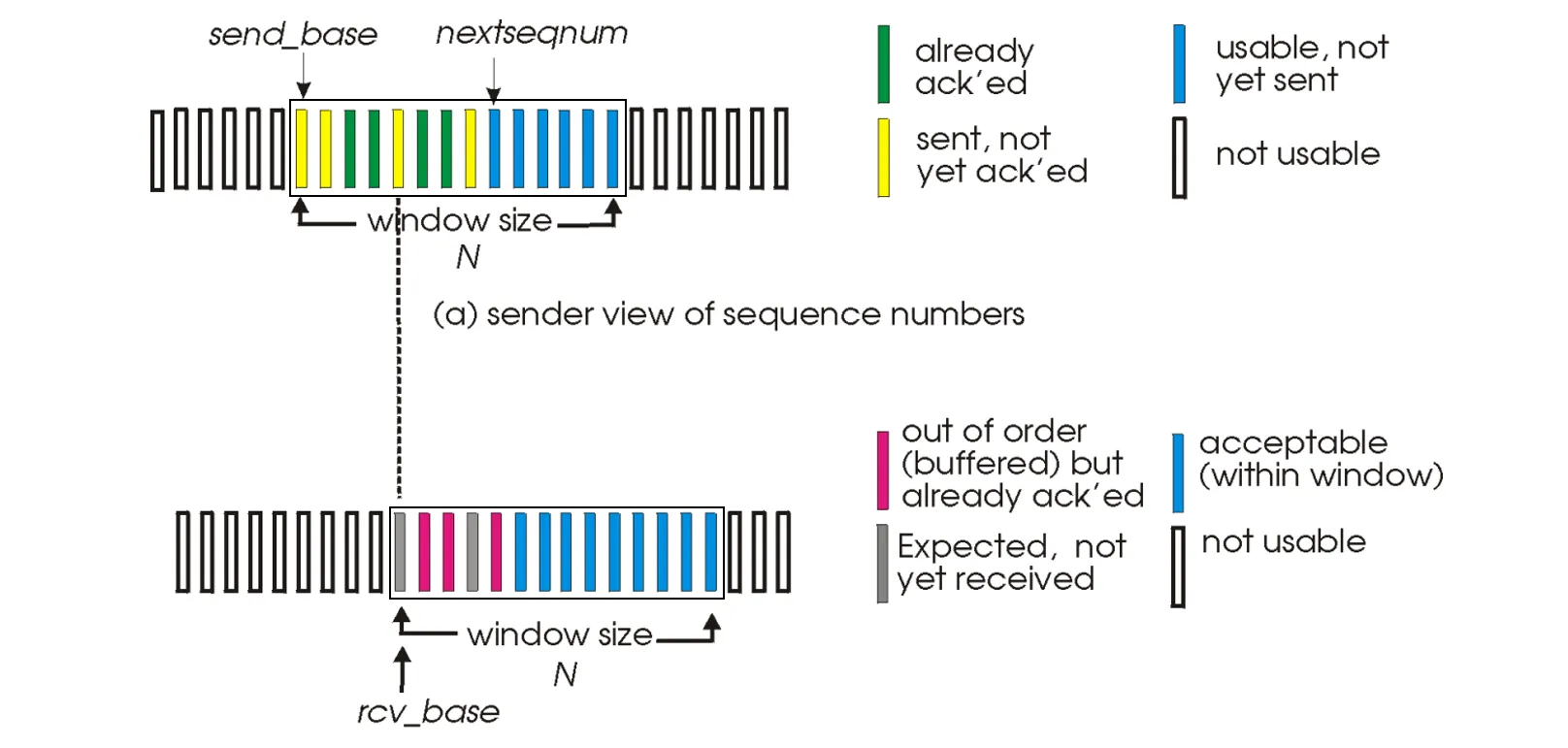
发送方处理三个事项:
- 事件1:发送数据
- 当下一个seq在窗口内,发送
- 事件2:数据包n到期
- 重传n, 重置计时器
- 事件3:
- 标记n为已接收
- 如果
n==sendbase,更新sendbase
接收方处理三个事项:
- 事件1:接收报文序列号(当前窗口内)
- 确认n
- 若
n==revbase: 将一系列顺序packet交付给上一层,并更新revbase - 否则:缓存n
- 事件2:接收报文序列号
- 确认n(不能忽略)
- 事件3:其他情形
- 忽略
事件2不能忽略原因:这个数据包它之前的ACK有可能丢失掉了,不去进行ACK的话发送窗口可能会被卡住,无法继续发送新的数据
事件3的情形:数据包必定不在发送方的窗口内,说明这个数据包是过期的,直接忽略即可
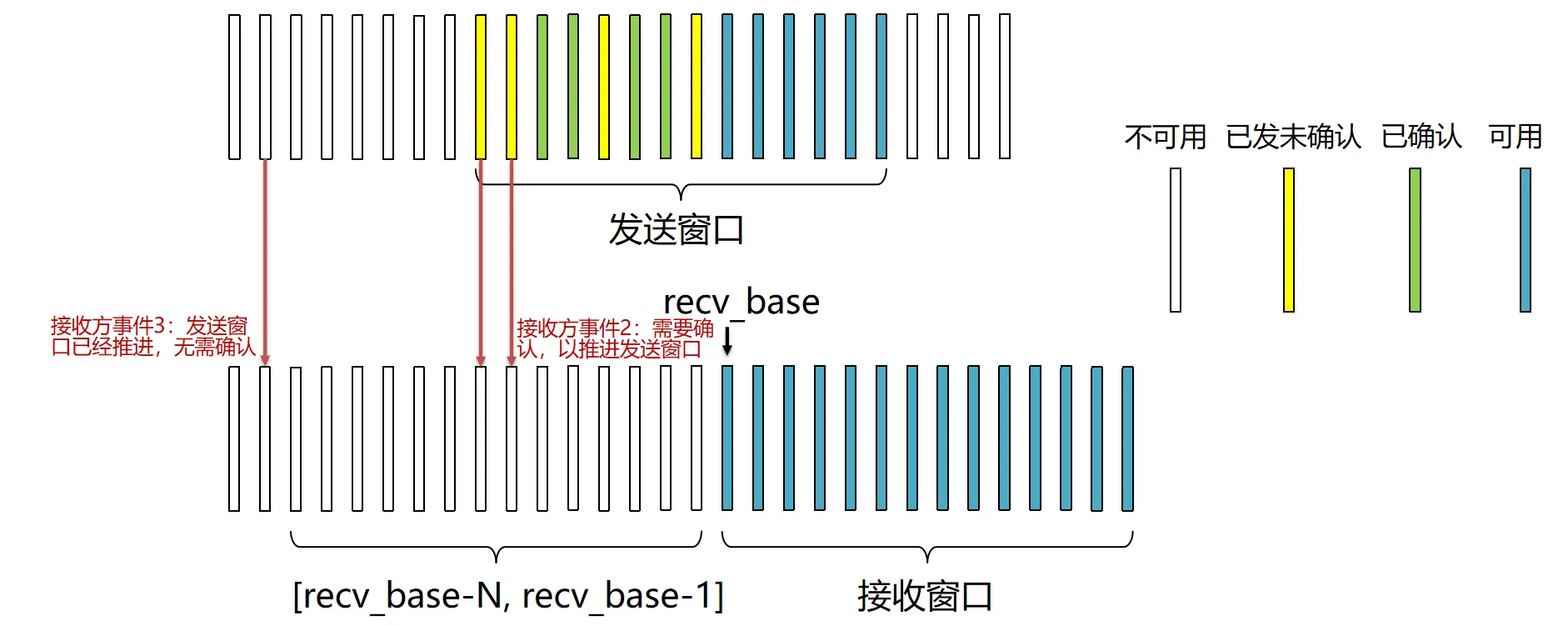
窗口限制:
- SR 的窗口大小 必须满足:,否则会导致新旧分组无法区分的“重叠”问题。
- GBN 的限制是
SR vs GBN 对比#
| 特性 | GBN (回退N) | SR (选择重传) |
|---|---|---|
| 发送方:定时器 | 单个,对最早未确认报文进行确认 | 每个报文单独维护一个计时器 |
| 发送方:重传策略 | 重传窗口内所有未确认分组 | 只重传出错/超时分组 |
| 接收方:确认方式 | 累积确认 | 独立确认 |
| 接收方:失序报文处理 | 不缓存接收报文,通过重传所有未确认报文解决 | 缓存接收到的报文,将连续报文交付上层 |
TCP 的可靠传输实现#
TCP 的实现是 GBN 和 SR 的混合体,实际的TCP很复杂,这里我们介绍简化版
基础机制#
- 流水线发送
- 对字节建立序号,而非报文
- ACK值为下一个期望的字节序号,而非当前已经收到的最后一个字节。放在正常数据包里(捎带,piggyback)
- 支持双方同时发送数据和ACK
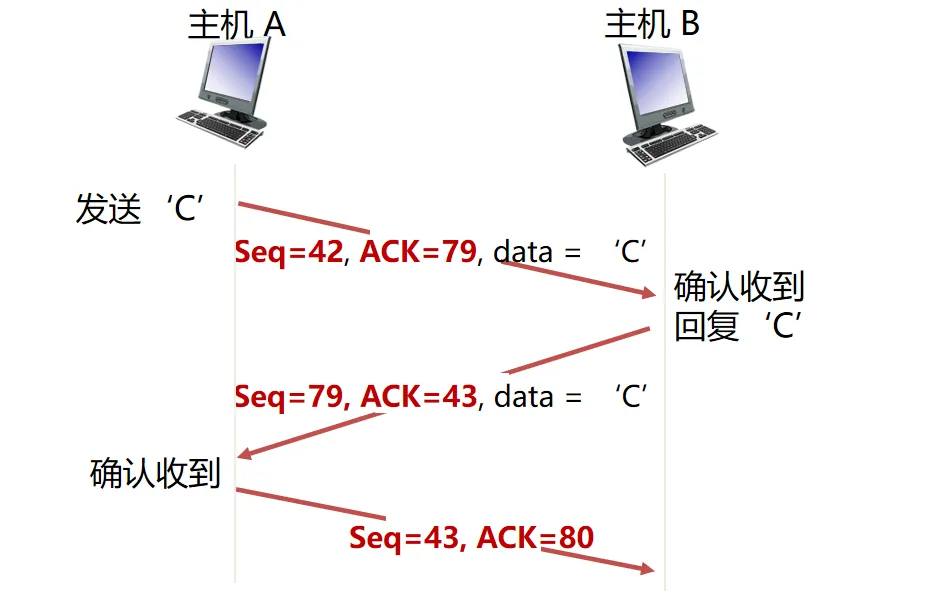
混合特性(GBN + SR)#
- 像 GBN 的点:
- 发送方通常只维护一个重传定时器(针对最早未确认报文)
- 接收方使用累积确认
- 像 SR 的点:
- 接收方通常会缓存乱序报文(虽然协议未强制,但实现上通常如此)
- 发送方超时后,只重传最早的那个未确认报文段,而不是重传所有(减少浪费)
TCP发送端#
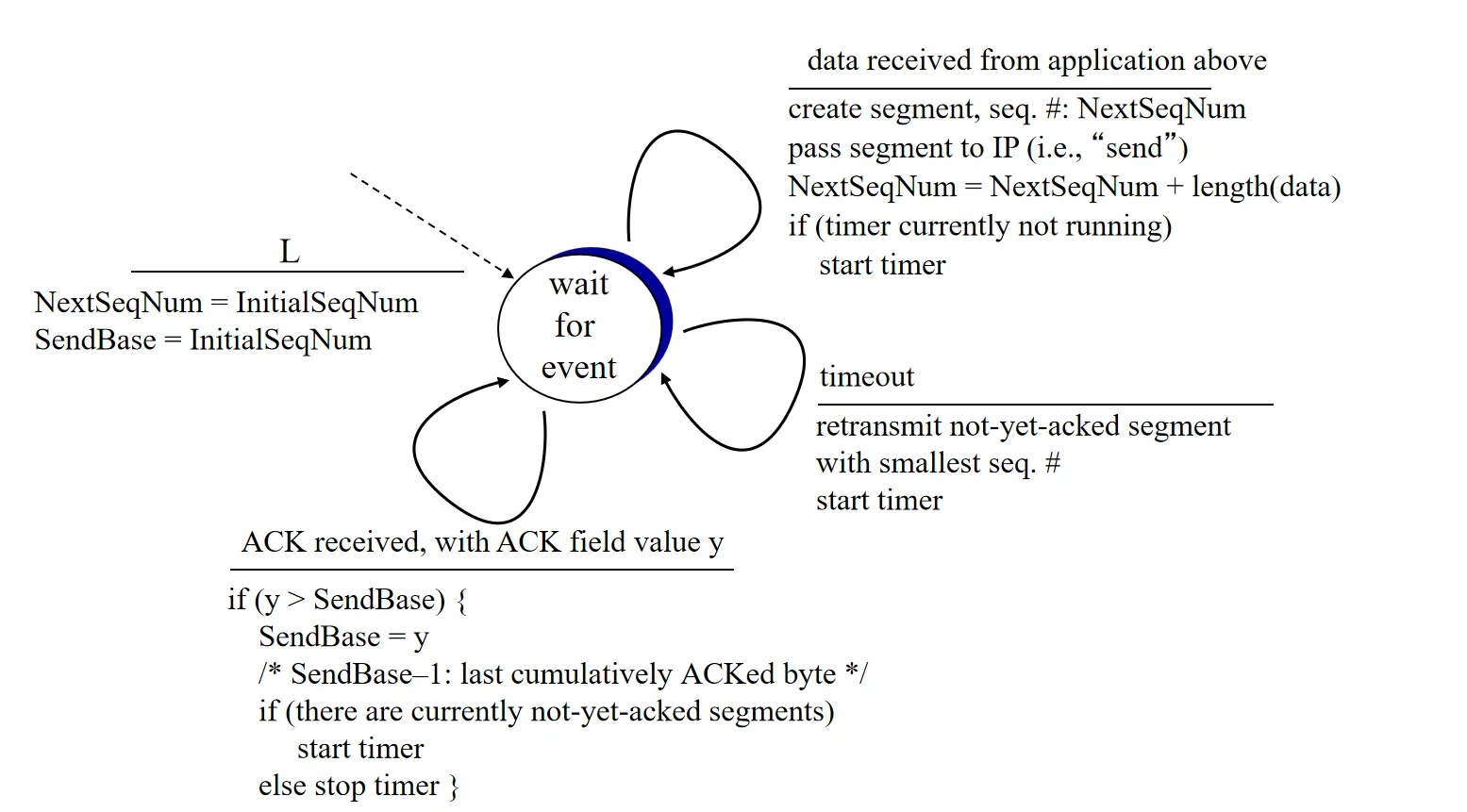
TCP的发送端主要处理三种事件
- 事件1:上层应用有数据要发送
- 创建一个TCP的报文段并发送
- 如果没有正在运行的计时器,启动计时器
- 事件2:超时
- 重传最早未被确认的报文段
- 重启计时器
- 事件3:收到ACK(n)
- 如果
n > sendbase,更新sendbase - 如果发送窗口中还有未被确认的报文段,重启计时器
- 如果
简化版的TCP发送方状态机描述:
TCP通过采用以下机制减少了不必要的重传:
- 只使用一个定时器且只重发第一个未确认报文,避免了超时设置过小时重发大量报文段
- 利用流水式发送和累积确认,可以避免重发某些丢失了ACK的报文段
TCP超时时间 (RTO) 的设置
超时时间必须动态适应网络 RTT 的变化,若超时值太小,容易产生不必要的重传;若超时值太大,则丢包恢复的时间太长
实际中网络中的RTT抖动的是非常严重的,发送方会不断实时检测当前的一个RTT值是多少。具体某次检测到RTT值的话,我们把它称为一个sample RTT。 这个值的波动非常大,所以我们在实际使用的时候,会对它进行一个平滑的处理:
EstimatedRTT (平滑 RTT),使用指数加权移动平均进行估计:
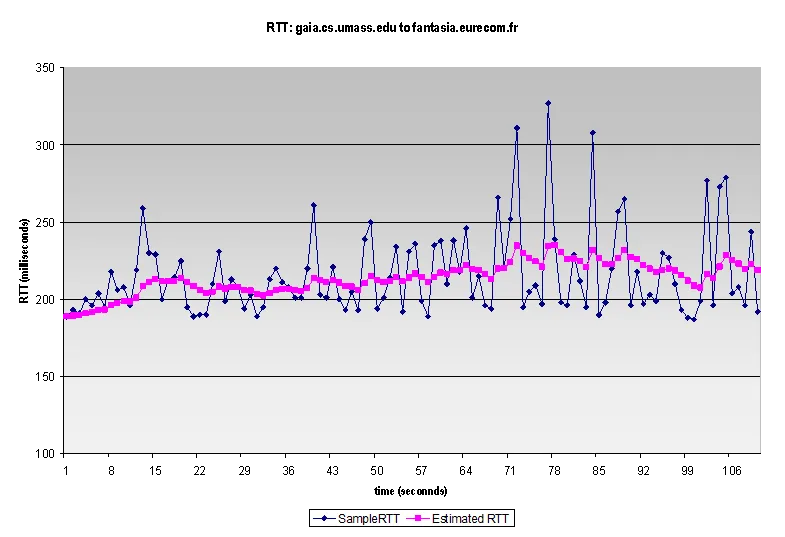
但是这种平滑化处理之后的值与实际值相比差异非常大,实际使用的时候,会在这个平滑化的RTT的基础上,再加上一个安全距离DevRTT
DevRTT (RTT 偏差):
一般设定TimeoutInterval (最终超时值)为:
实际中,由于重传时所使用的序列号跟ACK发生丢失的数据包的序列号是相同的,无法判断是对原始数据包的确认,还是对重传数据包的确认,这称为TCP 二义性问题。 这个问题导致RTT的测量变得不准确,进而影响RTO的计算。
为了解决这个问题,TCP引入了以下机制:
- 发生重传时,不更新RTT的测量
- 定时器补偿:若发生超时重传,RTO 直接加倍,直到传输成功或达到上限
最终策略(称为 Karn 算法):
- 使用EstimatedRTT估计初始的超时值
- 若发生超时,每次重传时对定时器进行补偿(超时值加倍),直到成功传输一个报文段或达到某个上限为止
- 若收到上层应用数据、或某个报文段没有重传就被确认了,用最近的EstimatedRTT和DevRTT估计超时值
快速重传 (Fast Retransmit)
- 问题:超时重传反应太慢(RTO 通常较大)
- 机制:如果发送方连续收到 3 个重复的 ACK,说明该 ACK 指示的后续报文段大概率丢失
- 动作:在定时器到期前,立即重传丢失的报文段
TCP接收端#
推迟确认 (Delayed ACK)
- 机制:收到正确有序报文后,不立即发 ACK,而是等待一定时间后再确认
- 期望有数据要回发(捎带确认)。
- 期望有下一个有序报文到达(合并确认,减少 ACK 数量)。
- 限制:
- 推迟时间不超过 500ms。
- 每两个连续报文段必须发送一个确认(防止 RTT 估计不准)。
- 乱序报文到达或填充空隙时,立即发送确认(触发快速重传)。
总结#
| 特性 | GBN (回退N) | SR (选择重传) | TCP (实际实现) |
|---|---|---|---|
| 确认方式 | 累积确认 | 独立确认 | 累积确认 |
| 定时器 | 单个 (最早未确认) | 多个 (每个分组一个) | 单个 (最早未确认) |
| 重传策略 | 重传窗口内所有未确认分组 | 只重传出错/超时分组 | 只重传最早丢失分组 + 快速重传 |
| 接收端缓存 | 无 (丢弃乱序) | 有 (缓存乱序) | 有 (缓存乱序) |
| 窗口限制 | Seq空间 | Seq空间 | 32位序列号 (足够大) |
TCP超时值的确定:
- 基于RTT估计超时值+ 定时器补偿策略
测量RTT:
- 不对重传的报文段测量RTT
- 不连续使用推迟确认
快速重传:
- 收到3次重复确认,重发报文段
延迟确认优化:
- 考虑RTT估计