本文内容基于 2025 秋季《计算机网络》课程讲述,如有差错,欢迎指正
网络路由简介#
网络层的功能被划分为两个平面:
- 数据平面:负责转发。即路由器根据转发表,将数据包从输入接口移动到正确的输出接口。这是本地动作,由硬件快速执行
- 控制平面:负责路由。即决定数据包从源到目的地的全局路径。这是网络范围的逻辑,通常由软件执行
控制平面上通过运行一些路由算法来计算路由表,然后将路由表下发到数据平面供其使用。
整个网络可以抽象成一张图,其中节点代表路由器,边代表链路,边的权重代表链路代价(如延迟、带宽、拥塞等)。 路由算法本质上就是在这个图中去找到从发送方到接收方代价最小的路径的算法。很容易想到图论中的最短路径问题。 经典的两个算法就是Dijkstra算法和Bellman-Ford算法,分别对应链路状态路由算法和距离向量路由算法。
路由选择算法#
因为使用的图算法不同,路由计算所需的信息也不同:
- 距离向量算法:每个节点只知道邻居结点,以及到邻居结点的链路开销。需要结点与邻居不断交换信息,并反复迭代更新
- 链路状态算法:每个节点需要知道完整的网络拓扑与链路开销等信息
距离向量算法#
Bellman-Ford 方程:
- :x 到 y 的最小代价
- :x 的邻居
- :x 到 v 的代价
每个节点需要维护的信息:
- 到达每个邻居结点v的开销:
- 距离向量(DV):,该结点x到网络中所有其他结点y的最小代价的估计值
- 每个邻居结点v的距离向量,即对于所有邻居v,结点x保存
每个节点的计算过程:
- 初始化:每个节点记录自己到邻居的链路开销,其他节点的距离设为无穷大
- 交换:每个节点向邻居发送它自己到某些节点的距离向量,该节点接收并更新邻居的距离向量
- 更新:收到邻居的向量后,利用 B-F 方程重新计算自己的距离向量
- 迭代:重复上述过程,收敛为实际最小费用
距离向量算法具有一些特点:
- 异步:结点迭代频率不需要一致
- 事件驱动:每次某个结点上的迭代有2种触发
- 本地链路代价发生改变
- 收到来自邻居的DV更新
- 分布式:结点直接互相协作
- 每个结点当且仅当DV信息发生变化时通知其他结点
- 邻居结点根据需要通知自己的邻居
链路代价改变时:
下面我们以这个模型看一下链路代价改变时,距离向量算法的行为:
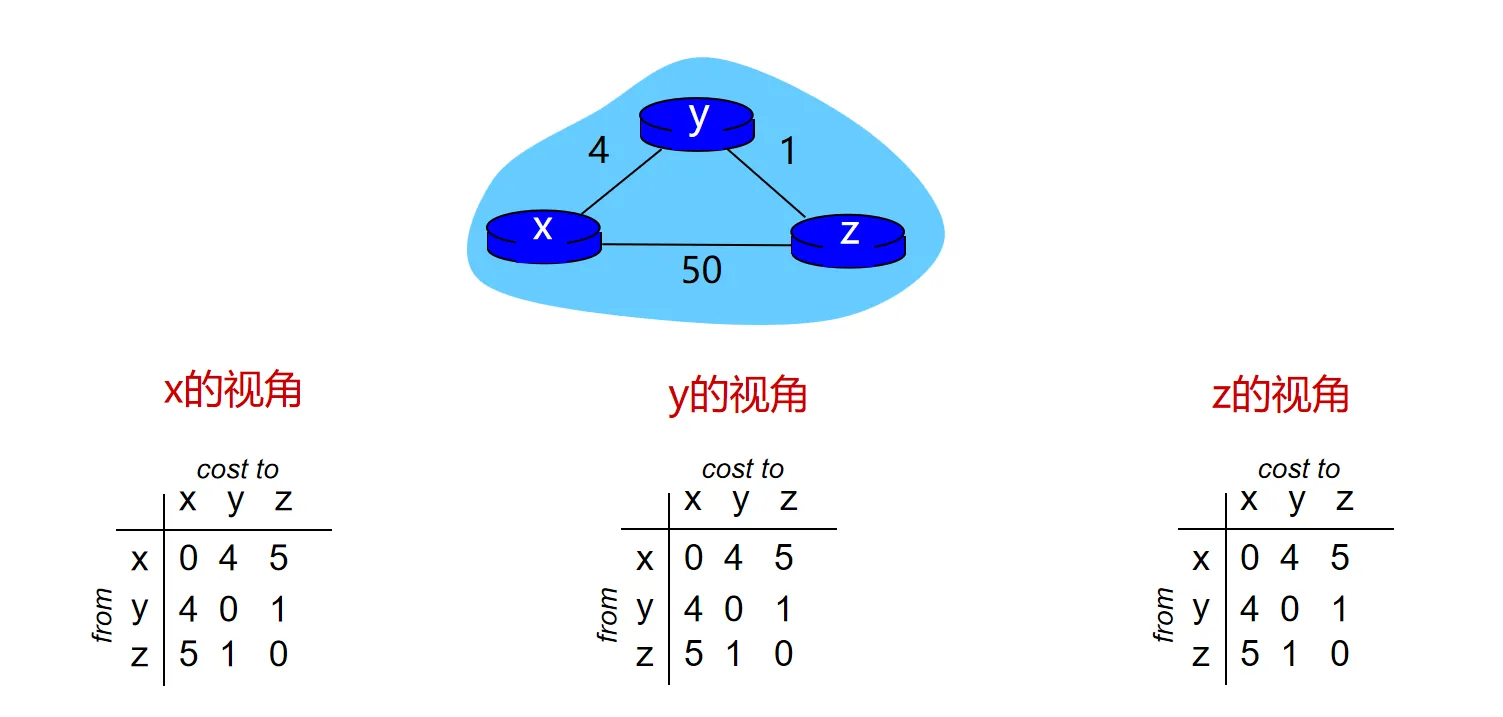
- 当链路费用降低时
由于B-F算法的取 min 操作,DV 算法能迅速收敛
- 当X-Y间费用变为1后,Y会更新自己的DV,并通知邻居 X和Z
- Z收到Y的通知后,发现通过Y到达X的费用变小,更新自己的DV,并通知邻居X和Y
- Y收到Z的通知后,更新自身信息,发现DV没有变化,不再通知邻居
- ……如此反复,最终所有节点的DV会很快收敛到正确值
即好消息传播的快
- 当链路断开或费用剧增时
- 当X-Y间费用变为60后,Y会更新自己的DV,,即Y会认为通过Z到达X的费用更低,通知邻居X和Z
- Z收到Y的通知后,更新,通知邻居 X和Y
- Y收到Z的通知后,更新
- 如此往复每次加1,需要很长时间才能收敛到正确值(51)
如果X-Y间费用更大,收敛速度不可接受。坏消息传播得慢,又称为“无穷计数”问题
- 一个解决方案:毒性逆转 (Poisoned Reverse)
- 如果节点 Z 通过 Y 到达目的地 X,则 Z 告诉 Y:

- 此时直接会增长为60
- Z收到Y的通知后,更新,通知邻居 X和Y
- Y收到Z的通知后,更新 避免了无穷计数问题
但是毒性逆转并不能解决一般性的无穷计数问题,例如下面的例子:
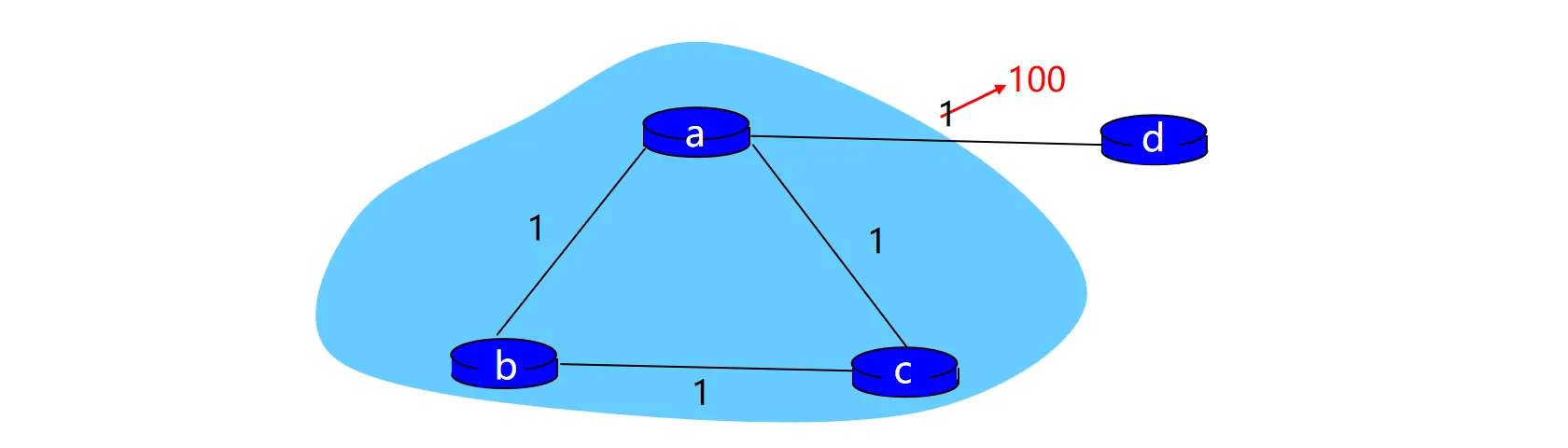
- 当A-D间距离变得很大时,A会通知B、C
- 由于毒性逆转,B知道不能通过A到达D(),但是B认为可以从C以很小代价(3)到达D,于是更新自己的DV并通知A、C
- 同理,C也会认为可以从B以很小代价(3)到达D
- 他们互相会认为对方的路走得通,因此还是需要很多轮之后才会发现正确的代价
链路状态算法#
基于Dijkstra算法计算最短路径
所有节点必须通过链路状态广播获知网络拓扑与链路开销
一些符号:
- :节点 x 到 y 的链路费用;若不直连则为
- :当前从源节点到节点 v 的路径费用估计值
- :从源到 v 的路径上,v 的前驱节点
- :已找到最小费用路径的节点集合
计算步骤(在图上运行Dijkstra算法)
- 初始化:将源节点加入 ,初始化所有邻居的开销。
- 循环:
- 从不在 中的节点里,找出 最小的节点 ,加入 。
- 更新 的所有邻居 的费用:。
- 重复直到所有节点都在 中。
根据计算结果可以求出从源节点到所有其他节点的最短路径,由路径信息可以构造路由表
复杂度:,若使用堆数据结构优化可达 。
LS 与 DV 算法对比#
| 特性 | 链路状态 (LS) | 距离向量 (DV) |
|---|---|---|
| 消息数量 | n个结点, E条链路, 一共发送O(nE)条消息 | 取决于收敛速度。链路代价不变时,收敛需要最多O(nE)条消息 |
| 收敛速度 | 较快 (或) | 较慢,可能存在路由环路和无穷计数 |
| 可靠性 | 较强,经过有限次传输故障消息会被所有路由器知道 | 较弱,需要很长时间把故障消息扩散到全网 |
总的来说,链路状态算法的性能是更好的,但是存储和计算的开销更大大
层次路由与路由协议#
面对互联网的巨大规模,直接运行路由算法是不现实的(路由表过大、信息交换量太大), 一个很自然的想法是利用地址聚合,将网络划分为各个子网,根据地址前缀进行路由选择。 但由于现实中一些因素,比如地址分配不连续、网络管理员的管理方法等,简单的地址聚合并不能很好地解决问题。 因此,互联网采用了层次路由的方式,将网络划分为多个自治系统进行管理
自治系统#
互联网由大量不同的网络互连,每个管理机构控制的网络是自治的
层次路由将网络划分为许多独立的区域,称为自治系统 (AS),由某个管理机构控制
- AS 内部可以自行选择配置路由策略和协议,通常运行相同的路由协议
- AS 之间运行特定的路由协议,进行AS间的路由选择
- 每个AS会被分配一个全球唯一的AS号 (AS ID),用于标识该AS
某种意义上,AS可以理解为与IP地址无关的“超级子网”
AS 内路由协议#
自治系统内部使用内部网关路由协议,Interior Gateway Protocols (IGP),本质上是对链路状态与距离向量进行协议封装, 下面是一些常见的IGP协议:
- RIP (Routing Information Protocol):
- 基于 距离向量 (DV) 算法
- 以跳数作为距离度量,不再使用
- 每 30 秒与邻居交换一次路由表
- OSPF (Open Shortest Path First):
- 基于 链路状态 (LS) 算法(Dijkstra)。
- 进一步将路由器划分为局部区域和主干区域,每个路由器只需获取所在区域拓扑信息完成计算,每个局部区域都会通过主干区域互联
- 每个路由器获取邻居链路状态信息后,向所在区域中所有其他路由器洪泛该信息,构建区域内完整拓扑
- 各个路由器维护一个链路状态数据库(LSDB),存储整个区域结点与链路信息
- 使用 Dijkstra 算法计算最短路径,生成路由表
- IS-IS (Intermediate System to Intermediate System):
- 与OSPF本质一样,区别在于是ISO标准, 而OSPF是RFC标准
AS 间路由协议——BGP#
全球互联网由成千上万个自治系统组成,有上百万的AS路由器,规模巨大,进行LS或DV算法困难,开销巨大。 每个AS可以有自己的路由策略和管理方式,对于代价、延迟的定义可能也不一样
目前,互联网上唯一使用的自治系统间路由协议是边界网关协议 (BGP, Border Gateway Protocol),其整个功能分为两大部分:
- eBGP:从相邻的AS获得网络可达信息
- iBGP: 将网络可达信息传播给AS内的路由器
路由器可以基于网络可达信息和策略决定到其他网络的“最优”路由
AS边界的路由器,通常同时运行eBGP、iBGP、IGP(内部网关协议)三类路由协议
路径通告机制:
BGP通过TCP的179端口进行路径通告,在AS之间通告可达路径,表示己方AS内可以到达某处
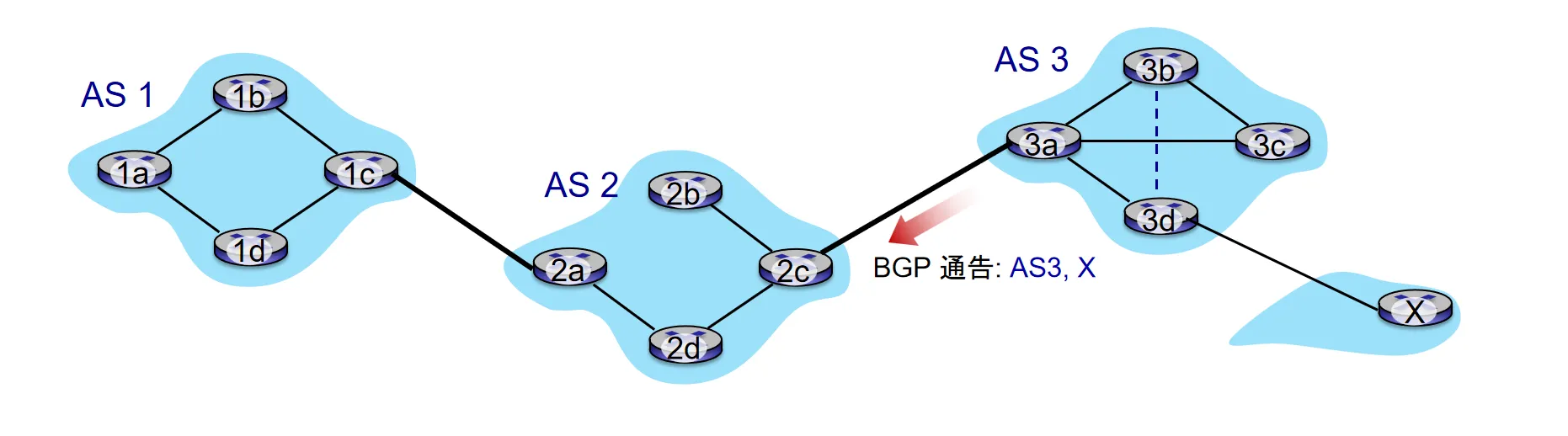 例:AS3的路由器3a向AS2的路由器2c通告路径“AS3, X” ,意味着“AS3向AS2承诺会转发通往X的数据包”
例:AS3的路由器3a向AS2的路由器2c通告路径“AS3, X” ,意味着“AS3向AS2承诺会转发通往X的数据包”
BGP报文包括
- Open报文:用于建立BGP对等体(peer)之间的会话连接,协商BGP参数(该过程需要认证)
- Update报文:通告/撤销路径
- Keepalive报文:用于保持BGP会话连接
- Notification报文:用于差错报告和关闭BGP连接
BGP 通告包括路径前缀(目的网络)及其属性。
- 关键属性:
AS-PATH:想要到达某个目的网络,需要经过的所有AS号NEXT-HOP:想要使用这条路径,对应的下一跳IP地址
接收到路径通告后,路由器会根据自身策略决定是否接受该路径,并决定用iBGP将该路径通告给本AS内的其他路由器
策略路由:
当到达同一目的地有多条路径时,BGP 按以下顺序选择:
- 本地偏好值属性:政策决策
- 最短的AS-PATH
- 最近的NEXT-HOP路由器
- 附加标准…
- 最低路由器ID
路由器使用策略决定接受或拒绝接收到的路由通告,也会基于策略决定是否向其他相邻AS通告路径信息
- 是否接受邻居告诉我的路由?
- 是否要把我知道的路由告诉邻居?(例如:ISP 不会把自己从一个客户学到的路由告诉另一个竞争对手 ISP)。
在AS内部,转发的外部报文的路由策略一般由AS自身决定,实际常用“热土豆策略”
- 选择最近的BGP出口,即最小化报文在本AS停留时间
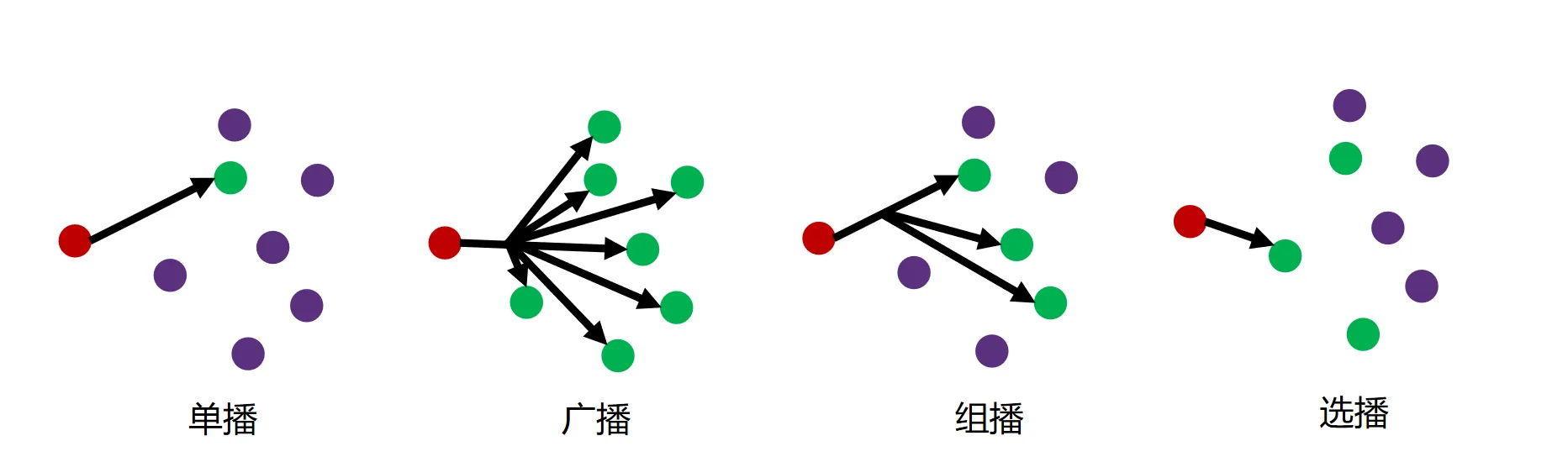
广播与组播路由#
上面我们已经了解了向单一目的地发送数据包的路由方法,接下来我们了解一下如果要向多个目的地发送数据包时,怎样去更好的设计路由
广播路由#
广播:源主机同时给全部目标地址发送同一个数据包
一些实现方法对比
- 给每一个主机发送一个数据包
- 效率低、浪费带宽
- Server需要知道每个目的地址
- 多目标路由(multi-destination routing):
- 在需要转发的路由器线路复制一次该数据报
- 网络利用率高
- Server依然需要知道所有的目的地址
- 泛洪 (Flooding):一种将数据包发送到所有网络节点的简单方法
- 将每个进入数据包发送到除了进入线路外的每条外出线路
- Server只需要知道自己的邻居
但是洪泛如果不加限制,会导致环路和广播风暴,占用带宽
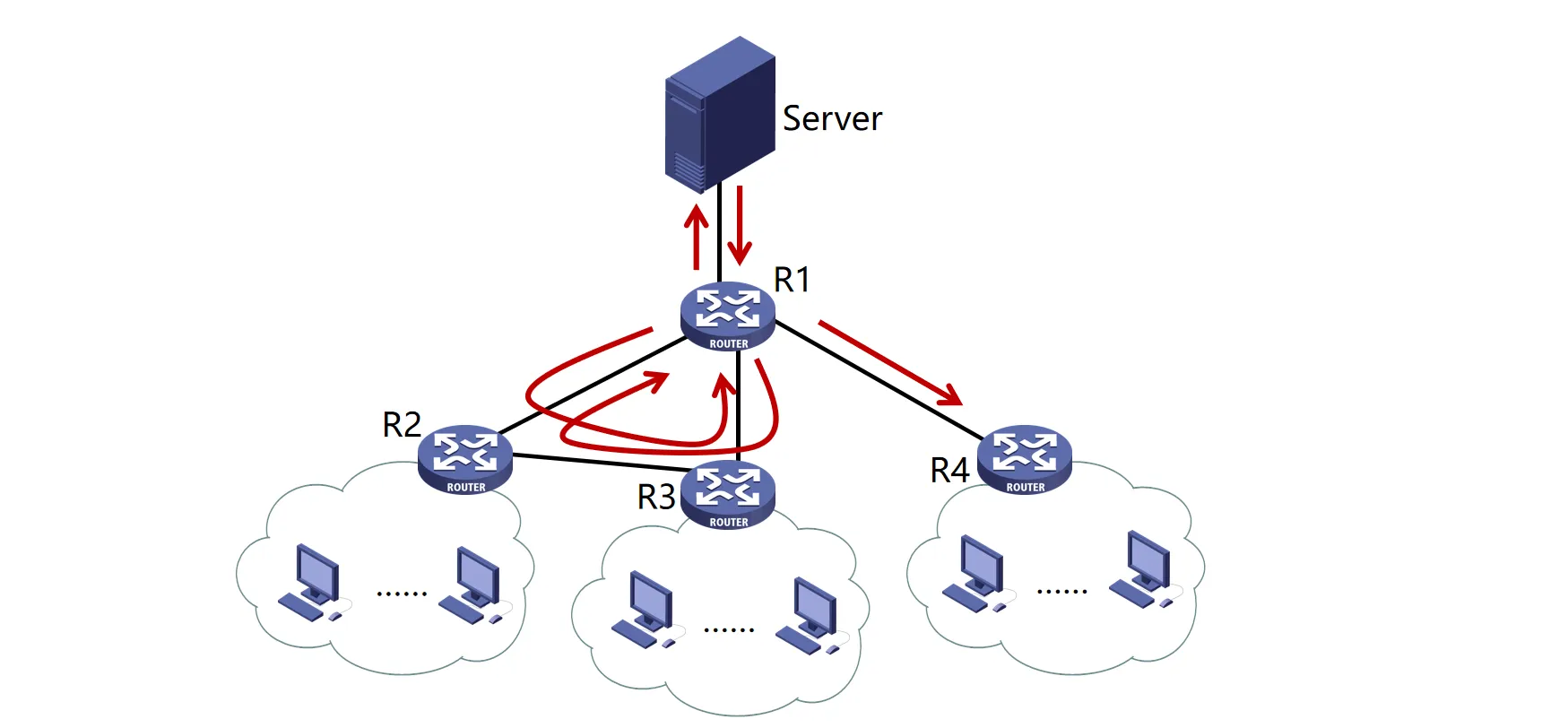 解决方案:
解决方案:
- 序号控制泛洪:
- 每个数据包带一个唯一序号,路由器记录转发的数据包的来源和序号
- 如果收到重复数据包则丢弃
- 如果数据包太多,路由器的存储开销会很大
- 逆向路径转发:
- 假设路由器R的路由表中表示了到达各网络的最优路径(路由算法计算出一棵最短路径树)
- 每当路由器R收到一个广播数据包时,R检查该数据包的到达接口和来源
- 如果数据包是从R到达源节点的最优路径上到达的,则认为是新报文,转发该数据包到其他接口,否则丢弃
- 生成树广播 (Spanning Tree):
- 源节点只在网络的一棵生成树上转发,消除环路和重复分组
- 路由器只需要知道自己在该生成树上的邻居即可
组播路由#
组播(多播):源主机给网络中的一部分目标用户发送数据包,非本组成员不应收到组播分组
组播步骤:
- 确定组成员:
- 组播在公网上确定一个公开的服务地址IP
- 主机通过 IGMP 协议加入或离开组播组
- 路由器也可以通过 IGMP 了解本地网络的组成员信息
- 生成树组播路由:
- 路由器根据组成员信息构建组播路由树
- 根据组播路由树转发数据包到各个组成员所在的子网
多个组播生成树方法:
- 源点树 (Source-based Tree):
- 为每个组播源单独建立一棵生成树
- 路由器需要大量空间来存储多颗树
- 核心树 (Group-shared Tree):
- 所有源节点共享同一棵树,树有一个核心(通常是性能较强的节点)
- 所有流量先汇聚到核心,再进行分发
- 可能不是最优路径
选播#
将数据包发送给一组主机中的任意一个(通常是最近的一个)
- 应用:DNS 服务器、CDN(内容分发网络)